目录
- 激活函数是什么
- Sigmoid 函数
- 双曲正切(Tanh)函数
- 线性整流单元(ReLU)
- Leaky ReLU
- 指数线性单元(ELU)
- Scaled Exponential Linear Unit(SELU)
- Swish 函数
- 高斯误差线性单元(GELU)
- Softmax 函数
- Softplus 函数
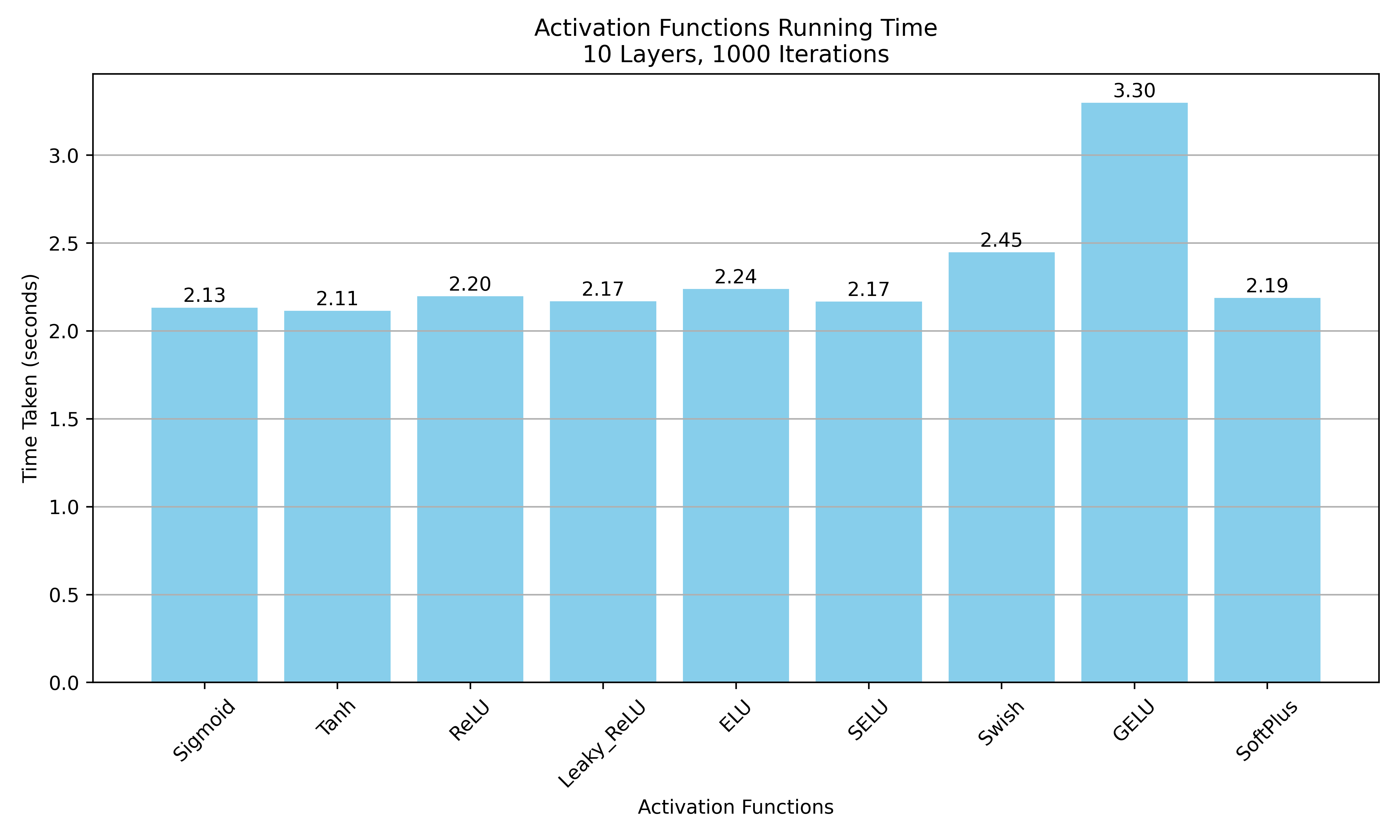
- 速度对比图
激活函数是什么
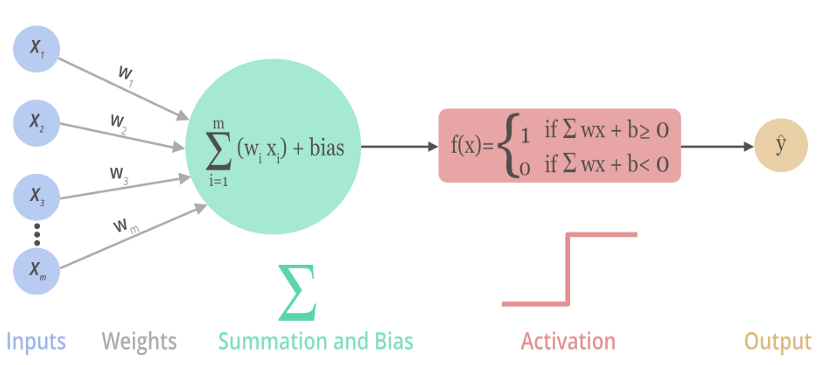
所谓激活函数,就是在人工神经网络的每一层工作的传递函数,负责将神经元的输入映射到输出端。如下图所示,神经网络对每一个神经元的输入加权求和并添加偏置。然后向前传递,但是如果直接向前传递,模型永远都只是线性的,无论网络多深,其表现力都等同于单层线性模型。激活函数为神经网络引入非线性,有了非线性,网络中的参数才能使结果去无限地逼近理想解,使其能够学习和表示复杂的数据分布。
同时,选择合适的激活函数对于网络的性能和收敛速度至关重要。
下面介绍几种比较热门常见的激活函数,并给出了一些博主本人的测试结果(最后会配上速度对比图):
速度测试基于cpu在pytorch测试:
使用网络参数为10层网络,每层100个神经元,输出维度10,迭代次数1000
Sigmoid 函数
Sigmoid 函数将输入映射到 (0, 1) 之间,公式如下:
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
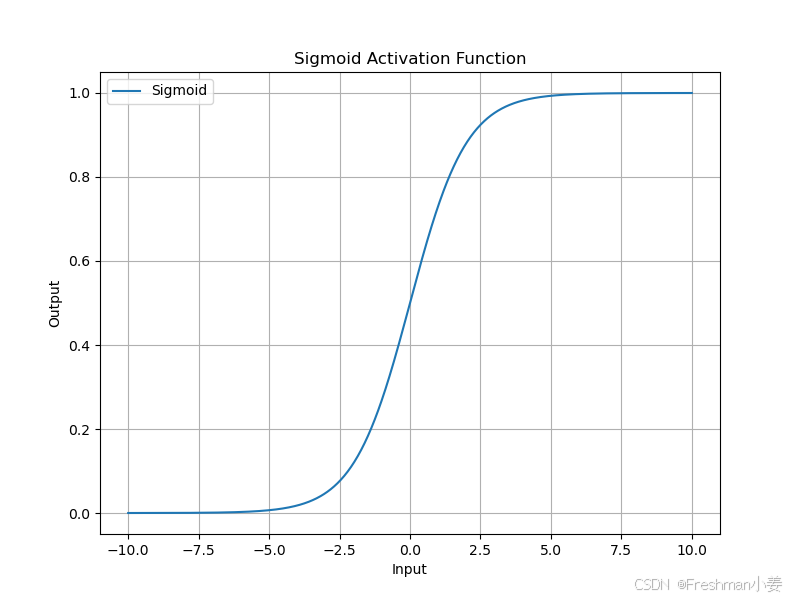
Sigmoid 激活函数在神经网络中具有重要的历史地位,特别适合用于二分类问题的输出层。然而,由于其梯度消失问题和计算复杂度较高,它在深层网络中的应用受到限制。
优缺点
优点:
1.平滑且可微:Sigmoid 函数是一个平滑的 S 型曲线,其输出在输入变化时能够平滑地变化,这使得在训练过程中使用优化算法时更加容易处理。其导数为 σ ′ (x)=σ(x)(1−σ(x)),在反向传播过程中可以高效地计算梯度。
2.输出范围:Sigmoid 函数的输出范围在 0 到 1 之间,这使得它特别适合用于二分类问题,输出可以被解释为概率。
3.历史意义:Sigmoid 函数在神经网络的早期发展中起到了重要作用,其 legacy 仍然可以在某些模型和架构中找到。
缺点:
1.梯度消失问题:当输入值较大或较小时,Sigmoid 函数的梯度接近 0,这会导致在反向传播过程中梯度逐渐消失,特别是在深层网络中,这会显著减慢学习速度,甚至导致训练停滞。
2.输出非零均值:Sigmoid 函数的输出总是正数,这会导致在梯度下降过程中更新效率低下,因为正负梯度不能相互抵消。
3.计算复杂度高:Sigmoid 函数涉及指数运算,计算成本较高,特别是在大规模数据集和复杂模型中,这会显著增加训练时间。
测试耗时:2.1326 seconds
Tanh 函数
Tanh 函数将输入映射到 (-1, 1) 之间,公式如下:
tanh ( x ) = e x − e − x e x + e − x \tanh(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}} tanh(x)=ex+e−xex−e−x
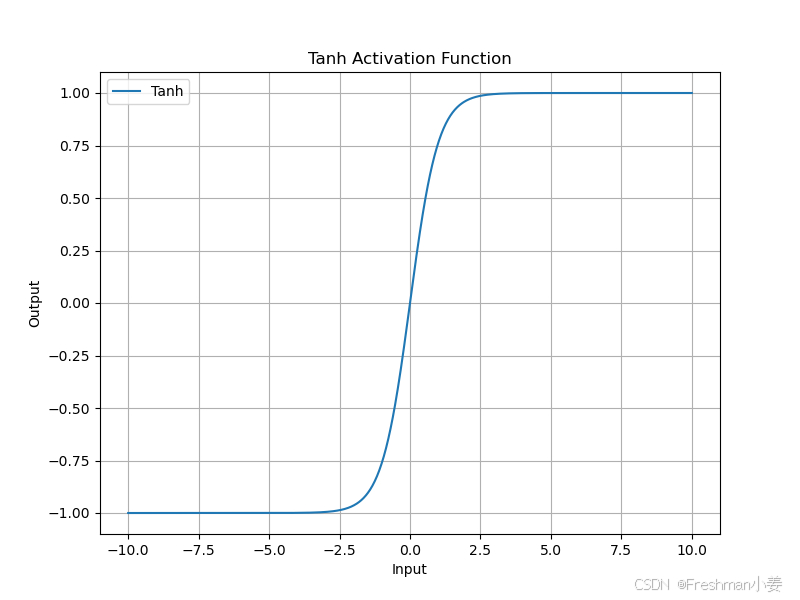
Tanh 激活函数在神经网络中具有重要的应用,特别适合用于隐藏层,能够提高训练效率和收敛速度。然而,由于其梯度消失问题和计算复杂度较高,它在深层网络中的应用受到限制。
优缺点
优点:
- 输出范围为 ([-1, 1]):
- 零均值:Tanh 函数的输出范围在 ([-1, 1]) 之间,且均值为 0。这使得在梯度下降过程中,正负梯度可以相互抵消,从而提高训练效率。
- 更好的收敛性:与 Sigmoid 函数相比,Tanh 函数的输出范围更宽,能够更好地处理输入数据的动态范围,有助于网络更快地收敛。
- 平滑且可微:
- 平滑曲线:Tanh 函数是一个平滑的 S 型曲线,其输出在输入变化时能够平滑地变化,这使得在训练过程中使用优化算法时更加容易处理。
- 导数计算简单:Tanh 函数的导数为 (\tanh’(x) = 1 - \tanh^2(x)),在反向传播过程中可以高效地计算梯度。
缺点:
- 仍存在梯度消失问题,尤其是在深层网络中。
- 计算相对复杂。
测试耗时:2.1140 seconds
线性整流单元(ReLU)
定义
ReLU 函数将输入小于零的部分置为零,其他部分保持不变,公式如下:
ReLU ( x ) = max ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)
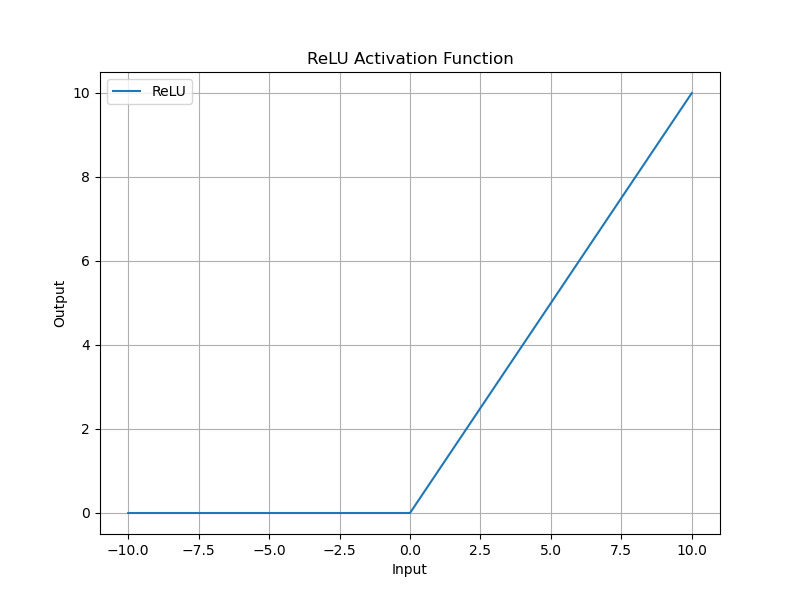
ReLU 激活函数在深度神经网络中具有重要的应用,特别适合用于隐藏层,能够提高训练效率和收敛速度。然而,由于其神经元死亡问题和输出非零均值的缺点,它在某些情况下可能需要结合其他技术和变体来优化性能。
优缺点
优点:
-
计算简单高效:
- 简单运算:ReLU 函数的计算非常简单,仅需进行一次阈值判断,计算复杂度低,适合大规模数据集和复杂模型。
- 加速训练:由于计算简单,ReLU 函数可以显著减少训练时间,提高训练效率。
-
解决梯度消失问题:
- 梯度恒为 1:当输入 ( x > 0 ) 时,ReLU 的梯度始终为 1,避免了梯度消失问题,使得深层网络的训练更加高效。
- 加速收敛:ReLU 函数的线性特性使得梯度在反向传播过程中不会逐渐减小,从而加速了网络的收敛速度。
-
稀疏激活:
- 减少过拟合:ReLU 函数将输入中小于 0 的部分置为 0,使得网络中的部分神经元不被激活,这种稀疏性有助于减少模型的复杂度,提高模型的泛化能力。
- 提高效率:稀疏激活特性可以减少计算量,提高训练和推理的效率。
-
生物学合理性:
- 单侧抑制:ReLU 函数的单侧抑制特性与生物神经网络中的某些特性相似,具有一定的生物学合理性。
缺点:
-
神经元死亡问题:
- 永久失活:当输入总是小于 0 时,ReLU 的梯度为 0,导致这些神经元可能永远不会被激活,称为“死亡神经元”问题。
-
输出非零均值:
- 偏置偏移:ReLU 函数的输出是非零中心化的,这会给后一层的神经网络引入偏置偏移,影响梯度下降的效率。
-
对噪声数据敏感:
- 异常值影响:ReLU 函数对噪声数据或异常值较敏感,可能导致模型性能下降。
Leaky ReLU
定义
Leaky ReLU 通过在输入小于零时赋予一个小的斜率,避免神经元完全死亡,公式如下:
LeakyReLU ( x ) = { x if x ≥ 0 α x otherwise \text{LeakyReLU}(x) = \begin{cases} x & \text{if } x \geq 0 \\ \alpha x & \text{otherwise} \end{cases} LeakyReLU(x)={ xαxif x≥0otherwise
通常, α = 0.01 \alpha = 0.01 α=0.01。
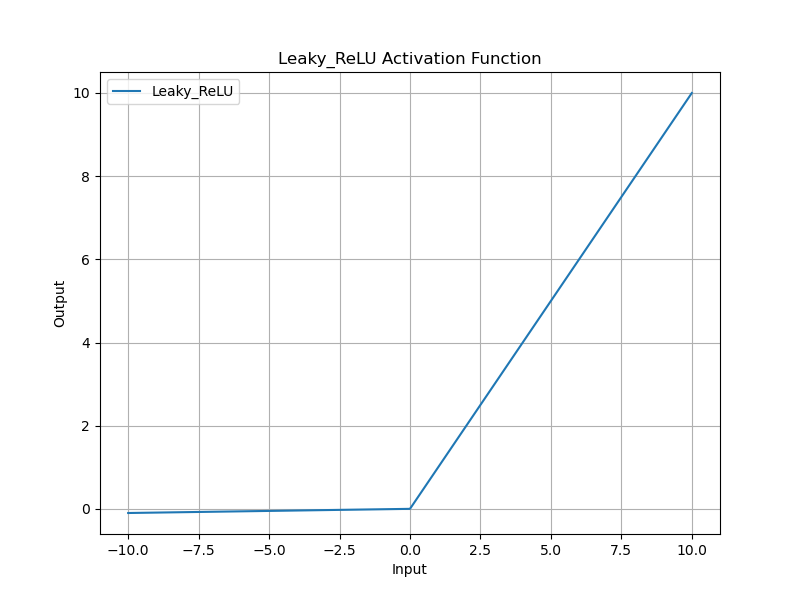
Leaky ReLU 通过引入一个小的斜率解决了 ReLU 的“死亡神经元”问题,使得负输入也能产生非零输出。它在许多深度学习任务中表现良好,特别是在处理负输入时。
优缺点
优点:
-
避免神经元死亡问题:
- 非零梯度:Leaky ReLU 在输入为负值时引入了一个很小的负斜率 (\alpha),使得即使输入为负值,神经元也能产生非零输出,避免了 ReLU 的“死亡神经元”问题。
- 持续学习:这种特性使得神经元在训练过程中不会永久失活,能够继续学习和更新权重。
-
保持非线性:
- 非线性特性:Leaky ReLU 仍然是一个非线性函数,能够捕捉到输入数据的复杂关系,增强模型的表达能力。
-
计算效率高:
- 简单计算:Leaky ReLU 的计算方式与 ReLU 类似,只需要进行一次比较操作和一次乘法操作,计算效率较高。
- 快速收敛:Leaky ReLU 的连续性和引入的小斜率有助于提高梯度下降等优化算法的收敛性,使得模型能够更快地收敛。
-
更好的泛化能力:
- 增强表达能力:Leaky ReLU 能够引入非零输出,增强模型的表达能力和泛化能力,对于一些复杂的任务具有更好的建模能力。
缺点:
- 引入额外的超参数(负斜率 α \alpha α)。
- 在某些情况下,可能不如ReLU效果好。
指数线性单元(ELU)
定义
ELU 在输入小于零时采用指数函数,公式如下:
ELU ( x ) = { x if x ≥ 0 α ( e x − 1 ) otherwise \text{ELU}(x) = \begin{cases} x & \text{if } x \geq 0 \\ \alpha (e^{x} - 1) & \text{otherwise} \end{cases} ELU(x)={ xα(ex−1)if x≥0otherwise
通常, α = 1.0 \alpha = 1.0 α=1.0。

ELU 是一种改进的激活函数,通过指数形式的负值区间克服了 ReLU 的缺点,特别是死亡神经元问题。它在深度网络中表现出色,尤其是在需要减小数据偏移或提升稳定性时,是一个有效的选择。
优缺点
优点:
-
解决梯度消失问题:
- 负值平滑处理:ELU 对负值进行指数平滑处理,而不是像 ReLU 那样将其直接设为零。这有助于减少梯度消失的风险,使得网络更容易收敛。
- 更快收敛:ELU 在负值区域的平滑处理能够帮助网络更快地收敛,因为它在负值区域也能传递梯度。
-
输出均值接近零:
- 零均值中心化:ELU 的输出值更接近于零均值,这有助于加速神经网络的训练过程,减少偏移偏移现象。
- 增强表达能力:ELU 的负值部分逐渐趋于一个有限值 (- α \alpha α),不会像 ReLU 那样直接将负值置零,避免神经元完全不激活的问题。
-
增强网络的鲁棒性:
- 平滑特性:ELU 的负值区间使得网络可以更好地学习复杂数据的非线性特征,增强模型的鲁棒性和泛化能力。
- 连续可导:ELU 是在其整个定义域内连续可导的,这有助于优化算法的稳定性和效率。
缺点:
- 计算复杂度较高:
- 指数运算:ELU 在负值时涉及指数运算,计算成本高于 ReLU 及其直接变体,尤其是在前向传播时。
- 训练速度稍慢:由于计算复杂度较高,ELU 可能会导致训练速度变慢,需要权衡计算效率和模型性能之间的关系。
Scaled Exponential Linear Unit(SELU)
定义
SELU 是一种自归一化激活函数,能够自动将输入归一化,公式如下:
SELU ( x ) = λ { x if x ≥ 0 α ( e x − 1 ) otherwise \text{SELU}(x) = \lambda \begin{cases} x & \text{if } x \geq 0 \\ \alpha (e^{x} - 1) & \text{otherwise} \end{cases} SELU(x)=λ{ xα(ex−1)if x≥0otherwise
其中, λ ≈ 1.0507 \lambda \approx 1.0507 λ≈1.0507, α ≈ 1.6733 \alpha \approx 1.6733 α≈1.6733。
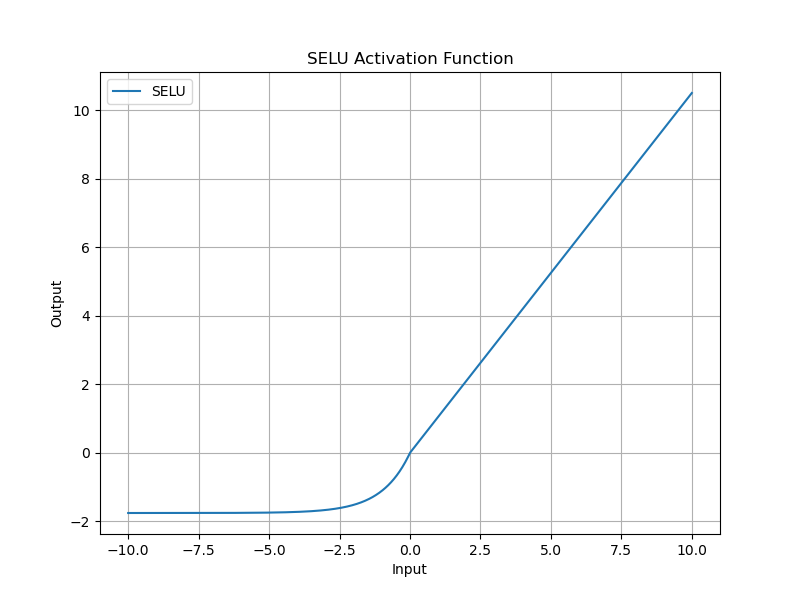
SELU 是一种强大的激活函数,特别适用于自归一化神经网络(SNNs),能够通过其自归一化特性显著提高模型的训练效率和性能。然而,SELU 的成功依赖于特定的初始化方法和输入数据的标准化处理,计算成本也较高。在设计神经网络时,需要根据具体任务需求权衡选择。
优缺点
优点:
-
自归一化特性:
- 保持均值和方差稳定:SELU 激活函数能够使网络的输出在训练过程中保持均值接近于 0,方差接近于 1,从而避免梯度消失和梯度爆炸问题。
- 加速收敛:这种自归一化特性有助于加速网络的收敛速度,特别是在深层网络中表现更佳。
-
解决梯度问题:
- 避免梯度消失和爆炸:SELU 通过其自归一化性质,能够有效解决梯度消失和梯度爆炸的问题,这对于深层神经网络的训练非常重要。
-
连续可导:
- 优化算法稳定:SELU 在整个定义域内连续可导,有利于优化算法的稳定性和效率。
缺点:
-
条件限制:
- 特定初始化方法:SELU 的自归一化属性依赖于特定的初始化方法(如 LeCun 正态分布初始化)和网络结构(如顺序模型),在某些复杂模型结构中可能不适用或效果不明显。
- 输入数据标准化:输入数据需要进行标准化处理,以确保其自归一化特性得到充分发挥。
-
计算成本:
- 指数运算:SELU 在处理负值输入时涉及指数运算,因此计算成本较高。
Swish 函数
定义
Swish 函数是一个自门控的激活函数,公式如下:
Swish ( x ) = x ⋅ σ ( x ) \text{Swish}(x) = x \cdot \sigma(x) Swish(x)=x⋅σ(x)
其中, σ ( x ) \sigma(x) σ(x) 是 Sigmoid 函数。
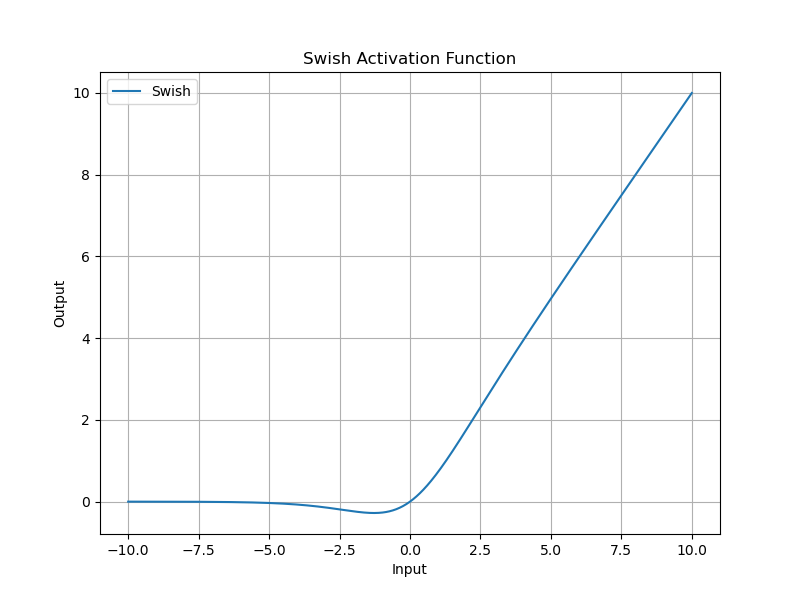
Swish 激活函数通过其独特的自适应门控机制和连续可导性,在保持了 ReLU 优点的同时,克服了其不足之处。虽然 Swish 尚未成为激活函数中的绝对主流,但它已经在许多研究工作中展示了其潜力。
优缺点
优点:
-
缓解梯度消失问题:
- 较大梯度:Swish 函数在正向传播过程中能够产生较大的梯度,有助于缓解梯度消失问题,从而提高模型的训练效率。
-
非单调性:
- 提升表达能力:Swish 函数具有非单调性,这意味着它在某些区间内能够提升模型的表达能力,有助于提高模型的性能。
-
平滑性:
- 平滑插值:Swish 函数在输入值较大时接近线性函数,这使得它在神经网络中能够平滑地插值于线性函数和 ReLU 函数之间,从而提高模型的泛化能力。
-
自门控机制:
- 信息流动:Swish 函数的形式可以看作是一种自门控机制,有助于信息流动,特别是在输入值较小时,Swish 能够过滤部分信息,起到一定的正则化作用。
-
性能提升:
- 实验验证:实验表明,使用 Swish 激活函数的深度学习模型在一些任务中能得到更好的性能,特别是在很深的网络中。
缺点:
-
计算复杂度:
- 指数运算:Swish 函数涉及 Sigmoid 函数的计算,计算成本高于 ReLU,可能会略微增加训练时间。
-
非稀疏激活:
- 依赖稀疏性:Swish 不像 ReLU 那样产生稀疏激活,这在某些依赖于稀疏性的任务或模型中,可能不如 ReLU 表现得那么好。
高斯误差线性单元(GELU)
定义
GELU 函数结合了线性和高斯分布的特点,公式如下:
GELU ( x ) = x ⋅ Φ ( x ) \text{GELU}(x) = x \cdot \Phi(x) GELU(x)=x⋅Φ(x)
其中, Φ ( x ) \Phi(x) Φ(x) 是标准正态分布的累积分布函数,近似为:
GELU ( x ) ≈ 0.5 x ( 1 + tanh ( 2 π ( x + 0.044715 x 3 ) ) ) \text{GELU}(x) \approx 0.5x \left(1 + \tanh\left(\sqrt{\frac{2}{\pi}} \left(x + 0.044715x^3\right)\right)\right) GELU(x)≈0.5x(1+tanh(π2(x+0.044715x3)))
GELU 激活函数通过其平滑的梯度和对数据分布的适应性,在深度学习模型中表现出色,特别是在大型预训练模型中。尽管存在计算复杂度高和初始化敏感性等缺点,但其在 Transformer 和自然语言处理任务中的优势往往超过这些挑战。
优缺点
优点:
-
更平滑的梯度:
- GELU 函数的导数始终大于 0,并且随着输入 ( x ) 的增加,导数逐渐从 0 平滑地增加到 1。这种特性有助于模型在训练过程中保持稳定的梯度,避免梯度消失和梯度爆炸问题。
-
更好地拟合数据分布:
- GELU 函数通过引入高斯误差函数,能够更好地拟合数据的分布,特别是在处理具有高斯特性的数据时,GELU 表现尤为出色。
-
参数调节灵活性:
- GELU 函数具有一个可调节的参数(通常为 1.702),这使得用户可以根据具体任务和数据特性调整函数的形状,从而优化模型的性能。
-
减少过拟合:
- GELU 的随机性和对输入分布的适应性有助于减轻过拟合现象,使得模型在处理复杂任务时表现更好。
-
近似恒等变换:
- 当输入值接近于 0 时,GELU 函数的输出值近似于输入值,实现了近似的恒等变换。这对于一些需要保持信息完整性的任务非常有用,如残差连接和标准化操作。
-
快速计算:
- 相较于一些复杂的激活函数(如 Swish 函数),GELU 函数的计算相对简单,能够高效地进行前向传播和反向传播计算。这有助于提升模型的训练速度和效率。
缺点:
-
计算复杂度高:
- GELU 函数不像 ReLU 那样易于计算,因为它不是简单的阈值函数。为了计算 GELU,可以直接使用公式,但该公式涉及到误差函数(erf),在某些计算平台或硬件上可能没有直接的硬件支持,导致计算相对复杂和耗时。为此,常常需要使用近似方法来提高计算效率。
-
近似误差:
- 在实际应用中,由于 erf 函数的复杂性,通常会使用近似公式替代,这可能导致某种程度上的精度损失。尽管这种损失在大多数情况下影响不大,但在极端情况下可能会有一定的影响。
-
初始化敏感性:
- GELU 相对于 ReLU 等函数可能对模型权重的初始值更为敏感,不当的初始化可能会导致训练初期梯度消失或爆炸的问题。
-
理解和调试难度:
- 由于 GELU 函数的复杂性,对于开发者和研究者来说,理解和调试网络中使用 GELU 的地方可能比使用简单函数(如 ReLU)更具挑战性。
Softmax 函数
定义
Softmax 函数将输入向量转换为概率分布,公式如下:
Softmax ( x i ) = e x i ∑ j e x j \text{Softmax}(x_i) = \frac{e^{x_i}}{\sum_{j} e^{x_j}} Softmax(xi)=∑jexjexi
Softmax 激活函数通过其输出概率分布的特性,在多分类问题中表现出色,是多分类任务的自然选择。尽管存在计算复杂度较高和数值稳定性问题,但通过一些数值稳定性处理,这些问题可以得到有效解决。Softmax 函数在多分类、概率建模和强化学习等任务中具有广泛的应用,是深度学习中不可或缺的激活函数之一。
优缺点
优点:
-
输出概率分布:
- Softmax 函数将输入值转换为概率分布,输出值在 0 到 1 之间,并且所有输出值的和为 1。这使得 Softmax 特别适合用于多分类问题的输出层,输出可以被解释为各个类别的概率。
-
平滑且可微:
- Softmax 函数是一个平滑的函数,其导数可以高效地计算,这使得在反向传播过程中可以顺利地进行梯度更新。
-
多分类问题的自然选择:
- 在多分类问题中,Softmax 函数能够自然地处理多个类别的竞争关系,输出每个类别的概率,便于进行分类决策。
-
与交叉熵损失函数兼容:
- Softmax 函数与交叉熵损失函数结合使用时,能够提供高效的梯度计算,使得模型在训练过程中能够快速收敛。
缺点:
缺点
-
计算复杂度较高:
- Softmax 函数需要计算每个输入值的指数,然后进行归一化处理,计算成本相对较高,特别是在输入维度较大时。
-
数值稳定性问题:
- 由于 Softmax 函数涉及指数运算,当输入值较大时,可能会导致数值溢出问题。为了解决这个问题,通常需要进行一些数值稳定性处理,如减去输入值的最大值。
-
输出概率分布的局限性:
- Softmax 函数输出的是相对概率,而不是绝对概率。这意味着输出值的大小受到输入值的相对大小影响,而不是绝对大小。这在某些情况下可能会导致模型的解释性较差。
Softplus
Softplus ( x ) = log ( 1 + e x ) \text{Softplus}(x) = \log(1 + e^x) Softplus(x)=log(1+ex)

Softplus 激活函数通过其平滑的梯度和对数据分布的适应性,在深度学习模型中表现出色,特别是在需要平滑激活和非负输出的场景中。尽管存在计算复杂度较高和数值稳定性问题,但通过一些数值稳定性处理,这些问题可以得到有效解决
优缺点
优点:
-
平滑近似:
-
Softplus 函数是 ReLU 函数的平滑近似,避免了 ReLU 在负区间的“死亡”问题(即神经元输出恒为零)。
-
Softplus 函数在整个范围内都是可导的,这使得它在反向传播过程中能够提供稳定的梯度。
-
-
渐进线性:
- 当输入值较大时,Softplus 函数的输出近似于线性,这有助于保持模型的表达能力。具体来说,当 ( x ) 很大时,( e^x ) 远大于 1,因此:
-
输出范围:
- Softplus 函数的输出范围为 ([0, \infty)),这使得它在处理正值时表现良好。
-
数值稳定性:
- 为了数值稳定性,当输入值 ( x ) 很大时,Softplus 函数可以近似为线性函数,避免了数值溢出问题。具体来说,当 ( x ) 超过某个阈值(如 20)时,可以近似为:
Softplus ( x ) ≈ x \text{Softplus}(x) \approx x Softplus(x)≈x
- 为了数值稳定性,当输入值 ( x ) 很大时,Softplus 函数可以近似为线性函数,避免了数值溢出问题。具体来说,当 ( x ) 超过某个阈值(如 20)时,可以近似为:
-
平滑性:
- Softplus 函数在整个范围内都是平滑的,这使得它在反向传播过程中能够提供稳定的梯度。
缺点:
-
计算复杂度:
- 直接计算 Softplus 函数涉及到指数和对数运算,这在硬件实现中可能会导致较高的延迟。
-
数值稳定性问题:
- 由于 Softplus 函数涉及指数运算,当输入值较大时,可能会导致数值溢出问题。为了解决这个问题,通常需要进行一些数值稳定性处理,如减去输入值的最大值。
-
计算成本:
- Softplus 函数的计算成本相对较高,特别是在输入维度较大时。
End
激活函数在神经网络中扮演着至关重要的角色,不同的激活函数适用于不同的场景和任务。从早期的Sigmoid和Tanh到如今广泛使用的ReLU及其变种,如Leaky ReLU、ELU、SELU,再到更先进的Swish和GELU,每种激活函数都有其独特的优点和适用场景。选择合适的激活函数可以显著提升模型的性能和训练效率。在实际应用中,通常需要通过实验和验证来确定最适合特定任务的激活函数。
最后附上激活函数速度对比,当然这只是一个简单参考,:
速度对比图