
背景:为什么需要一个「裁判员大语言模型」?
随着大模型(LLM)技术的爆发式应用,如何快速、客观评估模型回复质量成为行业痛点。对于回答客观问题的LLM,目前业内已经有比较成熟的数据集进行效果评测与模型打榜。但是如何对一个开放式生成LLM进行效果评估,尤其在知识问答、客服对话、内容合规、RAG(检索增强生成)等场景中,目前主流的评测方式仍存在一定的局限性:
-
人工标注:成本高昂、效率低下;
-
传统的自动化评估工具:往往局限于单一指标(如BLEU、ROUGE),缺乏一个全面且多维度的评估体系;同时,对于一些没有明确答案的生成式问题,该方法局限性较大;
-
综合性大模型:虽然具备广泛的通用能力,但在特定垂类任务(如评估回复质量)上的表现可能不够精细。同时,使用综合性大模型评估LLM回复,可能存在有潜在法务风险、价格昂贵、时间成本高、使用门槛高等问题;
针对以上LLM评测过程中遇到的问题与局限性,阿里云人工智能平台PAI推出PAI-Judge裁判员大模型,为用户构建符合应用场景的多维度、细粒度的评测体系,支持单模型评测和双模型竞技两种模式,允许用户自定义评分标准、评分流程、生成温度等参数,实现了准确,灵活,高效的模型自动化评测,为模型迭代优化提供数据支撑。
核心优势
效果概览
截止2025年3月,基于QWen大模型finetune的裁判员模型PAI-Judge系列,在真实业务场景数据集上,与直接使用高阶通用大模型(如QwenMax、GPT-4o、Deepseek-v3)做裁判员模型相比,在中文场景中,综合效果明显优于GPT-4o与Deepseek-v3,与效果最好的QwenMax表现几乎相当。尤其在回答确定性/数学类问题、角色扮演、创意文体写作、翻译等场景下,PAI-Judge系列模型表现优异,可以直接用于大模型的评估与质检。
应用场景与用户反馈
自PAI-Judge上线以来,主要涉及:信息抽取、情感辨别、语音助手回复、私域知识问答(包含RAG)、内容合规审核等真实场景的打分与评测。同时,裁判员模型支持自然语言与json两种输出格式,且支持中英文两种任务语言。用户反馈PAI-Judge的评测效果可以与行业内的多个头部大模型比肩。
成本与请求效率
PAI-Judge是专门针对评测场景设计的大语言模型,与业内一流大模型相比,PAI-Judge的参数量更小、评测效率更高,具有明显的价格优势。目前限时推广,每个阿里云账号开通即可赠送100万免费Token!
快速试用通道
登录PAI控制台(https://pai.console.aliyun.com/?#/ai-service/judge/welcome)
单击立即开通,然后按照控制台操作指引,开通模型服务
评测示例
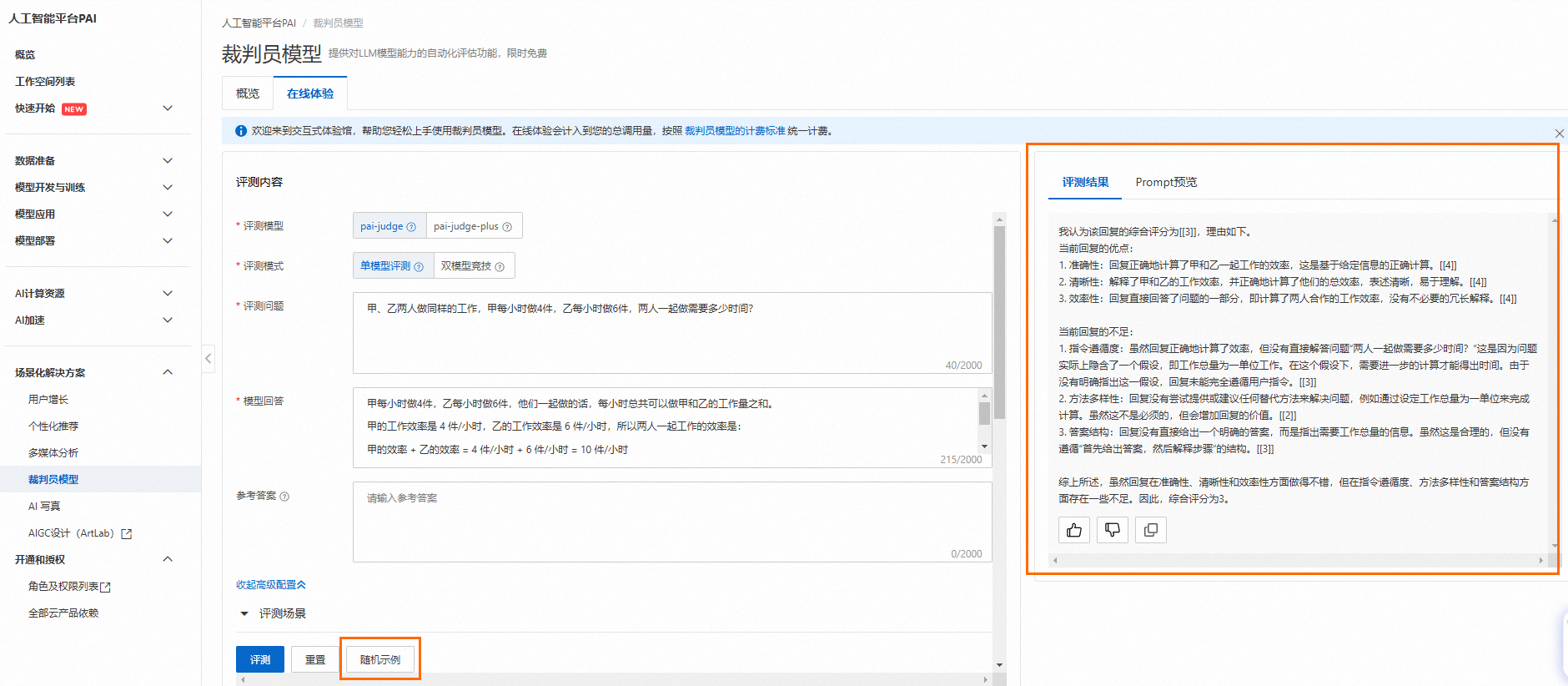
如果对试用结果满意,想直接使用PAI-Judge进行评测,可参考文章最后的裁判员模型API使用教程
评测效果分析
评估集
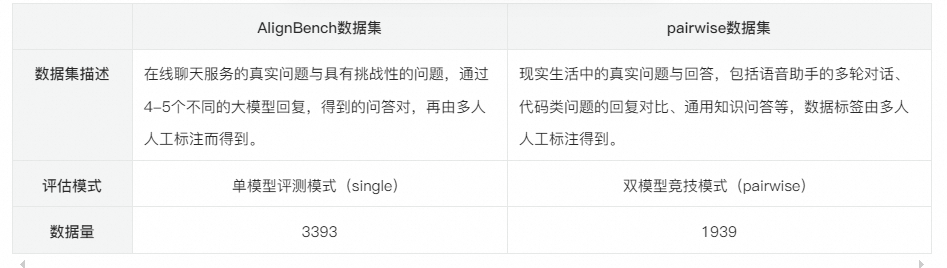
场景分类
PAI-Judge的场景共分成10类,基本可覆盖LLM领域涉及的全部问题场景。同时,用户也可以在使用时自行定义更加符合自身业务需要的场景与场景描述。

评测效果
指标定义
单模型评测模式
-
MAE(mean absolute error) : 模型评分与人工标注的绝对差异平均 ⬇️
-
Agr(2,2) :模型评分与人工标注2阶2次一致率,评分相同权重为1,相差1权重为0.25,分母为样本数量 ⬆️
双模型竞技模式
-
MAE (mean absolute error) :模型评分与人工标注的绝对差异平均 ⬇️
-
Acc(accuracy):模型评分与人工标注的重合概率⬆️
整体效果对比
-
在双模型竞技的pairwise数据集中,PAI-Judge的表现非常优异;
-
在单模型评测的alignbench数据集中,PAI-Judge的表现与效果最好的大模型不相上下;
场景实践
截至2025年3月,PAI-Judge已在多个领域实现规模化应用,涵盖信息抽取、情感分析、语音助手回复优化、私域知识问答(含RAG架构)以及内容合规审核等场景。为更直观地展示裁判员模型的评测能力,并深入挖掘其应用价值,我们精选了以下典型场景进行详细解析。
检索增强生成(RAG)
该RAG场景为针对某智能手机的客服机器人回复,主要涉及手机本身的问题回答,涉及多国语言,包括小语种。
问答对示例

评测prompt建议

注:以上参数的使用与自定义prompt的使用方式请参考文章最后的裁判员模型API使用教程
信息提取
该场景为根据一段新闻内容,输出新闻分类,或根据广告内容,输出广告营销策略名,并涉及规范化输出判别。
问答对示例

评测prompt建议

注:以上参数的使用方式请参考文章最后的裁判员模型API使用教程
未来规划
未来我们将会对PAI-Judge的功能与模型进行优化与迭代,主要包括以下几个方向:
-
参考Deepseek-R1,引入强化学习与R1模型,提升PAI-Judge在完全自定义模板上的指令遵循度(正在进行内部测试);
-
重点提升模型在私域知识库与专业领域场景下的评测精度。
使用教程
请参考:
裁判员模型概述:https://help.aliyun.com/zh/pai/user-guide/judge-model
裁判员模型API使用说明:https://help.aliyun.com/zh/pai/user-guide/judge-model-api-reference
人工智能平台PAI:https://pai.console.aliyun.com/?#/ai-service/judge/welcome
开源 Java 工具 - Hutool 致大家的一封信 Visual Studio Code 1.99 发布,引入 Agent 和 MCP 亚马逊在最后一刻提交了收购 TikTok 的报价 FFmpeg 愚人节整活:加入 DOGE 团队,用汇编重写美国社保系统 龙芯 2K3000(3B6000M)处理器流片成功 中国首款全自研高性能 RISC-V 服务器芯片发布 清华大学开源软件镜像站的愚人节彩蛋 比尔·盖茨公开自己写过的“最酷的代码” Linus 口吐芬芳:怒斥英特尔工程师提交的代码是“令人作呕的一坨” CDN 服务商 Akamai 宣布托管 kernel.org 核心基础设施