摘要:
结肠镜检查被认为是检测结直肠癌及其前体的金标准。然而,现有的检查方法受到总体漏检率高的阻碍,并且许多异常未被发现。基于高级机器学习算法的计算机辅助诊断系统被吹捧为游戏规则改变者,可以识别医生在内窥镜检查中忽略的结肠区域,并帮助检测和表征病变。在以前的工作中,我们提出了 ResUNet++ 架构,并证明与对应的 U-Net 和 ResUNet 相比,它产生了更高效的结果。在本文中,我们证明了通过使用条件随机场 (CRF) 和测试时增强 (TTA) 可以进一步提高 ResUNet++ 架构的整体预测性能。我们使用六个公开可用的数据集进行了广泛的评估并验证了改进:Kvasir-SEG、CVC-ClinicDB、CVC-ColonDB、ETIS-Larib 息肉数据库、ASU-Mayo Clinic 结肠镜检查视频数据库和 CVC-VideoClinicDB。此外,我们将我们提出的架构和结果模型与其他最先进的方法进行了比较。为了探索 ResUNet++ 在不同公开可用的息肉数据集上的泛化能力,以便它可以在真实环境中使用,我们进行了广泛的跨数据集评估。实验结果表明,应用CRF和TTA可以提高同一数据集和跨数据集上各种息肉分割数据集的性能。为了检查模型在难以检测的息肉上的性能,我们在胃肠病专家的帮助下选择了 196 个小于 10 毫米的无蒂或扁平息肉。这些额外的数据已作为 Kvasir-SEG 的子集提供。我们的方法对扁平或无蒂和较小的息肉显示出良好的效果,众所周知,这是息肉漏诊率高的主要原因之一。这是我们工作的重要优势之一,表明我们的方法应该进一步研究以用于临床实践。
第一部分
介绍
癌症是当代社会的主要健康问题,结直肠癌 (CRC) 是全球癌症发病率第三大、死亡率第二大的类型 [2]。结直肠息肉是 CRC 的前体。通过高质量的结肠镜检查和定期筛查及早发现息肉是预防结直肠癌的基石 [3],因为腺瘤等肿瘤病变可以在转化为癌症之前被发现并切除,从而降低 CRC 的发病率和死亡率。
无论结肠镜检查在降低癌症负担方面取得的成就如何,估计腺瘤漏诊率约为 6-27% [5]。在最近一项对 8 项随机串联结肠镜检查研究的汇总分析中,小于 10 mm 的息肉、无蒂息肉和扁平息肉 [6] 最常被漏诊 [7]。漏诊息肉的另一个原因可能是息肉不在视野中,或者由于结肠镜的快速撤出而无法识别尽管在视野中 [8]。通过提高肠道准备质量、应用最佳观察技术和确保结肠镜撤出时间至少 6 分钟,可以降低腺瘤漏诊率 [8]。此外,还可以使用先进的技术或设备来提高腺瘤检出率,例如辅助成像设备、具有更大视野的结肠镜、附加设备以及带有集成充气、可重复使用球囊的结肠镜 [3]。
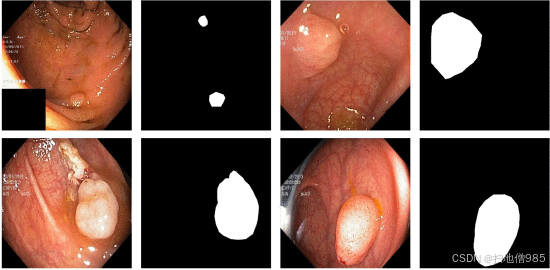
结直肠息肉的结构和特征在不同的发展阶段会随着时间的推移而变化。息有不同的形状、大小、颜色和外观,这使得它们难以分析(见图 1)。此外,还存在一些挑战,例如存在图像伪影,如模糊、手术器械、肠内容物、眩光和低质量图像,这些都可能在分割过程中导致错误。

息肉分割在临床应用中至关重要,可以关注潜在病变的特定区域,提取详细信息,并在必要时可能切除息肉。用于息肉分割的计算机辅助诊断 (CADx) 系统可以通过提高准确性、精度和减少人工干预来帮助监测和提高诊断能力。此外,与主观进行相比,它可能导致更少的分割错误。这样的系统可以减少医生的工作量并改善临床工作流程。管腔分割有助于临床医生在检查过程中浏览结肠,并且有助于建立探查到的结肠壁的质量指标 [9]。因此,自动化 CADx 系统可以用作支持工具,以降低被忽视的息肉的漏诊率。
如果 CADx 系统解决了两个常见的挑战,则可以在临床环境中使用:(i) 稳健性(即模型在简单和具有挑战性的图像上始终表现良好的能力)和 (ii) 泛化(即,在特定医院进行特定干预训练的模型应该在不同医院中泛化)[10].应对这些挑战是为医学图像设计强大的语义分割系统的关键。泛化能力检查模型在来自不同医院的不同可用数据集中的有用性,并且必须最终在多中心随机试验中得到确认。一个好的可推广模型可能是朝着开发可接受的临床系统迈出的重要一步。跨数据集评估对于检查来自其他来源的未见息肉的模型并测试其泛化性至关重要。
为了开发一个强大的 CADx 系统,我们之前提出了 ResUNet++ [1]:一种基于初始编码器-解码器的深度学习架构,用于医学图像分割,我们在公开可用的 Kvasir-SEG [4] 和 CVC-ClinicDB [11] 数据集上对其进行了训练、验证和测试。在本文中,我们描述了如何通过应用条件随机场 (CRF) 和测试时增强 (TTA) 来扩展 ResUNet++ 架构,以进一步提高其对分段息肉的预测性能。我们已经在六个公开可用的数据集上测试了我们的方法,包括图像数据集和视频数据集。我们有意整合了结肠镜检查的视频数据集以支持临床意义。通常,静止帧至少有一个息肉样本。视频的情况是帧同时由息肉和非息肉组成。因此,我们在这些视频数据集上测试了模型,并为分割任务提供了新的基准。我们使用了大量的数据增强来增加训练样本,并使用全面的超参数搜索来为数据集找到最佳超参数。我们通过纳入更多评估指标提供了更深入的评估,并增加了 ResUNet++、CRF 和 TTA 的理由。
此外,我们还对交叉数据评估进行了广泛的实验,对表现最好和表现最差的情况进行了深入分析,并将所提出的方法与其他最近的工作进行了比较。此外,我们指出了解决与扁平和无蒂息肉的漏检相关的任务的必要性,并表明我们的组合方法可以高效地检测被忽视的息肉,这在临床环境中可能具有重要意义。为此,我们还公开发布了一个由无柄或扁平息肉组成的数据集。此外,我们强调了跨数据集评估的使用,方法是使用来自各种来源的图像来训练和测试模型,以实现泛化性目标。
综上所述,主要贡献如下:
-
我们扩展了 ResUNet++ 深度学习架构 [1],用于使用 CRF 和 TTA 进行自动息肉分割,以实现更好的性能。定量和定性结果表明,应用 CRF 和 TTA 是有效的。
-
我们在大量数据集上验证了扩展架构,即 Kvasir-SEG [4]、CVC-ClinicDB [11]、CVC-ColonDB [12]、EITS-Larib [13]、ASU-Mayo Clinic 结肠镜检查视频数据库 [14] 和 CVC-VideoClinicDB [15]、[16],并将我们提出的方法与最近的最先进的 (SOTA) 算法进行比较,并设定了新的基线。此外,我们将我们的工作与其他最近的工作进行了比较,这在可比研究中往往是缺乏的。
-
在胃肠病专家的帮助下,我们从 Kvasir-SEG 中选择了 196 个在结肠镜检查中经常漏诊的扁平或无蒂息肉 [7]。我们已经在这个单独的数据集上进行了实验,以研究我们的模型在具有挑战性的息肉上的表现如何。此外,我们将这些息肉图像和分割掩码作为 Kvasir-SEG 数据集的一部分发布,以便研究人员可以构建新的架构并改进结果。
-
我们的模型可以更好地检测更小、扁平或无蒂的息肉,这些息肉在结肠镜检查中经常被遗漏 [7],与现有工作相比,这是一个主要优势。
-
在医学临床实践中,可推广的模型对于目标患者群体至关重要。我们的工作重点是泛化性,以前在社区中很少探索。为了推广可推广的深度学习 (DL) 模型,我们在 Kvasir-SEG 和 CVC-ClinicDB 上训练了我们的模型,并在五个公开可用的不同看不见的息肉数据集上测试和比较了结果。此外,我们混合了两个不同的数据集,并在其他看不见的数据集上进行了进一步的实验,以展示模型在使用不同设备捕获的图像上的行为。
第二部分
相关工作
在过去的几十年里,研究人员在开发用于自动息肉分割的 CADx 原型方面做出了多项努力。大多数以前的息肉分割方法都是基于分析息肉的边缘或其纹理。最近的方法使用卷积神经网络 (CNN) 和预训练网络。Bernal 等人。 [11] 介绍了一种新的息肉定位方法,该方法使用 WM-DOVA 能量图来准确突出显示息肉,无论其类型和大小如何。Pozdeev 等人。 [17] 提出了一个基于全卷积网络 (FCN) 的像素预测的全自动息肉分割框架。Bernal 等人。 [18] 主持了结肠镜检查视频中的自动息肉检测子挑战,随后,他们提出了自动息肉检测的不同方法的比较验证,并得出结论,基于 SOTA CNN 的方法提供了最有希望的结果。
Akbari 等人。 [19] 使用 FCN-8S 网络和 Otsu 的阈值方法进行自动结肠息肉分割。Wang 等人。 [20] 使用 SegNet [21] 架构来检测息肉。他们获得了高灵敏度、特异性和受试者工作特征 (ROC) 曲线值。他们的算法可以达到每秒 25 帧的速度,在实时视频分析期间会有一些延迟。Guo 等人。 [22] 使用全卷积神经网络 (FCNN) 模型进行胃肠道图像分析分析 (GIANA) 息肉分割挑战。所提出的方法在 2017 年 GIANA 挑战赛中获得了标清 (SD) 和高清图像的第一名,并在 2018 年 GIANA 挑战赛的标清图像分割任务中获得第二名。Yamada 等人。 [23] 开发了一种 CADx 支持系统,可用于实时检测息肉,减少结肠镜检查过程中漏诊异常的数量。
Poorneshwaran 等人。 [24] 使用生成对抗网络 (GAN) 进行息肉图像分割。Kang 等人。 [25] 使用依赖于 ResNet50 和 ResNet101 的 Mask R-CNN 作为自动息肉检测和分割的骨干结构。Ali 等人。 [26] 介绍了各种可以分类、分割和定位伪影的检测和分割方法。此外,最近有几项关于息肉分割的有趣研究 [27]–[30]。它们是构建自动息肉分割系统的有用步骤。也有一些工作假设,通过应用谨慎的后处理技术来耦合现有架构可以提高模型性能 [1]、[31]。
从所介绍的相关工作中,我们观察到息肉分割领域的自动 CADx 系统正在变得成熟。研究人员正在进行各种不同设计的研究,从回顾性研究、前瞻性研究到前瞻性获得的数据集的事后检查。一些模型使用较小的训练和测试数据集实现了非常高的性能 [1]、[20]、[32]。用于构建模型的算法是使用 ImageNet [33] 的手工制作、CNN 或预训练特征的算法,其中基于 DL 的算法性能优于并逐渐取代传统的手工制作或机器学习 (ML) 方法。此外,通过使用先进的 DL 算法提高了模型的性能,该算法专为息肉分割任务或任何其他类似的生物医学图像分割任务而设计。此外,人们有兴趣使用多个数据集 [1]、[20] 来测试所提出的架构。
该领域的主要缺点是,通过跨数据集测试可以实现的 CADx 系统的通用性测试所需的工作量最少。此外,设计一个可以准确分割来自不同来源的息肉的通用模型几乎不需要付出任何努力,这对于开发用于自动息肉分割的 CADx 至关重要。此外,目前的大多数工作都提出了在单个、通常是小的、不平衡的和明确精心挑选的数据集上进行测试的算法。这使得关于算法性能的结论几乎毫无用处(与 ML 中的其他领域相比,例如,自然图像分类或动作识别,在这些领域中,通常的做法是在多个数据集上进行测试,并将源代码和数据集公开可用)。此外,使用的数据集通常不公开可用(受限且难以访问),并且研究中使用的图像和视频总数不足以推测该系统是稳健的和可推广的,可用于临床试验。例如,该模型可以在特定数据集上生成具有高灵敏度和精度的输出分割图,而在其他模态图像上完全失败。此外,现有工作通常使用较小的训练和测试数据集。这些当前的限制使得开发健壮且可通用的系统变得更加困难。
因此,我们的目标是开发一个基于 CADx 的支持系统,无论数据集如何,都可以实现高性能。为了实现这一目标,我们对各种结肠镜检查图像和视频数据集进行了广泛的实验。此外,我们还混合了来自多个中心的数据集,并在其他不同的看不见的数据集上对其进行了测试,以实现构建可能不会产生分割误差的通用且强大的 CADx 系统的目标。此外,我们为公开可用的数据集设定了新的基准,这些基准在未来可以改进。
第三部分。
ResUNet++ 架构
ResUNet++ 是一种语义分割深度神经网络,专为医学图像分割而设计。ResUNet++ 架构的主干是 ResUNet [34]:一个基于 U-Net [35] 的编码器-解码器网络。所提出的架构利用了残差块、挤压和激发块 [36]、空洞空间金字塔池化 (ASPP) [37] 和注意力块 [38] 的优势。ResUNet++ 与 ResUNet 的区别在于在编码器上使用挤压和激励块(标记为深灰色),在桥接器和解码器上使用 ASPP 块(标记为深红色),在解码器上使用注意力块(标记为浅绿色)(见图 2)。
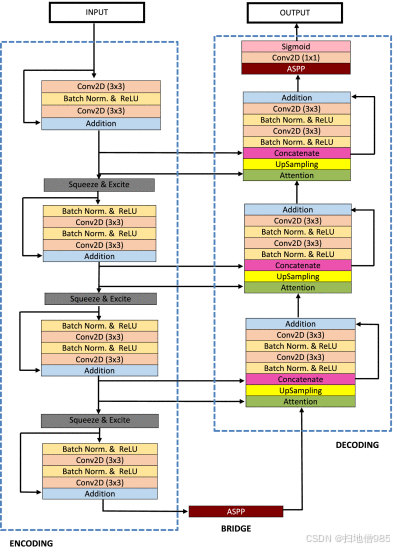
在 ResUNet++ 模型中,我们将 squeeze 和 excitation 模块的序列引入网络的编码器部分。此外,我们将 ResUNet 的桥替换为 ASPP。在解码器阶段,我们引入了一系列注意力块,最近邻上采样,并通过 skip 连接将其与编码器残差块中的相关特征图连接起来。这个过程之后是具有身份映射的残差单元,如图 2 所示。
我们还引入了一系列额外的 skip 连接,从 encoder 部分的 residual unit 到 decoder 部分的 attention 块。我们分配过滤器的数量 我们还引入了一系列额外的 skip 连接,从 encoder 部分的 residual unit 到 decoder 部分的 attention 块。我们分配过滤器的数量,以及编码器部分中的级别,这些是我们的 ResUNet++ 架构中的值。这些滤波器组合在我们的 ResUNet++ 实验中取得了最佳结果。在 decoder 部分,滤波器的数量颠倒,序列变为 $[512, 256, 128, 64, 32]$。由于编码器和解码器块的特征图之间的语义差距应该减小,因此解码器块卷积层中的滤波器数量也减少了,以实现更好的语义覆盖。通过这种方式,我们确保特征图的整体质量与 Ground Truth 掩码更相似。这一点尤其重要,因为语义空间的损失可能会减少,因此在语义空间中找到有意义的表示将变得更加可行。
整个 ResUNet++ 架构由一个带有三个编码器块的 stem 块、编码器和解码器之间的 ASPP 以及三个解码器块组成。所有 encoder 和 decoder 模块都使用标准的残差学习方法。编码器和解码器之间引入了跳过连接,用于信息传播。最后一个解码器块的输出通过 ASPP,然后是 整个 ResUNet++ 架构由一个带有三个编码器块的 stem 块、编码器和解码器之间的 ASPP 以及三个解码器块组成。所有 encoder 和 decoder 模块都使用标准的残差学习方法。编码器和解码器之间引入了跳过连接,用于信息传播。最后一个解码器块的输出通过 ASPP,后跟一个 卷积和 sigmoid 激活函数。除输出层外,所有卷积层都经过批量归一化 [39],并由修正线性单元 (ReLU) 激活函数 卷积和 sigmoid 激活函数。除输出层外,所有卷积层都经过批量归一化 ,并由修正线性单元 (ReLU) 激活函数 激活。最后,我们以二进制分割图的形式获得输出。以下小节提供了每个块的简要说明。 激活。最后,我们以二进制分割图的形式获得输出。以下小节提供了每个块的简要说明。
A. 残差块
通过扩展网络深度来训练深度神经网络可能会提高整体性能。然而,简单地堆叠 CNN 层也可能阻碍训练过程,并在发生反向传播时导致梯度爆炸/消失 [41]。残差连接通过将输入信息直接路由到输出来促进训练过程,并保持梯度流的高贵性。残差函数简化了优化目标,无需任何额外参数并提高了性能,这就是更深的基于残差的网络背后的灵感 [42]。下面的公式 (1) 显示了工作原理。
![]()
这里,这里 是输入,是残差函数。残差单元由批量归一化 (BN)、ReLU 和卷积层的多种组合组成。有关所用组合及其影响的详细说明,请参见 He 是输入,而 [43]. 我们在 ResUNet 的 ResUNet++ 架构中采用了预激活残差单元的概念。
B. 挤压和激励模块
squeeze and excitation (SE) 模块是 CNN 的构建模块,它通过显式建模通道之间的相互依赖关系来重新校准通道级特征响应 [36]。SE 块通过全局空间信息学习通道权重,这增加了有效特征图的灵敏度,而它抑制了不相关的特征图 [1]。卷积生成的特征图只能访问局部信息,这意味着它们无法访问局部感受野留下的全局信息。为了解决这一限制,我们使用全局平均池对特征图执行 squeeze作,以生成全局表示。然后,我们使用全局表示并执行 sigmoid 激活,这有助于我们学习通道之间的非线互,并捕获通道依赖性。在这里,sigmoid 激活输出充当一个简单的门控机制,确保我们自适应地重新校准卷积产生的特征图。自适应重新校准或激励作明确地对特征通道之间的相互依赖关系进行建模。SE 网络具有在各种数据集中非常好地泛化的能力 [36]。在 ResUNet++ 架构中,我们将 SE 块与残差块堆叠在一起,以提高网络的性能,增加跨不同医疗数据集的有效泛化。
C. Atrous 空间金字塔池化
自从 Chen 等人引入 atrous 卷积以来。 [44] 为了控制视野以精确捕获多尺度的上下文信息,它已经显示出语义图像分割的良好结果。后来,Chen 等人。 [45] 提出了 ASPP,它是一个并行的 atrous 卷积块,用于同时捕获多尺度信息。ASPP 捕获不同尺度的上下文信息,并融合输入特征图中具有不同速率的多个并行 atrous 卷积 [45]。在 ResUNet++ 中,我们使用 ASPP 作为编码器和解码器部分之间的桥梁,并在最终的解码器块之后。我们在 ResUNet++ 中采用 ASPP 来捕获编码器和解码器之间有用的多尺度信息。
D. 注意力单位
Chen 等人。 [46] 提出了一种注意力模型,可以通过多尺度输入处理来分割自然图像。注意力模型是对平均和最大池化基线的改进,并允许在不同尺度和位置可视化特征的重要性 [46]。随着注意力机制的成功,各种医学图像分割方法已经将注意力机制集成到其架构中[1],[47]–[49]。注意力块重视网络的子集,以突出显示最相关的信息。我们推测,我们架构中的注意力机制将通过捕获相关的语义类并过滤掉不相关的信息来提高网络特征图的有效性。受医学图像分割和计算机视觉领域注意力机制最新成就的启发,我们在 ResUNet++ 模型的解码器部分集成了一个注意力块。
E. 条件随机字段
条件随机场 (CRF) 是一种流行的统计建模方法,当不同输入的类标签不独立时使用(例如,图像分割任务)。CRF 可以模拟有用的几何特征,如形状、区域连通性和上下文信息 [50]。因此,使用 CRF 可以进一步提高模型捕获息肉上下文信息的能力,从而改善整体结果。我们使用 CRF 作为进一步的步骤,为测试数据集生成更精细的输出,以改善分割结果。我们在实验中使用了密集的 CRF。
F. 测试时间增强
测试时增强 (TTA) 是一种对测试数据集进行合理修改以提高整体预测性能的技术。在 TTA 中,将增强应用于每个测试图像,并创建多个增强图像。之后,我们对这些增强图像进行预测,并将每个增强图像的平均预测作为最终的输出预测。受最近 SOTA [22] 改进的启发,我们在工作中使用了 TTA。在本文中,我们将水平和垂直翻转用于 TTA。
第四部分。
实验
A. 数据集
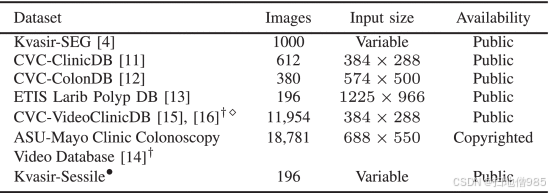
我们在实验中使用了六个不同的分段息肉数据集,如表 I 所示,即 Kvasir-SEG [4]、CVC-ClinicDB [11]、CVC-ColonDB [12]、ETIS Larib 息肉 DB [13]、CVC-VideoClinicDB [15]、[16] 和 ASU-Mayo Clinic 结肠镜检查视频数据库 [14].例如,它们在图像数量、图像分辨率、可用性、用于捕获的设备以及分割掩码的准确性方面有所不同。图 3 中给出了 Kvasir-SEG 的一个例子。Kvasir-SEG 数据集包括 196 个小于 10 毫米的息肉,分为 Paris 1 类无柄或 Paris IIa 类。我们已将此数据集作为 Kvasir-SEG 的子集单独发布。请注意,对于 CVC-VideoClinicDB,我们只使用了 CVC-VideoClinicDBtrainvalid 文件夹中的数据,因为只有这些数据具有真值掩码。此外,在 Endovis 2015 的“结肠镜视频中的息肉自动检测”子挑战赛中提供的亚利桑那州立大学-梅奥诊所结肠镜检查视频数据库有 10 个正常视频(阴性镜头)和 10 个息肉视频。但是,由于与许可相关的问题,测试子集不可用。在我们的实验中,在 ASU-Mayo 上以 80:10:10 分割进行训练、验证和测试时,我们使用了所有 20 个视频进行实验。然而,对于跨数据集测试(即表 X 和 XI),我们只测试了 10 个阳性息肉视频。
B. 评估方法
为了评估息肉分割方法,其中应该识别和标记单个像素,我们使用了早期研究 [4]、[18]、[20]、[22]、[26]、[51] 以及 GIANA 等比赛中使用的指标,1比较结果的正确和错误识别像素。骰子系数 (DSC) 和交并比 (IoU) 是最常用的指标。我们使用 DSC 来比较生成的分割结果与原始地面实况之间的相似性。同样,IoU 用于比较输出掩码与息肉的原始真值掩码之间的重叠。交集与并集的平均数 (mIoU) 计算图像的每个语义类的 IoU 并计算所有类的平均值。DSC 和 mIoU 之间存在相关性。但是,我们计算这两个指标是为了提供全面的结果分析,从而更好地理解结果。
此外,二元分类的其他常用指标是召回率(真阳性率)和精确率(阳性预测值)。对于息肉分割,精度是正确分割的像素数与所有像素总数的比率。同样,召回率是正确分割的像素与地面实况中存在的像素总数的比率。在息肉图像分割中,精度和召回率用于表示过度分割和不足分割。有关正式定义和公式,请参见例如 [4]、[51] 中的定义。最后,受试者工作特征 (ROC) 曲线分析也是表征二元分类系统性能的重要指标。因此,在我们的研究中,我们在评估分割模型时计算 DSC 、 mIoU 、召回率、精度和 ROC。
C. 数据增强
数据增强是增加息肉样本数量的关键步骤。这解决了数据不足问题,提高了模型的性能,并有助于减少过度拟合。我们使用了大量不同的数据增强技术来增加训练样本。我们根据随机分布使用 80:10:10 的比例将所有息肉数据集分为训练集、验证集和测试集,但混合数据集除外。拆分数据集后,我们应用数据增强技术,例如中心裁剪、随机旋转、转置、弹性变换、网格失真、光学失真、垂直翻转、水平翻转、灰度、随机亮度、随机对比度、色相饱和度值、RBG 偏移、航向丢失和不同类型的模糊。为了裁剪图像,我们使用了 数据增强是增加息肉样本数量的关键步骤。这解决了数据不足问题,提高了模型的性能,并有助于减少过度拟合。我们使用了大量不同的数据增强技术来增加训练样本。我们根据随机分布使用 80:10:10 的比例将所有息肉数据集分为训练集、验证集和测试集,但混合数据集除外。拆分数据集后,我们应用数据增强技术,例如中心裁剪、随机旋转、转置、弹性变换、网格失真、光学失真、垂直翻转、水平翻转、灰度、随机亮度、随机对比度、色相饱和度值、RBG 偏移、航向丢失和不同类型的模糊。为了裁剪图像,我们使用了 像素的裁剪大小。对于实验,我们已将完整的训练、验证和测试数据集的大小调整为 $256 \times 256$ 像素,以降低计算复杂性。我们只扩充了训练数据集。验证数据没有增加,测试数据集在使用 TTA 进行评估时进行了增加。
D. 实现和硬件详细信息
我们使用 Keras 框架 [52] 和 Tensorflow [53] 作为后端实现了所有模型。我们实现的源代码和有关我们的实验设置的信息在 Github 上公开提供。2我们的实验是在能够实现 2-petaFLOPS 张量性能的 Nvidia DGX-2 AI 系统上使用 Volta 100 Tensor Core GPU 进行的。我们使用了安装了 Cuda 10.1.243 版本的 Ubuntu 18.04.3LTS作系统。我们在同一数据集上手动使用不同的超参数集进行了不同的实验,以便为 ResUNet++ 选择最佳的超参数集。我们的模型在批量大小为 16、Nadam 作为优化器、二进制交叉熵作为损失函数以及 的学习率下表现良好。骰子损失功能也很有竞争力。这些超参数是根据实证评估选择的。所有模型都进行了 300 个 epoch 的训练。我们使用了早期停止来防止模型过度拟合。为了进一步改进结果,我们使用了热重启随机梯度下降 (SGDR)。除了学习率外,所有超参数都相同,学习率是根据要求进行调整的。我们还提供了 Tensorboard,用于分析和可视化结果。
第五部分
结果
在我们之前的工作中,我们已经表明 ResUNet++ 优于在 Kvasir-SEG 和 CVC-ClinicDB 数据集 [1] 上训练的 SOTA UNet [35] 和 ResUNet [34] 模型。在这项工作中,我们的目标是通过利用进一步的超参数优化、CRF 和 TTA 来改善 ResUNet++ 的结果。在本节中,我们介绍并比较了 ResUNet++ 与 CRF、TTA 以及在同一数据集、混合数据集和跨数据集上组合的两种方法的结果。尽管由于不同作者使用的不同测试机制,很难对文献中的方法进行直接比较,但我们仍然将结果与最近的工作进行比较以进行评估。
A. Kvasir-SEG 数据集上的结果比较
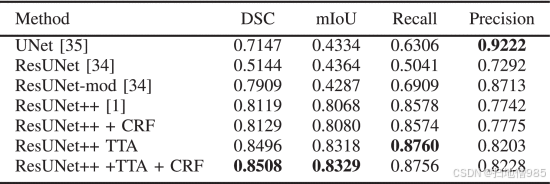
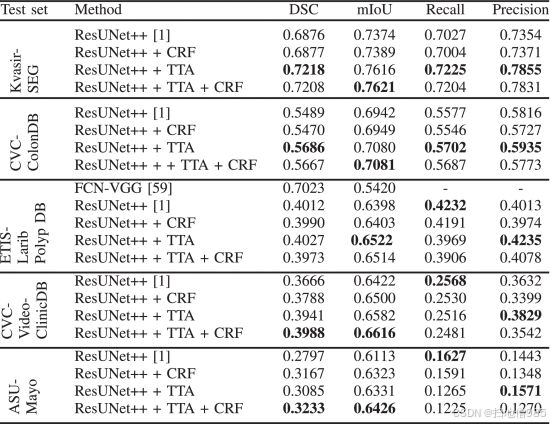
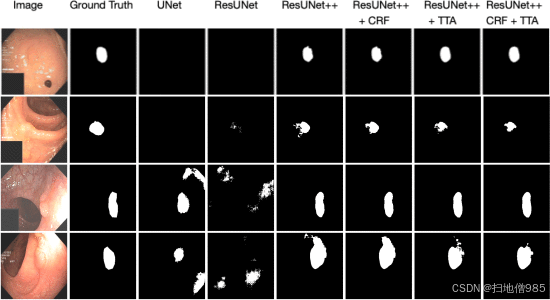
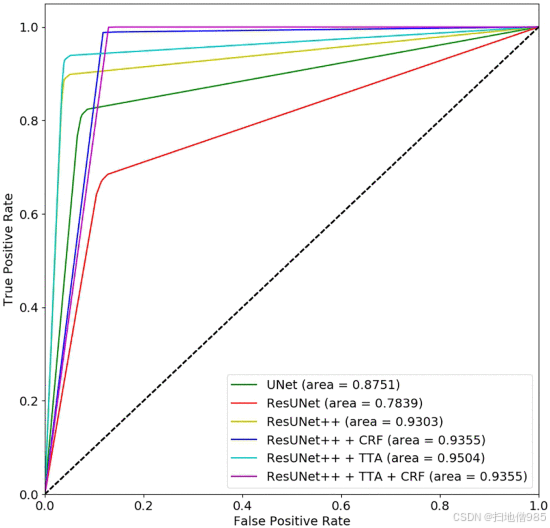
表 II 和图 4 显示了定量和定性结果的比较。图 7 显示了所有模型的 ROC 曲线。从定量结果(表 II)、定性结果(图 4)和 ROC 曲线(图 7)中可以看出,我们提出的方法在 Kvasir-SEG 数据集上优于 ResUNet++。结果的改善证明了使用 TTA、CRF 及其组合的优势。


B. CVC-ClinicDB上的结果比较
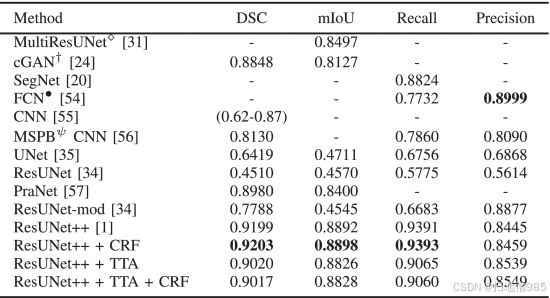
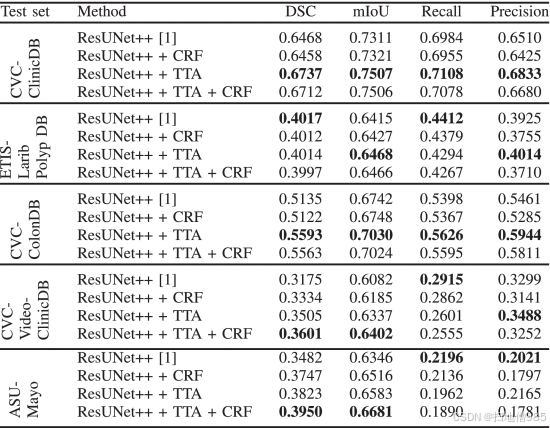
CVC-ClinicDB 是息肉分割的常用数据集。因此,我们将文献中的不同作品放在一起,并将建议的算法与现有作品进行比较变得很重要。我们将我们的算法与 SOTA 算法进行比较。表 III 表明,ResUNet++ 和 CRF 的组合实现了 0.9293 的 DSC 和 0.8898 的 mIoU,分别比 PraNet [57] 的 DSC 和 mIoU 提高了 4.98%,所提出的方法显示了 CVC-ClinicDB 上的 SOTA 结果。
ROC 曲线衡量分类问题的性能,前提是设定了阈值。我们将概率阈值设置为 0.5。ResUNet++ 和 TTA 的组合具有最大的曲线下面积 - 受试者工作特征 (AUC-ROC) 为 0.9814,如图 8 所示。因此,表 III 和图 8 中的结果表明,应用 TTA 对 CVC-ClinicDB 有改进。

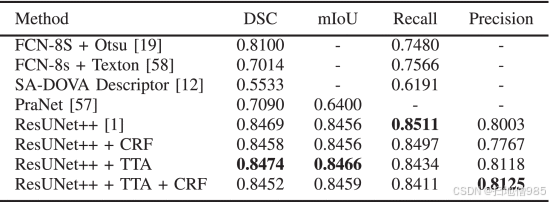
C. CVC-ColonDB 数据集的结果比较
我们使用 CVC-ColonDB 数据集的结果如表 IV 所示。该表显示,所提出的结合 ResUNet++ 和 TTA 的方法实现了最高的 DSC 0.8474,比 SOTA [19] 高 3.74%,mIoU 为 0.8466,比 [57] 高 20.66%。所有三种建议的方法的召回率和精度都是完全可以接受的。与 ResUNet++ 相比,精度提高了 1.22%。召回率差异可以忽略不计,ResUNet++ 的表现略优于其他产品。
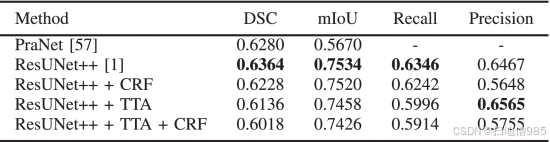
D. ETIS-Larib 息肉数据库的结果比较
表 V 显示了在 ETIS-Larib Polyp DB 上提出的模型的结果。在这种情况下,我们没有将结果与 UNet 和 ResUNet 进行比较,而是直接将模型与 ResUNet++ 进行比较,因为它已经在 Kvasir-SEG 和 CVC-ClinicDB 上显示出卓越的性能 [1]。在这里,ResUNet++、“ResUNet++ + CRF”、“ResUNet++ + TTA”和“ResUNet++ + CRF + TTA”的结果只有微小的差异。然而,ResUNet++ 的最大 DSC 为 0.6364,比 SOTA [57] 提高了 0.84%,mIoU 为 0.7534,比 [57] 提高了 18.64%。ResUNet++ 的召回率为 0.6346,略高于所提出的方法。但是,与 ResUNet++ 相比,ResUNet++ 和 TTA 组合的精度更高。
从结果中,我们可以得出结论,架构的性能是特定于数据的。我们提出的方法在五个独立的数据集上优于 SOTA,然而,ResUNet++ 在 ETIS-Larib 数据集上显示出比组合方法更好的结果。尽管如此,ResUNet++ 和 TTA 组合的精度仍略高于 ResUNet++。需要注意的是,ETIS-Larib 仅包含 196 张图像,其中只有 156 张图像用于训练。即使训练数据集较小,与 SOTA [57] 相比,这些模型的性能也令人满意,在 mIoU 方面有很大的余量,这可以被认为是该算法的优势。
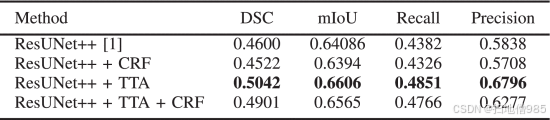
E. Kvasir-Sessile 的结果
由于这是关于 Kvasir-Sessile 的第一项工作,我们将所提出的方法与 ResUNet++ 进行了比较。表 VI 显示,将 ResUNet++ 和 TTA 相结合得到 DSC 为 0.5042,mIoU 为 0.6606,这在较小规模的数据集上可以被认为是一个不错的分数。该数据集包含小型、多样化的图像,这些图像很难用极少的训练样本进行概化。
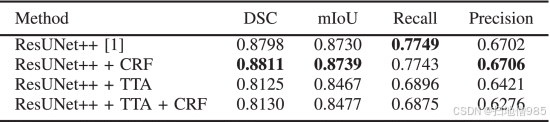
F. CVC-VideoClinicDB 上的结果比较
表 VII 显示了 CVC-VideoClinicDB 上所建议模型的结果。从结果中,我们可以观察到,尽管掩码并非像素完美,但所有模型在数据集上都表现良好。高性能的原因之一是存在 11,954 个息肉和用于训练和测试的正常视频帧。ResUNet++ 和 CRF 的组合获得了 DSC 为 0.8811,mIoU 为 0.8739,召回率为 0.7743,精度为 0.6706,这对于此类数据集的分割任务来说是完全可以接受的。在 CVC-VideoClinicDB 中,真实值用椭圆形或圆形标记。然而,可以理解的是,该数据集的像素精确注释需要内窥镜专家和工程师的大量手动工作。
G. AUS-Mayo ClinicDB 上的结果比较
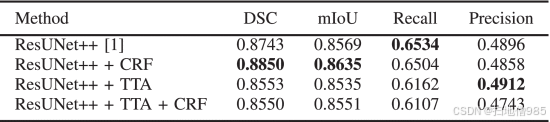
表 VIII 显示了 ASU-Mayo ClinicDB 上所提出的模型的结果。ASU-Mayo 包含 18,781 帧,包括息肉和非息肉图像。ResUNet++ 和 CRF 的组合获得了 0.8850 的 DSC 和 0.8635 的 mIoU。与在真实的临床环境中一样,在这种类型的数据集上训练的模型更有意义(因为它同时包含息肉和非息肉框架)。为这些更具挑战性的数据集实现良好性能的能力是所提出的方法的优势之一。此数据集还包含足够数量的图像来支持足够的训练,这一事实证明了这一点。
H. 混合数据集的结果比较
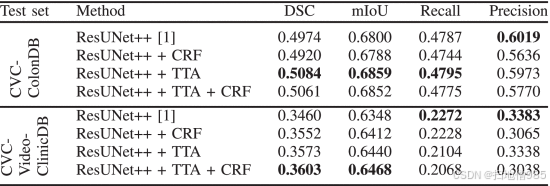
为了检查所提出的方法在使用不同设备捕获的图像上的性能,我们将 Kvasir-SEG 和 CVC-ClinicDB 混合在一起,并将它们用于训练。该模型在 CVC-ColonDB 和 CVC-VideoClinicDB 上进行了测试。表 IX 显示了两个数据集上混合数据集的结果。使用 CVC-ColonDB 时,ResUNet++ 和 TTA 的组合可获得 0.5084 的 DSC 和 0.6859 的 mIoU。ResUNet++ 、 CRF 和 TTA 的组合在 CVC-VideoClinicDB 中获得 DSC 为 0.3603,mIoU 为 0.6468。
从表中,我们可以看到 ResUNet++、CRF 和 TTA 的组合在处理静止图像和视频帧时表现更好或非常有竞争力。在这里,同样明显的是,在不包含非息肉图像的较小数据集(Kvasir-SEG 和 CVC-ClinicDB)上训练的模型在同时包含息肉和非息肉框架的较大和多样化的数据集 (CVC-VideoClinicDB) 上表现不佳。此外,对于 CVC-VideoClinicDB 数据集,提供的地面实况不是完美的(椭圆形/圆形)形状。由于在 Kvasir-SEG 和 CVC-ClinicDB 上训练的模型具有完美的注释,因此该模型擅长预测完美形状的掩码。当我们使用不完美的掩码对 CVC-VideoClinicDB 进行预测时,即使预测很好,由于提供的真实值和预测的掩码不同,分数也可能不高。
I. Kvasir-SEG 的跨数据集结果评估
对于跨数据集评估,我们在 Kvasir-SEG 数据集上训练了模型,并在其他五个独立数据集上对其进行了测试。表 X 显示了单独使用 ResUNet++ 以及使用 CRF 和 TTA 技术的交叉数据泛化的结果。在 Kvasir-SEG 上训练的模型的结果为图像和视频数据集生成的平均最佳 mIoU 为 0.6817,平均最佳 DSC 为 0.4779。从上表中,我们可以观察到所提出的组合方法表现为竞争性。对于图像数据集,ResUNet++ 和 TTA 的组合表现更好,对于视频数据集,ResUNet++、CRF 和 TTA 的组合表现最好。需要注意的是,我们正在训练一个具有 1000 个 Kvasir-SEG 像素分割息肉的模型,并在(例如,11,954 帧)椭圆形息肉的地面实况上进行测试。在这里,即使预测正确,由于椭圆形/圆形的地面实况,评估分数也不会很好。此外,ASU-Mayo 和 CVC-VideoClinicDB 等数据集严重不平衡,但在 Kvasir-SEG 上训练的模型至少包含一个息肉。这也可能导致性能不佳。
J. CVC-ClinicDB 上的跨数据集评估
为了进一步测试泛化性,我们在 CVC-CliniDB 上训练了模型,并在五个独立的、不同的图像和视频数据集中对其进行了测试。表 XI 显示了跨数据泛化的结果。与之前在 Kvasir-SEG 上的测试一样,结果遵循相同的模式,ResUNet++ 和 TTA 的组合在图像数据集上优于其他组合,而 ResUNet++、CRF 和 TTA 的组合在视频数据集上优于其竞争对手。ResUNet++ 和 TTA 仍然具有竞争力。此外,CVC-VideoClinicDB 和 ASU-Mayo Clinic 结肠镜视频数据库的最佳模型的 DSC 和 mIoU 值相似。我们将结果与使用 CVC-CliniDB 进行训练和使用 ETIS-Larib 进行测试的现有工作进行了比较。我们的模型实现了最高的 mIoU 0.6522。
K. 结果摘要
总之,从所有获得的结果(即定性、定量和 ROC 曲线)中,可以得出以下主要观察结果:(i) 提出的 ResUNet++ 能够分割较小、较大和规则的息肉;(ii) ResUNet++ 与 CRF 的组合在同一数据集上训练和测试时,在 DSC、mIoU、召回率和精度方面取得了最佳性能(见表 III、表 VII 和表 VIII),而在其他数据集上测试时仍然具有竞争力;(iii) ResUNet++ 和 TTA 的组合以及 ResUNet++、CRF 和 TTA 的组合对于混合数据集的表现相似;(iv) ResUNet++ 和 TTA 的组合在静止图像上优于其他组合;(v) 与 ResUNet++ 相比,ResUNet++、CRF 和 TTA 的组合在所有视频数据集上都有所改进;(vi) 当图像具有更高的对比度时,所有模型的性能都更好;(vii) ResUNet++ 特别擅长分割较小、扁平或无蒂的息肉,这是开发理想的 CADx 息肉检测系统的先决条件 [1];(viii) ResUNet++ 失败,尤其是在包含称为饱和度或对比度的过度曝光区域的图像上(见图 6);(ix) ResUNet 和 ResUNet-mod 特别显示出过度分割或分割不足的结果(见图 4)。
第六部分。
讨论
A. 一般性能
这些表格和数字表明,应用 CRF 和 TTA 可以提高 ResUNet++ 在相同数据集、混合数据集和跨数据集上的性能。具体来说,ResUNet++ 和 TTA 的组合,以及 ResUNet++、CRF 和 TTA 的组合在所有数据集中都更具泛化性,其中 TTA 与 ResUNet++ 在静止图像上表现最佳,而 ResUNet++、CRF 和 TTA 的组合在视频数据集上优于其他组合。对于所有建议的模型,AUC 的值都大于 0.93。这表明我们的模型擅长区分息肉和非息肉。它还表明该模型产生了足够的灵敏度。
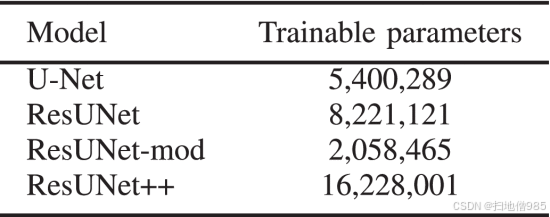
可训练参数的总数通过增加网络中区块的数量而增加(见表 XII)。然而,在 ResUNet++ 中,有显着的性能提升来补偿训练时间,如果我们与使用预训练编码器的模型相比,我们的模型需要的参数更少。
B. 跨数据集性能
交叉数据测试是确定模型泛化能力的出色技术。所介绍的工作是一项旨在提高分割方法的通用性的举措。我们对泛化性的贡献是在一个数据集上进行训练,并在其他几个公共数据集上进行测试,这些数据集可能来自不同中心并使用不同范围制造商。因此,我们推测,为了解决这个问题,必须使用样本外多中心数据来测试构建的方法。这项工作是提出有关方法可解释性问题的一步,我们还提出了有关监督方法的泛化性和域适应的一般问题。
从结果分析中,我们可以看到,不同的算法在不同类型的数据集上表现良好。例如,CRF 在表 III、VII 和 VIII 上的表现优于其他表。TTA 在表 IV、IX 、 X 和 XI 上显示改善。在视频数据集上训练和测试时,CRF 的性能优于 TTA(参见表 VII 和 VIII)。CRF 在大多数图像数据集上也优于 TTA。然而,TTA 仍然具有竞争力。在混合数据集和跨数据集测试中,TTA 在所有数据集上的表现都优于 CRF。在混合数据集和视频的跨数据集测试中,ResUNet++、CRF 和 TTA 的组合仍然是最佳选择(见表 IX、X 和 XI)。在结合 CRF、TTA 以及 CRF 和 TTA 的组合时,性能比 ResUNet++ 有所提高。
但是,与其他方法相比,任何方法的性能都没有显著提高。从结果中,我们可以观察到结果通常是依赖于数据的。然而,由于所提出的方法在视频帧上表现良好,因此在临床上可能会效果更好,因为结肠镜的输出是视频流。因此,在每个数据集上显示所有三种方法的结果变得至关重要。因此,我们提供了大量的实验,展示了成功(图 4、图 5)和失败案例(图 6),并提供了总体分析。
C. 挑战
分割息肉存在一些挑战,例如结肠镜检查期间的肠道质量准备、相机的角度、多余的信息和不同的形态,这些都会影响 DL 模型的整体性能。对于某些图像,内窥镜医师之间的决定甚至存在差异。虽然带有 CRF 和 TTA 的 ResUNet++ 也难以为这些图像生成令人满意的分割图,但它的性能比我们以前的模型要好得多,并且也优于另一种 SOTA 算法。
结肠镜检查的质量在很大程度上取决于内窥镜医师的经验和技能 [23]。我们提出的模型可以通过两种方式提供帮助:(i) 它可用于分割检测到的息肉,为内窥镜医师提供额外的眼睛;(ii) 它对扁平息肉和小息肉都表现良好,这些息肉在内窥镜检查中经常被遗漏。来自上述表格和数字的定性分析(见图 4)和定量分析支持这一论点。这是我们工作的主要优势,使其成为临床试验的候选者。
D. 可能的限制
回顾性设计是本研究的一个可能限制,前瞻性研究是必不可少的,因为不太容易出现偏倚。前瞻性临床评估是必不可少的,因为回顾性研究分析的数据与前瞻性研究不同(例如,应根据最佳情况和最坏情况考虑缺失数据的情况回顾性设计是本研究的一个可能限制,前瞻性研究是必不可少的,因为不太容易出现偏倚。前瞻性临床评估是必不可少的,因为回顾性研究分析的数据与前瞻性研究不同(例如,应根据最佳情况和最坏情况考虑缺失数据的情况此外,这些实验中的所有数据都是经过策划的,而前瞻性临床试验意味着对完整的结肠镜检查视频进行测试。在模型训练期间,我们已将所有图像的大小调整为此外,这些实验中的所有数据都是经过策划的,而前瞻性临床试验意味着对完整的结肠镜检查视频进行测试。在模型训练期间,我们将所有图像的大小调整为 $256\times 256$ 以降低复杂性,这会导致信息丢失,并可能影响整体性能。我们一直在努力优化代码,但可能存在进一步的优化,这可能会提高模型的性能。
结论
在本文中,我们提出了用于语义息肉分割的 ResUNet++ 架构。我们从残差块、ASPP 和 attention 块中受到启发,设计了新颖的 ResUNet++ 架构。此外,我们应用 CRF 和 TTA 以进一步改善结果。我们使用六个公开可用的数据集训练和验证了 ResUNet++ 与 CRF 和 TTA 的组合,并在特定数据集上将结果与 SOTA 算法进行了分析和比较。此外,我们分析了所提出的模型的跨数据泛化性,以开发用于自动息肉分割的可泛化语义分割模型。对在六个不同数据集上训练和测试的所提出的模型进行的综合评估表明,(ResUNet++ 和 CRF) 在图像数据集上和 (ResUNet++ 和 TTA)、(ResUNet++、CRF 和 TTA) 模型在混合数据集和跨数据集上具有良好的性能。此外,对在 Kvasir-SEG 和 CVC-ClinicDB 上训练并在五个独立数据集上测试的模型的跨数据集泛化性的详细研究证实了所提出的 ResUNet++ + TTA 方法用于跨数据集评估的稳健性。
我们方法的优势在于,我们成功地检测到了更小而扁平的息肉,这些息肉在结肠镜检查中经常被遗漏[20]、[61]。我们的模型还可以检测到内窥镜医师如果不仔细调查就难以识别的息肉。因此,我们推测 ResUNet++ 架构以及额外的 CRF 和 TTA 步骤可能是进一步研究的潜在领域之一,尤其是对于被忽视的息肉。我们还指出,模型缺乏泛化问题,在大多数情况下,跨数据集评估的结果不令人满意就证明了这一点。将来,我们的 CADx 系统也应该针对其他肠道疾病进行研究。此外,需要进行前瞻性临床试验以证明拟议系统的有用性。