
背景信息
EMR Serverless Spark 是一款面向 Data+AI 的高性能 Lakehouse 产品。它为企业提供了一站式的数据平台服务,包括任务开发、调试、调度和运维等,极大地简化了数据处理和模型训练的全流程。同时,它100%兼容开源 Spark 生态,能够无缝集成到客户现有的数据平台。使用 EMR Serverless Spark,企业可以更专注于数据处理分析和模型训练调优,提高工作效率。
Apache Doris是一个高性能、实时的分析型数据库,能够较好地满足报表分析、即席查询、数据湖联邦查询加速等使用场景。更多信息,请参见Apache Doris 简介。
基于Apache Doris官方提供的Spark Connector,EMR Serverless Spark可以在开发时添加对应的配置来连接Doris。通过结合Apache Doris与EMR Serverless Spark,您可以高效地进行数据读取、写入和分析操作,从而实现端到端的数据处理流程。
EMR Serverless Spark 新用户可 免费领取 1000 CU*小时 资源包,欢迎体验。
前提条件
-
已创建Serverless Spark工作空间,详情请参见创建工作空间。
-
已创建Doris集群。
如果是在EMR on ECS创建包含Doris服务的数据分析(OLAP)集群,详情请参见创建集群。本文以在EMR on ECS创建包含Doris服务的集群为例,后续简称EMR Doris集群。

使用限制
EMR Serverless Spark引擎的版本要求为esr-2.5.0、esr-3.1.0、esr-4.1.0及以上版本。
操作流程
步骤一:获取Doris Spark Connector JAR并上传至OSS
您需要查阅Doris的官方文档 Spark Doris Connector。该文档通常会列出不同版本的连接器与不同版本的 Spark 引擎的兼容情况。您需要确认您正在使用的 Spark 版本与 Doris Spark Connector 版本之间的兼容性。
-
访问Doris Spark Connector的GitHub仓库,选择合适的版本进行下载。
Doris Spark Connector JAR包的命名格式为 spark-doris-connector-spark-${spark_version}-${connector_version}.jar。例如,您使用的引擎版本为esr-3.1.0 (Spark 3.4.3, Scala 2.12),则可以下载 spark-doris-connector-spark-3.4-24.0.0.jar。
-
将下载的Spark Connector JAR上传至阿里云OSS中,上传操作可以参见简单上传。
步骤二:创建网络连接
EMR Serverless Spark需要能够打通与EMR Doris集群之间的网络才可以正常访问Doris服务。更多网络连接信息,请参见EMR Serverless Spark与其他VPC间网络互通。
重要:配置安全组规则时,端口范围请根据实际需求选择性开放必要的端口。端口范围的取值为1~65535。本文示例需开启HTTP 端口(8031)、RPC 端口(9061)以及Webserver端口(8041)。
步骤三:在EMR Doris集群中创建库表
-
使用SSH方式登录集群,详情请参见登录集群。
-
执行以下命令,连接EMR Doris集群。
mysql -h127.0.0.1 -P 9031 -uroot
-
创建数据库和表。
CREATE DATABASE IF NOT EXISTS testdb;
USE testdb;
CREATE TABLE test ( id INT, name STRING) PROPERTIES("replication_num" = "1");
4. 插入测试数据。
INSERT INTO test VALUES (1, 'a'), (2, 'b'), (3, 'c');
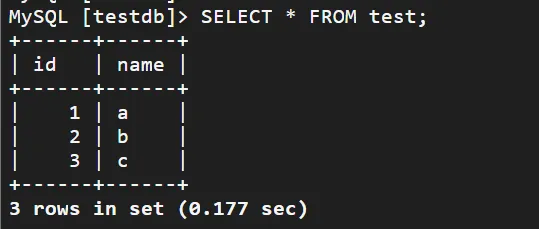
5. 查询数据。
SELECT * FROM test;
返回信息如下图所示。
步骤四:EMR Serverless Spark读取Doris表
使用 SQL 会话读 Doris 表
-
创建SQL会话,详情请参见管理SQL会话。
创建会话时,在引擎版本下拉列表中选择与Doris Spark Connector版本对应的引擎版本,在网络连接中选择步骤二中创建好的网络连接,并在Spark配置中添加以下参数来加载Doris Spark Connector。
spark.user.defined.jars oss://<bucketname>/path/connector.jar
其中,oss://<bucketname>/path/connector.jar为您步骤一中上传至OSS的Doris Spark Connector的路径。例如,oss://emr-oss/spark/spark-doris-connector-spark-3.4-24.0.0.jar。
-
在数据开发页面,选择创建一个SQL > SparkSQL类型的任务,然后在右上角选择创建好的SQL会话。
更多操作,请参见SparkSQL开发。(链接:https://x.sm.cn/BJPDwLp)
-
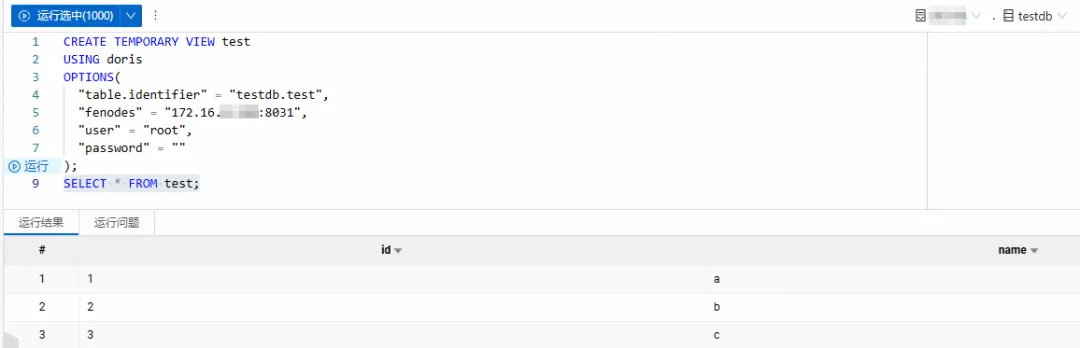
拷贝如下代码到新增的SparkSQL页签中,并根据需要修改相应的参数信息,然后单击运行。
CREATE TEMPORARY VIEW testUSING dorisOPTIONS( "table.identifier" = "testdb.test", "fenodes" = "<doris_address>:<http_port>", "user" = "<user>", "password" = "<password>");
SELECT * FROM test;
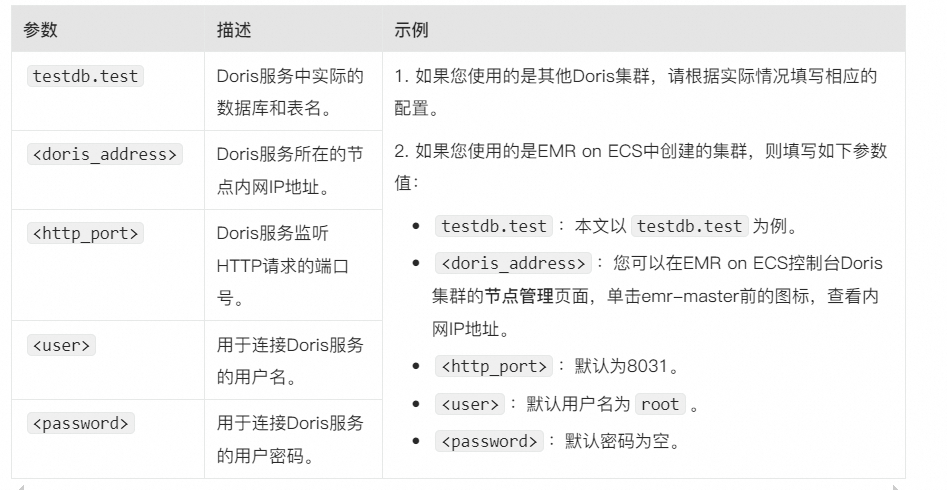
其中,涉及参数信息说明如下。

如果能够正常返回数据,则表明配置正确。
使用 Notebook 会话读 Doris 表
-
创建Notebook会话,详情请参见管理Notebook会话。
创建会话时,在引擎版本下拉列表中选择与Doris Spark Connector版本对应的引擎版本,在网络连接中选择步骤二中创建好的网络连接,并在Spark配置中添加以下参数来加载Doris Spark Connector。
spark.user.defined.jars oss://<bucketname>/path/connector.jar
其中,oss://<bucketname>/path/connector.jar 为您步骤一中上传至OSS的Doris Spark Connector的路径。例如,oss://emr-oss/spark/spark-doris-connector-spark-3.4-24.0.0.jar。
-
在数据开发页面,选择创建一个Python > Notebook类型的任务,然后在右上角选择创建的Notebook会话。
更多操作,请参见管理Notebook会话。
-
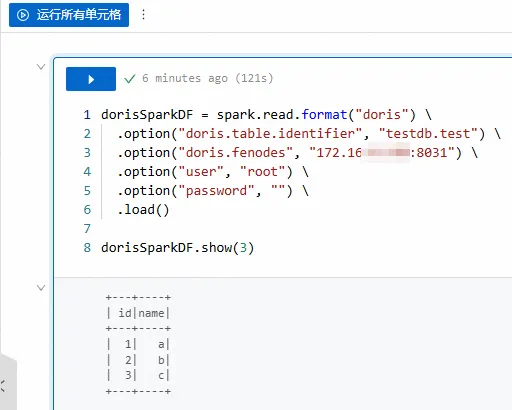
拷贝如下代码到新增的Notebook页签中,并根据需要修改相应的参数信息,然后单击运行。
dorisSparkDF = spark.read.format("doris") \ .option("doris.table.identifier", "testdb.test") \ .option("doris.fenodes", "<doris_address>:<http_port>") \ .option("user", "<user>") \ .option("password", "<password>") \ .load()
dorisSparkDF.show(3)
其中,涉及参数信息说明如下。
如果能够正常返回数据,则表明配置正确。
步骤五:EMR Serverless Spark写入Doris表
使用 SQL 会话写 Doris 表
拷贝如下代码到前一个步骤中新增的SparkSQL页签中,并根据需要修改相应的参数信息,然后单击运行。
CREATE TEMPORARY VIEW test_writeUSING dorisOPTIONS( "table.identifier" = "testdb.test", "fenodes" = "<doris_address>:<http_port>", "user" = "<user>", "password" = "<password>");
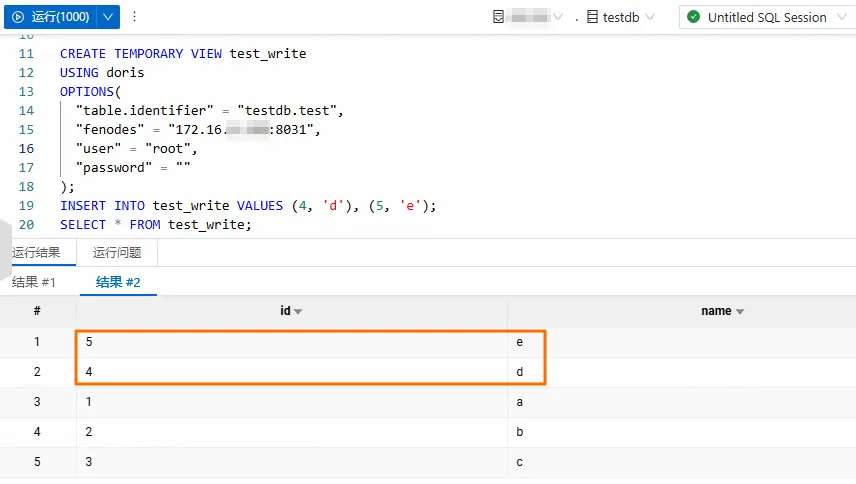
INSERT INTO test_write VALUES (4, 'd'), (5, 'e');SELECT * FROM test_write;
如果能够返回以下数据,则表明数据写入成功。
使用 Notebook 会话写 Doris 表
拷贝如下代码到前一个步骤中新增的Notebook页签中,并根据需要修改相应的参数信息,然后单击运行。
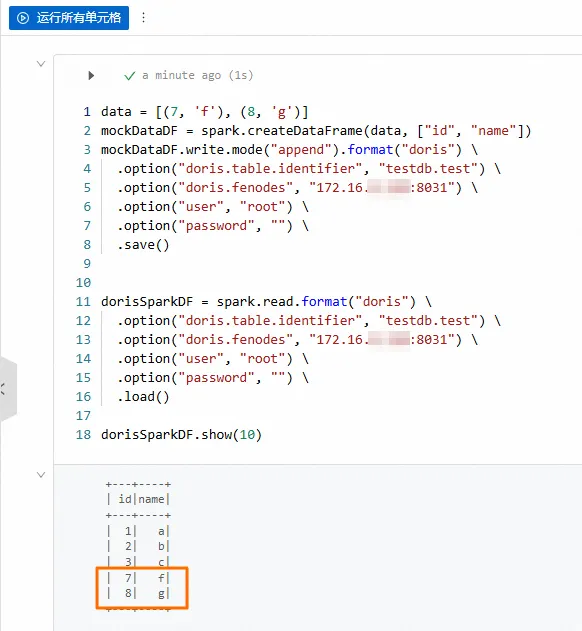
data = [(7, 'f'), (8, 'g')]mockDataDF = spark.createDataFrame(data, ["id", "name"])mockDataDF.write.mode("append").format("doris") \ .option("doris.table.identifier", "testdb.test") \ .option("doris.fenodes", "<doris_address>:<http_port>") \ .option("user", "<user>") \ .option("password", "<password>") \ .save() dorisSparkDF = spark.read.format("doris") \ .option("doris.table.identifier", "testdb.test") \ .option("doris.fenodes", "<doris_address>:<http_port>") \ .option("user", "<user>") \ .option("password", "<password>") \ .load()
dorisSparkDF.show(10)
如果能够返回以下数据,则表明数据写入成功。
如果您在使用 EMR Serverless Spark 的过程中遇到任何疑问,可加入钉钉群58570004119咨询。
开源 Java 工具 - Hutool 致大家的一封信 Visual Studio Code 1.99 发布,引入 Agent 和 MCP 亚马逊在最后一刻提交了收购 TikTok 的报价 FFmpeg 愚人节整活:加入 DOGE 团队,用汇编重写美国社保系统 龙芯 2K3000(3B6000M)处理器流片成功 中国首款全自研高性能 RISC-V 服务器芯片发布 清华大学开源软件镜像站的愚人节彩蛋 比尔·盖茨公开自己写过的“最酷的代码” Linus 口吐芬芳:怒斥英特尔工程师提交的代码是“令人作呕的一坨” CDN 服务商 Akamai 宣布托管 kernel.org 核心基础设施