
近日,在华为全联接大会2024期间,华为常务董事、ICT基础设施业务管理委员会主任汪涛重磅发布CANN 8.0。新版本新增80多个融合算子、100多个Ascend C API,自研NB2.0和NHR集合通信算法并全面适应于超节点方案,基于LLM P-D分离部署方案设计并发布LLMDataDist组件,同时支持图模式能力扩展库TorchAir,提升PyTorch在NPU上的大模型推理性能。
昇腾异构计算架构CANN作为昇腾AI生态的根基和锚点,基于软硬件深度协同优化,持续构建昇腾产品解决方案在性能、易用性、稳定性和开放生态等方面的竞争力,全面支撑客户和开发者基于昇腾算力进行原生创新。
1 新增80+融合算子,大模型性能再提升
CANN 8.0全新升级昇腾算子加速库,新增200多个深度优化的基础算子,同时新增和优化80多个融合算子,覆盖MoE、多模态等场景,大模型执行性能提升显著。
新版本中,CANN针对MoE关键流程节点新增MoeGatingTopKSoftmax算子融合gating部分的softmax和topk计算以减少访存;新增MoEInitRouting加速routing处理,新增GroupedMatMul支持专家分组和并发执行,融合后的算子可提升20%-70%的计算性能;针对多模态理解场景,将图像加载和预处理下沉到昇腾Device侧,解码和预处理性能提升88%。
同时,优化实现FlashAttention融合算子,支持伪量化场景MSD(Multi-Scale-Dequant)方案量化加速,分解Q为多个int8的线性组合,将计算从A16W8变为A8W8,访存减少接近100%,可达到70%-100%的性能提升效果。
针对大规模集群场景,新增实现AllGatherMatMul、MatMulReduceScatter、MatMulAllReduce等通算融合算子,使得训练场景算子性能平均提升20%+(整网8%+);推理场景算子平均性能提升14%+(整网5%+)。通算融合方案通过加速引擎协同机制,将AICore、AICPU、SDMA处理过程并行,从而实现计算和通讯相互掩盖,达到计算和通信并行的效果。
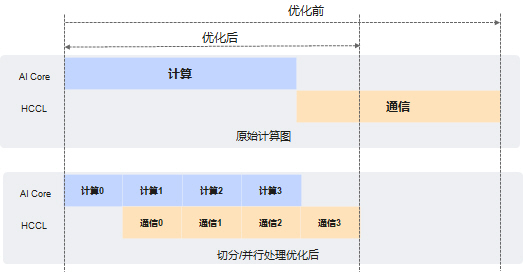
2 HCCL集成自研NB2.0和NHR等集合通信算法,全面适用于超节点方案
AI技术演进催生了全新的计算范式。长序列、多模态显著提升训练算力需求,然而,随着集群规模不断扩展,通信开销从原来的20%增长至50%以上,成为性能瓶颈,使得算力无法充分利用。在此情况下,基于高速总线互联的超节点技术逐渐成为解决问题的方案,同时,对于通信优化算法以及分布式并行算法也提出更高要求。
CANN8.0版本推出自研NB2.0通信算法,在硬件层面进行自适应通信域优化,复用SIO/HCCS/RoCE通信带宽,通过更细粒度的并行策略,减少通信步数,充分利用超节点通信全链路,将带宽利用率从不足40%提升到了60%+,整网性能提升20%+。
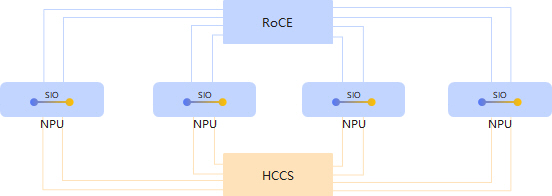
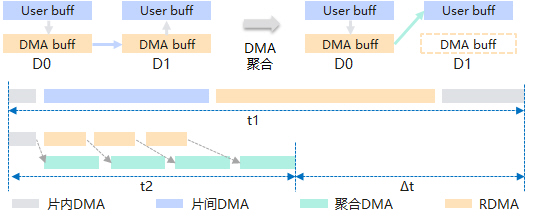
同时,为解决大模型通信横跨多个带宽域而出现的带宽利用率低的问题,CANN自研NHR通信算法(Nonuniform Hierarchical Ring,非均衡的层次环算法),一方面采用多层次环状通信模式减少网络流量冲突,另一方面支持RDMA/DMA任务流水,在跨机通信场景下同时聚合片内、片间DMA任务,实现内存免拷贝。实测1GB数据量场景下,跨机集合通信算法性能可提升70%~100%。
3 基于LLM P-D分离部署方案设计并发布LLMDataDist组件
大模型推理的Prefill和Decode阶段往往存在计算和内存受限问题,资源分配不均,导致成本居高不下,这些趋势和挑战,都驱动着推理系统的重构,以更高效的资源调度与并行解码,满足推理商业落地的经济性要求。
考虑到LLM推理Prefill和Decode两阶段的计算/通信特征各有差异,例如Prefill阶段是算力密集型,而Decode阶段是访存密集型且请求batch化执行,将Prefill-Decode分别部署在不同实例甚至不同集群中能有效提升系统有效吞吐Goodput。
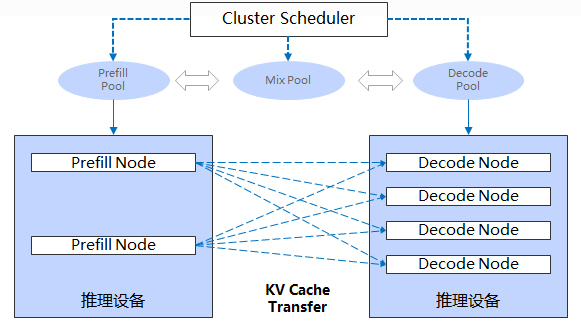
P-D分离部署方案根据Prefill和Decode的不同特点,将它们分别部署到不同规格和架构的推理集群上,配合服务层的任务调度,在满足TTFT和TBT时延指标范围内,结合Continuous batching机制尽可能提高Decode阶段的batch并发数,提升该阶段的算力利用率;根据业务流量和Input/output负载不同,基于LLMDataDist的动态LINK Manager管理能力,灵活设置P/D节点的集群配比数,在Serving服务运行过程中支持时延无感知的节点动态扩缩容,也可以在运行过程中实时灵活切换P/D角色。
对于分离集群间的KVCache传输,通过昇腾AI处理器自带的8 * 200G RoCE网卡,独立的KVCache传输通信链路与P/D模型并行使用的HCCS链路完全物理隔离,使大多数场景传输额外时延控制在一个token的生成开销内,同时也隐藏在Prefill计算过程中。
此外,P-D分离部署方案给P/D的独立优化提供了更大的空间,例如在长序列场景,Prefill节点采用通信友好的TP+SP/CP混合并行,Decoder节点采用时延敏感的纯TP并行;
CANN8.0针对LLM P-D分离部署方案设计并发布LLMDataDist组件,支持分布式集群通信和数据管理,LLMDataDist利用昇腾集群多样化通信链路(HCCS/RoCE)实现跨实例和集群高效KVCache传输,并支持与主流LLM推理框架如MindIE-LLM、vLLM等集成。
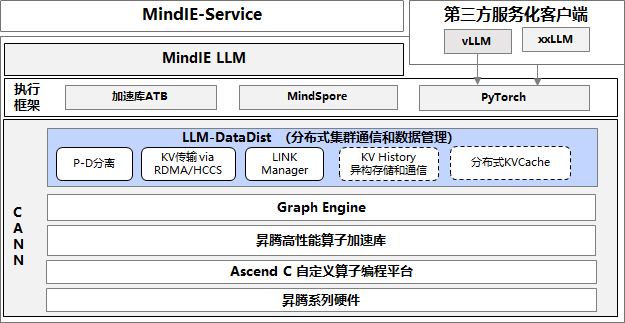
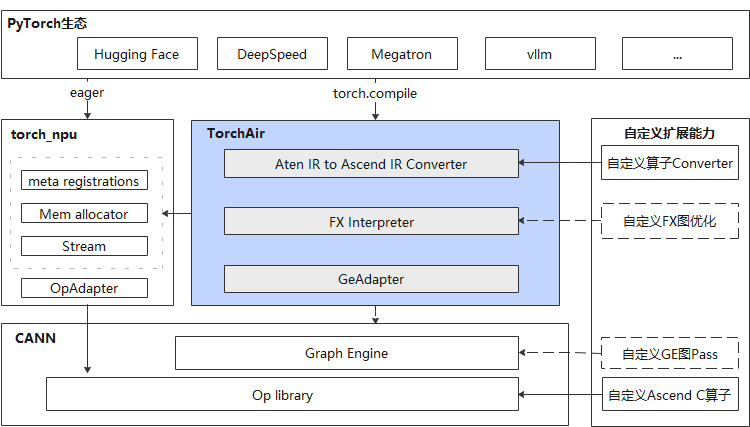
4 支持图模式能力扩展库TorchAir,提升PyTorch在NPU上的大模型推理性能
2023年10月,CANN支持Ascend Extension for PyTorch(torch_npu),这意味着开发者可直接在昇腾设备上选择PyTorch作为前端推理框架,使用PyTorch的eager模式进行推理。为消除Eager模式下的调度时延,进一步提升大模型的推理表现,CANN 8.0新增支持torch_npu图模式能力扩展库TorchAir(Torch Ascend Intermediate Representation),对上通过torch.compile的npu_backend接入PyTorch FX图,并将FX图转换成Ascend IR graph,向下通过CANN的图引擎来获取调度、图融合、算子融合等性能收益。
TorchAir在生态上,完整继承PyTorch软件生态;编程体验上,完全复用PyTorch编程体验;性能上,基于CANN的图引擎获取NPU最优性能;用户扩展性上,可快速完成Ascend C算子入图注册。当前TorchAir已经应用于LLM、多模态等全场景推理网络。
5 Ascend C新增100+ API,算子开发效率提升30%
工欲善其事,必先利其器,大模型融合算子的开发离不开新一代算子编程语言Ascend C。作为算子开发利器,Ascend C针对昇腾硬件能力进行抽象和封装,为开发者提供稳定和兼容的分层API,是CANN实现大模型融合算子的基础。
新版本中,CANN进一步优化Ascend C的开发易用性,丰富数据搬运等底层API,提升开发灵活性,同时新增通信类、矩阵运算类等高层API,封装常用算法逻辑,减少重复开发,提升开发效率。例如Matmul算子代码量从几百行缩减到只有几行,典型融合算子开发效率可提升30%以上,极大程度提升大模型创新效率。

6 CANN深度开放策略
随着大模型的飞速演进,为更进一步提升AI计算效率,支撑开发者的算法创新诉求,CANN匹配开发者使用习惯,通过深度开放策略支持开发者原生创新,构筑差异化优势。目前已经开放图引擎、算子库、算子编程语言、编译器、运行时等能力,使能主流AI框架和加速库,更高效调用算力资源,支撑互联网、运营商、金融等行业的大模型创新和场景化落地。

同时,CANN持续提供最佳实践使能客户自主创新,目前社区已上线6个融合算子、27个Ascend C 高层API,以及7个HCCL通信算法样例。开发者可参考样例魔改,天级完成高性能算子开发,同时构筑了完备的能力构建体系,使能开发者自主开发,激发原生创新,目前已有17+客户基于CANN进行自主创新,完成了90+的高性能算子开发。
随着CANN 8.0版本的发布以及CANN的深度开放,相关教程和学习资源正在陆续上线昇腾社区(https://www.hiascend.com/software/cann),欢迎开发者使用体验。
开源 Java 工具 - Hutool 致大家的一封信 Visual Studio Code 1.99 发布,引入 Agent 和 MCP 亚马逊在最后一刻提交了收购 TikTok 的报价 FFmpeg 愚人节整活:加入 DOGE 团队,用汇编重写美国社保系统 龙芯 2K3000(3B6000M)处理器流片成功 中国首款全自研高性能 RISC-V 服务器芯片发布 清华大学开源软件镜像站的愚人节彩蛋 比尔·盖茨公开自己写过的“最酷的代码” Linus 口吐芬芳:怒斥英特尔工程师提交的代码是“令人作呕的一坨” CDN 服务商 Akamai 宣布托管 kernel.org 核心基础设施