1.基本情况
论文:Real-time Scene Text Detection with Differentiable Binarization (opens new window)
代码:DB (opens new window)
基于分割的文本检测方法对分割结果的概率图进行二值化后处理,然后来提取文本区域,可以检测任意形状的文本区域。但基于分割的文本检测算法一般都需要复杂的后处理,影响推理的性能。

上图中,蓝色的路径表示传统的基于分割的文本检测,完整流程包括得到分割概率图,使用阈值二值化,然后通过像素聚类等手段得到最终的文本检测结果,红色路径是作者提出的新的方法,同时输出分割概率图和进行二值化使用的阈值图,之后使用一个可微分的二值化操作求得二值化的图像,其中虚线表示操作只发生在预测阶段,实线表示在训练和预测阶段都会发生。阅读源码可以发现,与上图中描述不同,训练阶段的二值化结果是通过可微分的二值化操作得到的,预测阶段的二值化结果仍然使用的是固定阈值来计算的。
在这篇论文中,作者主要的创新点就是提出了可微分二值化运算(Differentiable Binarization, DB),DB的引入使得在训练时可以将二值化操作放入模型中,从而实现模型的端到端训练,简化后处理,加快运算速度。
2.主要工作
2.1 模型架构

从上图中可以看到网络使用了全卷积结构,将多个尺度的特征图使用FPN直接进行融合,经过上采样得到同样大小的特征图进行concatenate拼接,经过两个分支,一个输出分割概率图,一个输出阈值图,使用这两个结果,输入到DB运算中得到近似二值图,对二值图处理得到文本区域。
2.2 二值化
记backbone提取的特征图为,表示分割结果的概率图为,阈值图为,通过和计算得到的阈值图为。
标准二值化:给定表示分割结果的概率图,表示图的高/宽,标准二值化操作可表示成:
上式中是预定义的阈值,表示的图中像素的坐标。
可微分二值化:从公式可以看出标准二值化是不可微的,因此使用标准二值化在网络的训练中不能直接对其进行优化。作者提出了可微分二值化运算:
是近似二值化的值,是网络学习得到的自适应阈值,是放大系数,取一个经验值为。

上图(a)中表示的是标准二值化和可微分二值化的曲线图,可以看到二者由几乎一样的取值。
为什么可微分二值化有助于网络的学习呢?
定义,则可微二值化运算可表示为,对于可微二值化的输出使用二分类交叉熵损失函数:前半部分是正样本的损失,后半部分是负样本的损失,则可微分二值化运算输出的正负样本的损失为:
对分别求梯度为:
上图中(b)和©分别表示和的导数,从导数表达式中可以看出梯度被放大了倍,特别是对类别预测错误的样本和梯度放大作用更明显,这样可以使模型产生更有区分度的预测结果。
2.3 自适应阈值
从上面的介绍中可看到自适应阈值图和文本边框有些相似,但自适应阈值图通过有监督或无监督的训练都能获得。

上图中(a)原图,(b)是分割结果的概率图,©是无监督得到的阈值图,(d)是有监督训练得到的阈值图
2.4 标签生成

文本的阈值图中的边框不应该是文本的一部分,在进行网络训练之前需先将文本标签轮廓进行扩展,扩展的距离通过以下公式计算:
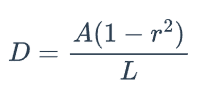
是缩放的比率,经验值取0.4,是原始文本区域多边形面积,是轮廓周长,D是扩展距离。源代码中对文本检测区域的处理使用的pyclipper.PyclipperOffset(),具体可参考 (opens new window)。
因为训练时对标签的处理,在推理时还需要将扩展的部分缩减掉。
2.5 模型优化
总的损失函数表示为:
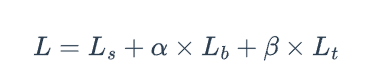
其中, L s L_s Ls是分割概率图对应的损失, L b L_b Lb二值化图对应的损失, L t L_t Lt是阈值图对应的损失,
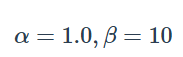
对于概率图和二值化图使用的是二分类交叉熵损失函数:
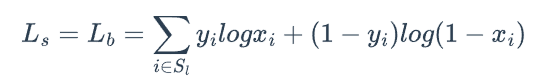
其中是为应对不平衡问题使用Hard Negative Mining算法得到的采样样本,正负样本比例为 1 : 3 1:3 1:3。
使用距离来计算:

R d R_d Rd是扩充之后文本区域的像素坐标, y i x y_i^x yix是阈值图的标签。
3.源码
第一部分介绍时提到,DB只应用在训练时,推理时使用的还是常规的固定阈值二值化方法,从模型的forward函数可以看到:
decoders/seg_detector.py
class SegDetector(nn.Module):
...
def forward(self, features, gt=None, masks=None, training=False):
c2, c3, c4, c5 = features
in5 = self.in5(c5)
in4 = self.in4(c4)
in3 = self.in3(c3)
in2 = self.in2(c2)
out4 = self.up5(in5) + in4 # 1/16
out3 = self.up4(out4) + in3 # 1/8
out2 = self.up3(out3) + in2 # 1/4
p5 = self.out5(in5)
p4 = self.out4(out4)
p3 = self.out3(out3)
p2 = self.out2(out2)
fuse = torch.cat((p5, p4, p3, p2), 1)
# this is the pred module, not binarization module;
# We do not correct the name due to the trained model.
binary = self.binarize(fuse)
if self.training:
result = OrderedDict(binary=binary)
else:
return binary
if self.adaptive and self.training:
if self.serial:
fuse = torch.cat(
(fuse, nn.functional.interpolate(
binary, fuse.shape[2:])), 1)
thresh = self.thresh(fuse)
thresh_binary = self.step_function(binary, thresh)
result.update(thresh=thresh, thresh_binary=thresh_binary)
return result
def step_function(self, x, y):
return torch.reciprocal(1 + torch.exp(-self.k * (x - y)))