DeepSeek开源的DeepEP(Deep Expert Parallelism):MoE模型的通信加速利器
引言
蹭热度,在人工智能领域,模型的训练和推理效率一直是研究者和开发者关注的重点。DeepSeek开源的DeepEP通信库,为Mixture of Experts(MoE)模型的训练和推理带来了革命性的加速。本文将深入浅出地介绍DeepEP的核心功能、技术亮点以及实际应用价值。
DeepEP简介
DeepEP是由DeepSeek开源的高性能通信库,专为MoE模型的训练和推理设计。MoE模型通过多个专家网络的协作来提高模型的性能和灵活性,但这也带来了通信和计算的挑战。DeepEP通过优化GPU间的数据传输和计算流程,显著提升了MoE模型的训练和推理效率。
核心功能与技术亮点
1. 高效优化的All-to-All通信
- 传送门链接: All-to-All 通信:原理、实现与应用
在MoE模型中,不同专家之间需要频繁交换信息,DeepEP通过高效的All-to-All通信机制,实现了GPU之间的高效数据传输。这种通信机制不仅减少了数据传输的瓶颈,还提高了多GPU协作的效率。
2. 支持NVLink和RDMA的节点内/跨节点通信
- 传送门链接: NVLink 与 RDMA:高性能计算的左右护法
DeepEP支持NVLink和RDMA两种通信协议,分别用于节点内和跨节点的GPU通信。NVLink提供了高达160 GB/s的带宽,而RDMA则提供了50 GB/s的带宽。通过定制内核实现数据转发路径优化,DeepEP避免了带宽浪费,提高了通信效率。
3. 训练及推理预填充阶段的高吞吐量计算核心
在训练和推理的预填充阶段,DeepEP提供了高吞吐量的计算核心,能够快速处理大量数据。这种高吞吐量的核心设计,使得DeepEP在处理大规模数据时表现出色。
4. 推理解码阶段的低延迟计算核心
对于实时性要求较高的推理解码任务,DeepEP提供了低延迟的计算核心。通过纯RDMA传输和双缓冲机制,DeepEP实现了163微秒的端到端延迟,展现了极强的扩展性。
5. 原生支持FP8数据分发
DeepEP原生支持FP8数据分发,通过FP8分发和BF16合并的方式,在保证精度的同时减少了50%的显存占用。这种低精度计算支持,使得DeepEP在资源利用上更加高效。
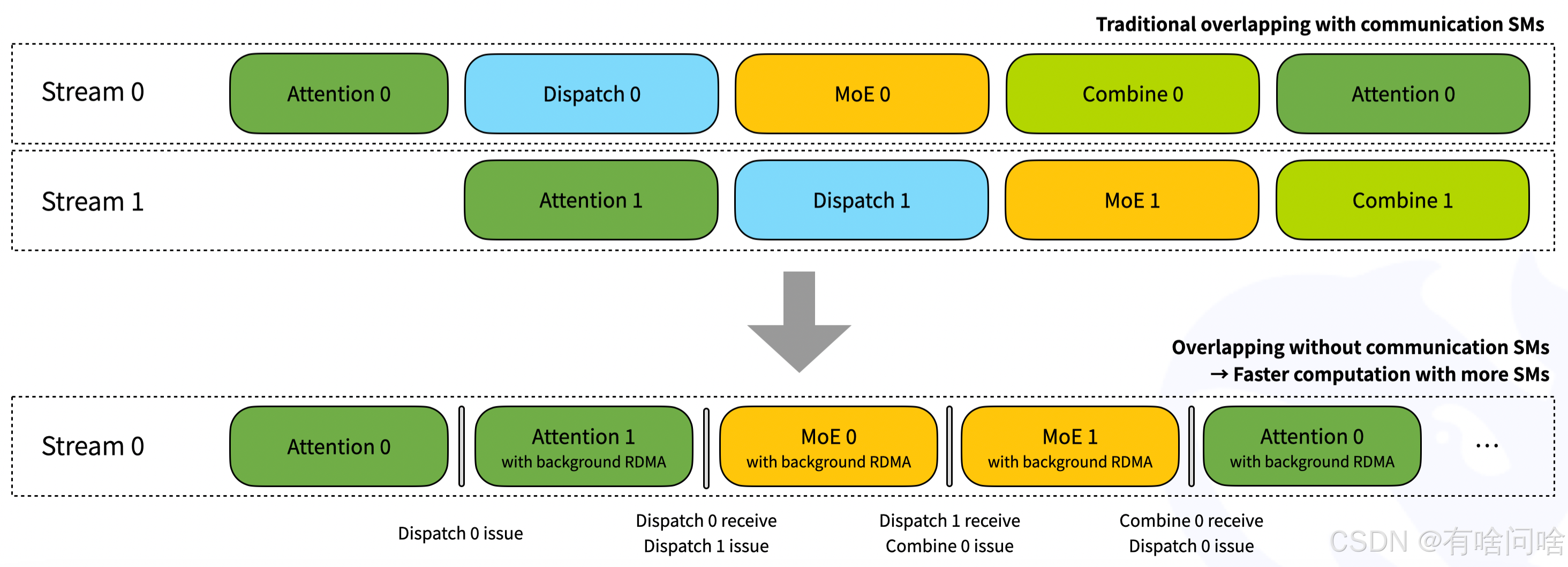
6. 灵活控制GPU资源,实现计算与通信的高效重叠
- 传送门链接: Hook机制:DeepEP中实现计算与通信的高效重叠
DeepEP通过Hook机制实现了计算与通信的高效重叠。在前向传播时,后台可以预加载数据;在反向传播时,可以异步传输梯度。这种设计使得DeepEP在计算和通信资源的利用上更加灵活,最大化了GPU的利用率。
性能实测
在性能测试中,DeepEP展现出了卓越的表现。在节点内(8卡)的NVLink通信中,吞吐量达到了153 GB/s;在跨节点(64卡)的RDMA通信中,吞吐量达到了46 GB/s。在低延迟模式下,DeepEP的延迟仅为163微秒,展现了极强的扩展性。
应用场景
DeepEP适用于多种应用场景,包括大规模模型训练、实时推理等。在大规模模型训练中,DeepEP通过高效的通信机制和计算核心,显著提升了训练效率。在实时推理中,DeepEP的低延迟计算核心和高效通信机制,使得模型能够快速响应用户需求。
结论
DeepEP作为DeepSeek开源的高性能通信库,为MoE模型的训练和推理带来了革命性的加速。通过高效的通信机制、高吞吐量和低延迟的计算核心,以及灵活的资源调度,DeepEP显著提升了MoE模型的性能和效率。未来,DeepEP有望在更多的人工智能应用中发挥重要作用。
参考链接
DeepEP GitHub链接:https://github.com/deepseek-ai/DeepEP