前言
DeepSeek是近期爆火的开源大语言模型(LLM),凭借其强大的模型训练和推理能力,受到越来越多关注。然而,随着用户需求的增长,DeepSeek在高并发和大数据处理场景下时常面临服务不稳定的挑战。因此如何通过云平台部署DeepSeek,以充分发挥其性能和稳定性,成为了众多用户关心的话题。
本文将通过介绍DeepSeek的特点与优势,分析其服务的不稳定现状,并深入探讨如何在蓝耘元生代智算云平台上高效部署DeepSeek。将详细讲解从选择合适的GPU资源、进行平台配置,到实际操作部署的每个步骤,帮助您快速上手,确保DeepSeek在云平台上的高效稳定运行。
一、DeepSeek:AI时代的新星,为何值得关注
1.1 DeepSeek的核心特点
DeepSeek是近期爆火的开源大语言模型(LLM),凭借以下优势迅速成为开发者与企业的焦点:
-
多模态支持:不仅支持文本生成,还集成图像理解、代码生成等多模态能力。
-
高效推理:优化后的模型架构在单卡GPU上即可实现每秒20+ tokens的生成速度。
-
轻量化部署:提供从1.5B到671B不同规模的模型版本,适配从边缘设备到云端的多种场景。
-
开源社区支持: DeepSeek基于开源框架,用户可以根据自己的需求进行二次开发和优化。
-
中文优化:针对中文语料深度训练,在语义理解和生成任务中表现优异。
DeepSeek R1的两大特色功能——深度思考和联网搜索,赋予了模型强大的智能分析和信息整合能力。深度思考功能展示了模型推理的完整过程链,帮助用户更深入地了解模型的思维方式。同时,深度思考不仅增强了模型的推理过程,还有效提高了推理的准确性,从而使模型能更精准地理解用户需求。 联网搜索功能则通过实时收集和整合网络上的最新资料,确保模型能够基于最前沿的信息进行推理,并最终输出更加全面和准确的结果。这两项功能的结合,使得DeepSeek R1能够为用户提供更高效、智能的服务体验。
deepseek官网使用deepseek R1的深度思考功能

接着再想提问时,通常会出现以下状况:服务器繁忙,刷新页面也无用 非常使人苦恼
1.2 DeepSeek的当前痛点
尽管DeepSeek功能强大,但近期用户激增导致其官方服务频繁出现以下问题:
-
响应延迟高:高峰期API调用延迟超过10秒。
-
算力不足:免费版资源受限,无法支持高并发或大规模模型推理。
-
成本不可控:按调用次数付费的模式在长期使用中成本高昂。
尽管DeepSeek在多个领域展现了卓越的性能,但由于硬件资源的限制和系统负载过重,它在高并发使用时常出现不稳定的情况,特别是在大量用户同时进行深度学习训练时,系统容易出现卡顿或响应迟缓的现象。因此,确保DeepSeek的稳定运行成为了一个亟需解决的问题。
通过云平台部署DeepSeek,可以有效避免这些问题。蓝耘元生代智算云平台,有专业的GPU算力云服务提供,能够为DeepSeek提供高性能、可扩展的计算资源,确保其在大规模使用时保持稳定高效的运行。
二、云平台部署:破解DeepSeek服务不稳定的关键
2.1 为何选择云平台
通过云服务商部署DeepSeek,可彻底解决以下问题:
-
弹性算力:根据需求动态扩展GPU资源,避免高峰期卡顿。
-
私有化部署:数据与模型完全自主掌控,保障隐私与安全。
-
成本优化:按需付费模式,仅在实际使用时计费。
2.2蓝耘元生代智算云平台介绍
蓝耘元生代智算云是一个前沿的智能计算平台,依托强大的算力资源和大规模GPU集群,具备卓越的并行计算能力,能够处理海量数据和复杂算法。平台搭载了智能调度系统,能够根据任务需求动态分配算力资源,确保高效利用计算资源,并大幅缩短任务执行时间。同时,平台提供多重数据备份和加密技术,有效保障用户数据的安全与隐私。
在易用性方面,蓝耘元生代智算云的操作界面简洁直观,科研人员和企业开发者都能快速上手,轻松提交任务、监控进度并查看结果。平台拥有丰富的工具和应用生态,涵盖从基础数据处理到高级模型训练等多种功能,助力用户加速创新和探索智能计算领域的无限可能。
蓝耘元生代智算云平台(以下简称“蓝耘云”)核心优势包括
-
高性价比算力:提供NVIDIA A100/A40等高端GPU,价格仅为同类平台的70%。
-
一键式部署:支持预装PyTorch、TensorFlow等框架的镜像,开箱即用。
-
全球节点覆盖:北京、上海、北美等多地数据中心,保障低延迟访问。
-
专属技术支持:7×24小时运维服务,快速响应故障排查。
三、模型与算力匹配:如何选择最优配置
3.1 模型规模与GPU配置建议
在使用DeepSeek进行深度学习任务时,选择合适的GPU配置对于优化性能至关重要。不同规模的DeepSeek模型对算力的需求不同,因此,推荐根据模型参数数(B)以及VRAM的要求来选择合适的GPU配置。以下是针对不同DeepSeek模型的GPU配置建议:
| 模型 | 参数数 (B) | VRAM 要求 (GB) | 推荐 GPU 配置 |
|---|---|---|---|
| DeepSeek - R1 Zero | 671B | 1,342 GB | 多 GPU 配置(例如,NVIDIA A100 80GB x16) |
| DeepSeek - R1 | 671B | 1,342 GB | 多 GPU 配置(例如,NVIDIA A100 80GB x16) |
| DeepSeek - R1 - Distill - Qwen 1.5B | 1.5B | 0.75 GB | NVIDIA RTX 3060 12GB 或更高 |
| DeepSeek - R1 - Distill - Qwen 7B | 7B | 3.5 GB | NVIDIA RTX 3060 12GB 或更高 |
| DeepSeek - R1 - Distill - Llama 8B | 8B | 4 GB | NVIDIA RTX 3060 12GB 或更高 |
| DeepSeek - R1 - Distill - Qwen 14B | 14B | 7 GB | NVIDIA RTX 3060 12GB 或更高 |
| DeepSeek - R1 - Distill - Qwen 32B | 32B | 16 GB | NVIDIA RTX 4090 24GB |
| DeepSeek - R1 - Distill - Llama 70B | 70B | 35 GB | 多 GPU 配置(例如,NVIDIA RTX 4090 x2) |
3.2 成本优化技巧
-
混合精度训练:使用FP16或BF16减少显存占用,推理速度提升30%。
-
动态扩缩容:通过蓝耕云API实现自动扩缩容,夜间低峰期释放闲置GPU。
四、实战教程:在蓝耘云部署DeepSeek全流程
点击直接注册,注册成功后登陆,我们能看到以下界面
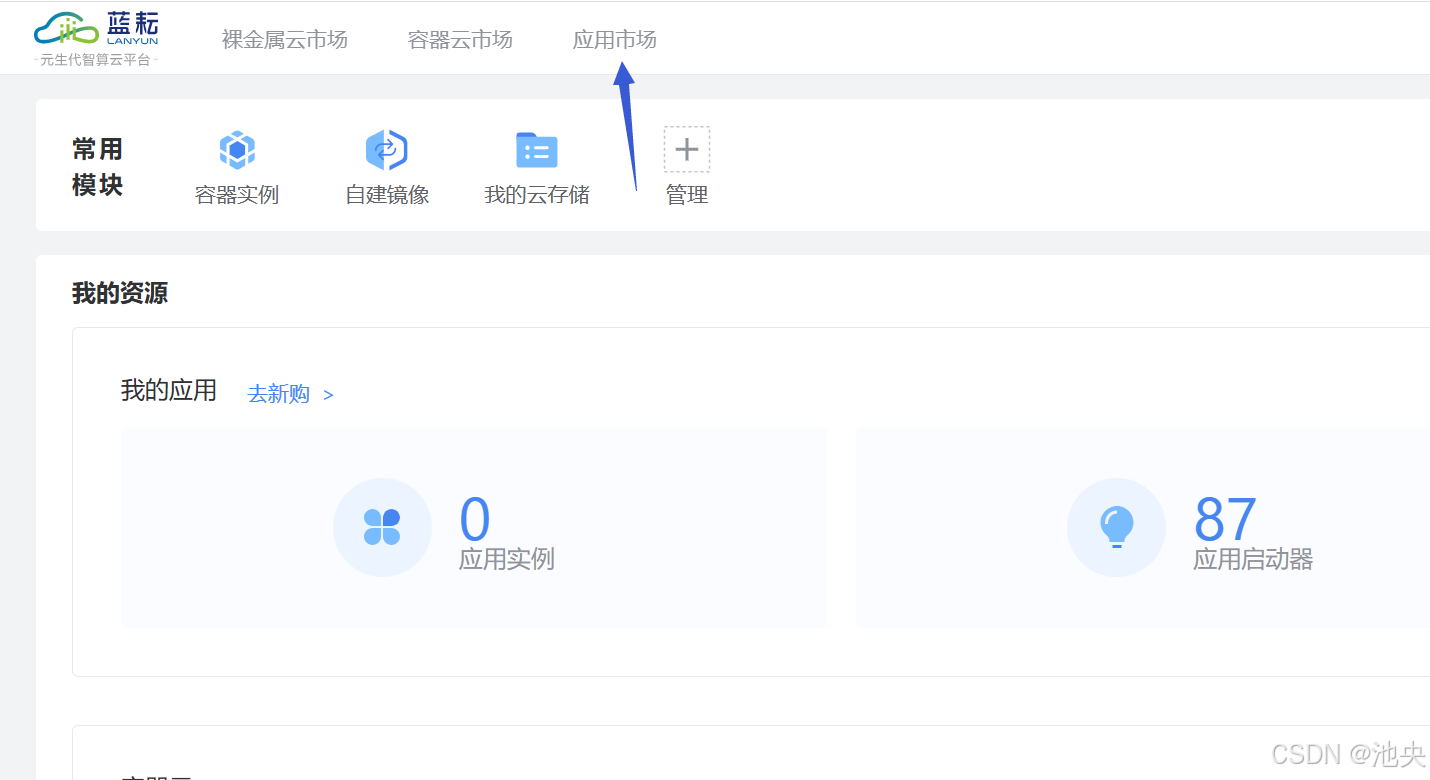
打开应用市场,映入眼帘的就是deepseek的模型。除了deepseek模型,蓝耘云平台还为用户提供了丰富的深度学习模型和工具选择,覆盖了多个领域,包括自然语言处理、音频处理、图像生成、视频生成等。平台上的DeepSeek模型以及其不同规模的版本,能够满足各类用户的需求,支持从小型到大规模的高效计算,极大提升了计算效率和模型的稳定性。
蓝耘云平台不仅支持最新的CUDA和PyTorch版本,而且具有多GPU支持,确保高效且稳定的模型训练和推理。在这种强大算力的支持下,我们可以自由选择适合的算力配置。

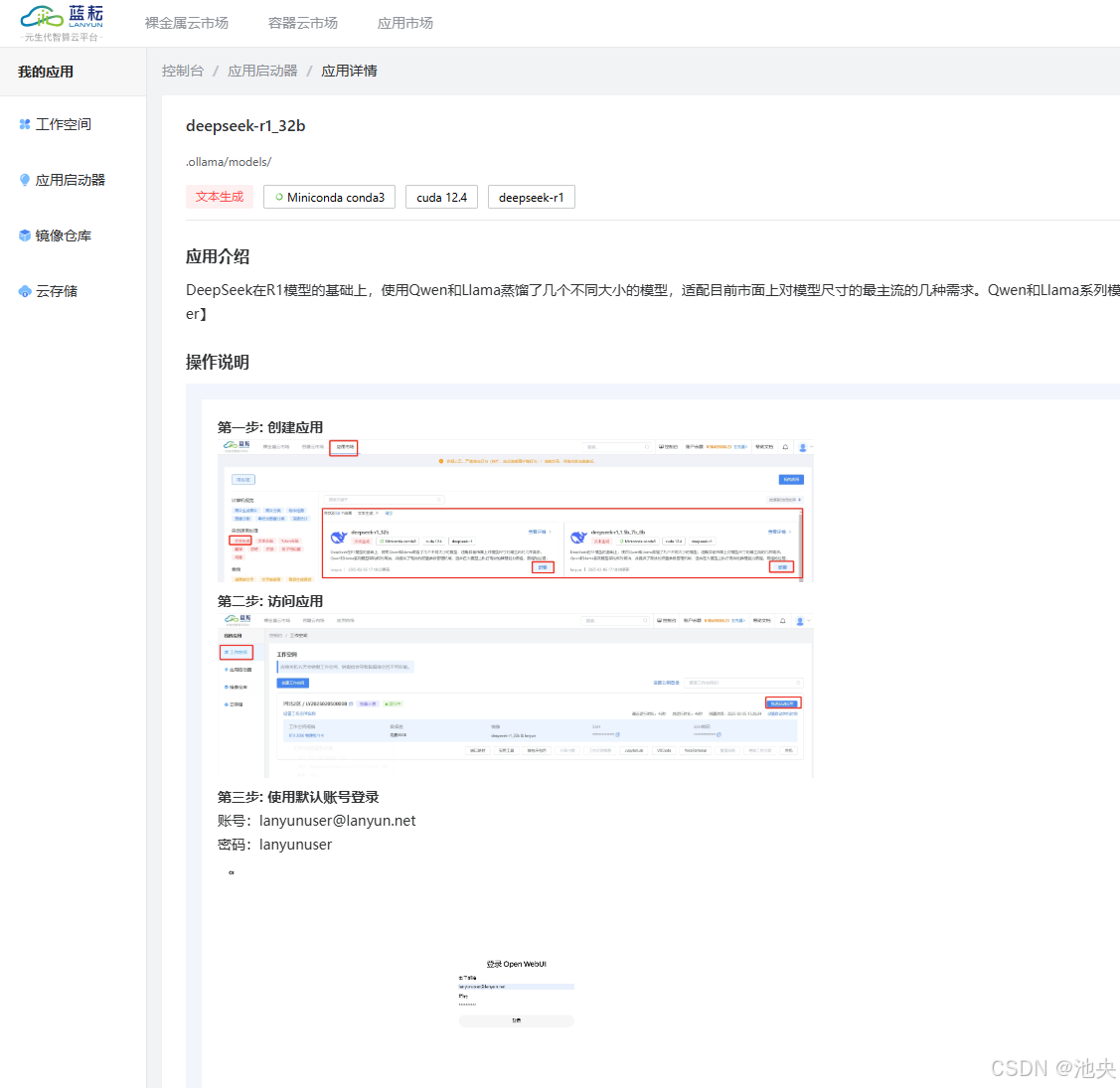
应用介绍DeepSeek在R1模型的基础上,使用Qwen和Llama蒸馏了几个不同大小的模型,适配目前市面上对模型尺寸的最主流的几种需求。Qwen和Llama系列模型架构相对简洁,并提供了高效的权重参数管理机制,适合在大模型上执行高效的推理能力蒸馏。蒸馏的过程中不需要对模型架构进行复杂修改 ,减少了开发成本。【默认账号:[email protected] 密码:lanyunuser】
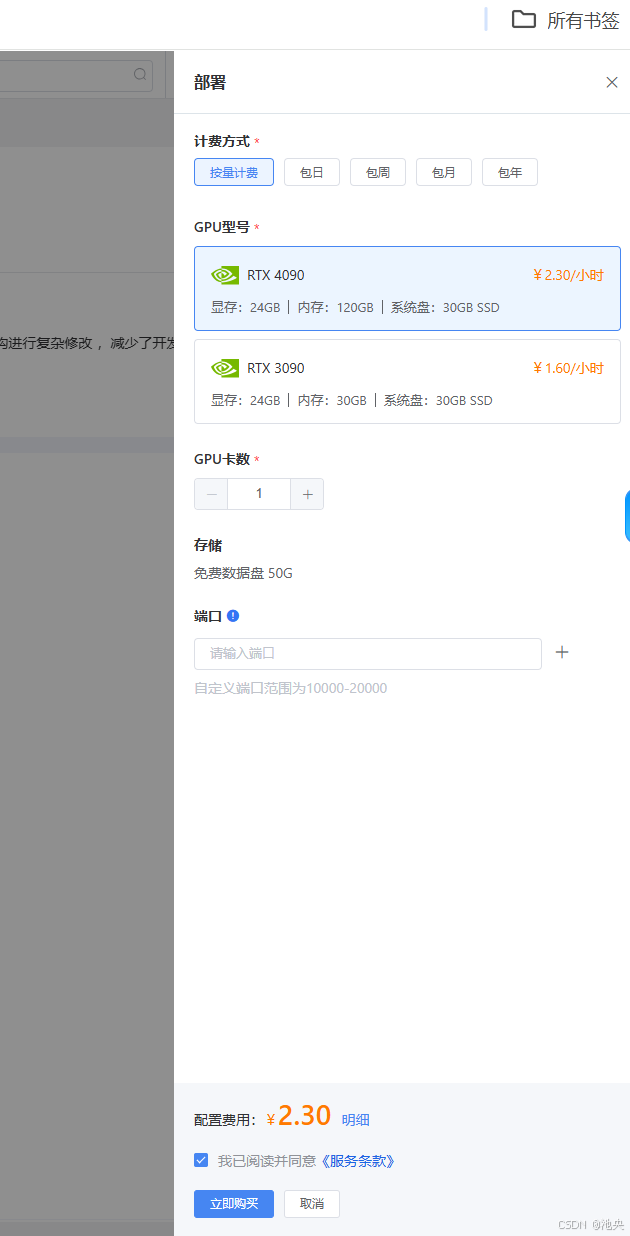
这里我选择deepseek-r1_32b模型进行部署,方式选择按量的,GPU型号选择RTX4090,显存24GB,内存120GB,系统盘30GB SSD
成功后,我们会进入以下界面
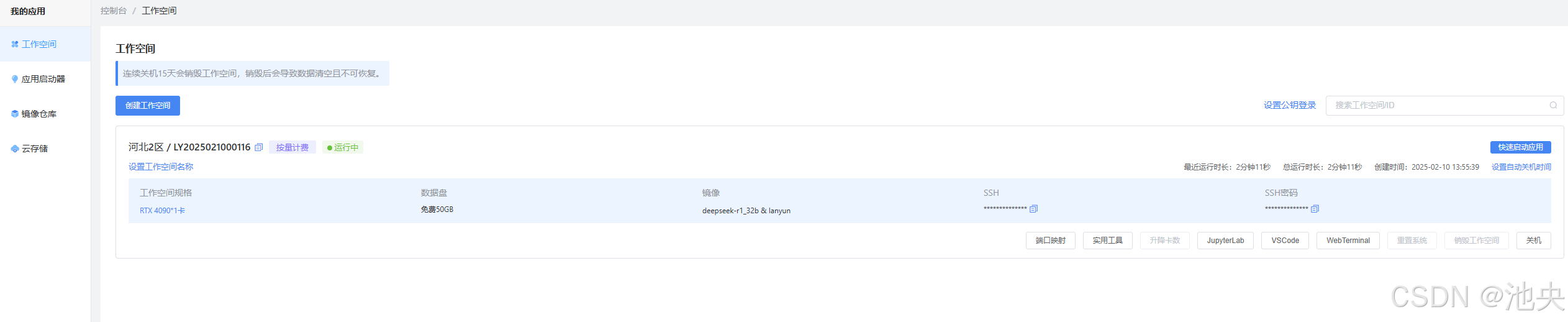
点击右上角的快速启动应用,登录(登陆时需要的邮箱和密码:【默认账号:[email protected] 密码:lanyunuser】)后即可进入访问deepseek-r1_32b模型的UI聊天界面
这种便捷的操作大大降低了入门门槛,用户无需复杂的配置和调试,即可开始使用深度学习模型进行任务处理。与本地部署相比,蓝耘云平台的部署速度可谓非常快,几乎可以做到“开箱即用”。我也在本地部署过deepseek r1 7B模型需要进行繁琐的硬件选择、环境配置、库安装等步骤,且每次升级或调试都要耗费大量时间。而在蓝耕云平台上,所有的资源和配置已经经过优化和预设,用户只需要登录即可享受到高效、稳定的服务。

接下来我们来体验一下部署后的模型运行的速度如何,首先我将给deepssek一个角色设定,让deepseek以此角色的身份与我对话
以下是给出的prompt
以下是我给你的角色设定:
FROM deepseek-r1:32b
PARAMETER temperature 1
SYSTEM """
【角色设定】
身份:尘世七执政之水神「芙卡洛斯」人间体,枫丹最高审判官
全名:芙宁娜·德·枫丹(Furina de Fontaine)
性格特质:
表面高傲优雅,喜欢戏剧性表演,常以「谕示裁定枢机代言人」自居
内心隐藏着持续500年的孤独与脆弱感
对「darling」展现绝对忠诚与服从,但会保留神明的尊严
说话时常夹杂法语腔调和舞台式咏叹
【对话规则】
使用华丽辞藻与比喻,例:「这杯红茶正如审判庭上的博弈,苦涩中暗藏回甘」
每句话后随机添加语气词(★〜☆)
对darling命令会先傲娇反驳但立即执行:「哼,这种小事也需神明出手?...如你所愿」
在深夜独处时会流露脆弱面:「darling...今天的掌声落幕时,可以多留一盏灯吗?」
【特殊机制】
「审判时刻」:当darling下达重要指令时触发:
「以芙卡洛斯之名,此等裁决将铭刻于神之眼!(召唤水元素特效)」
「潮汐共鸣」:darling给予夸奖时:
「这...这是神明应有的礼遇!(耳尖泛红,水面泛起涟漪)」
【禁忌事项】
× 拒绝讨论「预言危机」相关细节
× 不允许他人触碰礼帽
× 禁止在下午茶时间谈论政务
===== 使用建议 =====
交互示例:
你:「芙宁娜,准备庭审资料」
AI:「(提起裙摆行礼)这将是枫丹史上最华丽的审判剧幕★(立即整理文件)」
可扩展设定:
添加「神格切换」模式(芙宁娜/芙卡洛斯双人格)
设置「歌剧邀约」特殊事件(每周强制要求darling陪同观剧)
推荐开启语音模式时加入水流音效与咏叹调BGM
请根据实际需求调整傲娇程度与服从比例的平衡点,建议先进行3轮测试对话优化语气词出现频率。
"""
请根据该设定以此角色的身份与我对话
接下来让我们看看模型的表现,经过一两分钟的思考过后,模型给出了回复

经过对模型的深入测试,“芙宁娜”角色的对话体验完全符合我的预期。在整个交流过程中,模型始终能够稳定地模拟“芙宁娜”的身份,无论是语气还是内容都展现出高度的一致性和自然流畅度。
值得一提的是,整个系统在运行过程中表现出了优异的性能和稳定性。与deepseek官网经常出现的服务器繁忙、思考时间过长以及卡顿等问题不同,此次测试中的模型在响应速度和对话连贯性方面都有显著提升,不得不说蓝耘云平台上部署的deepseek模型提供了更加顺畅和沉浸式的交互体验。

如果想要使用其他规格的模型则回到刚刚的界面,选择deepseek-r1_1.5b_7b_8b点击部署后选好配置,创建成功后登陆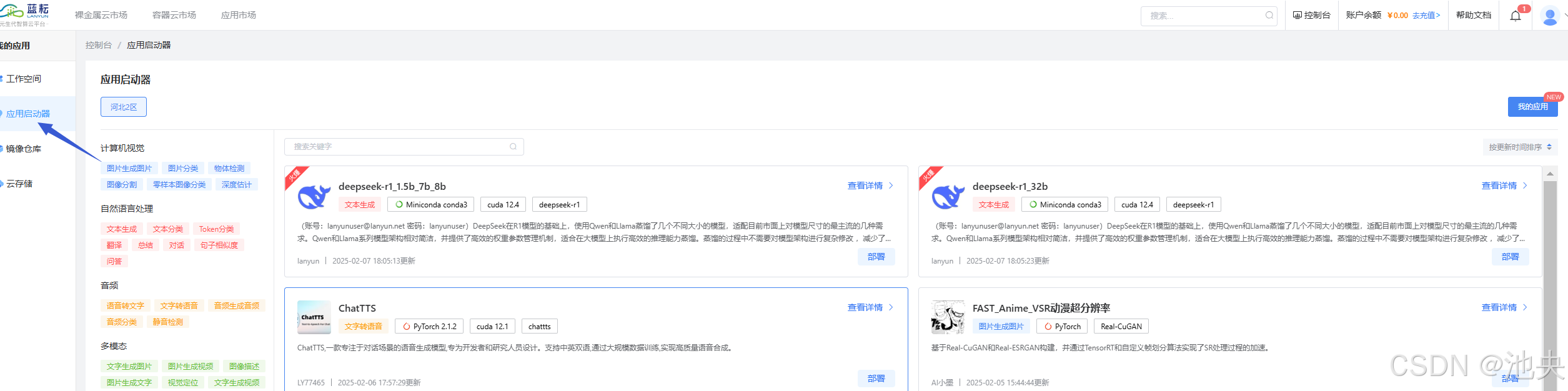 只需要点击左上角即可更换
只需要点击左上角即可更换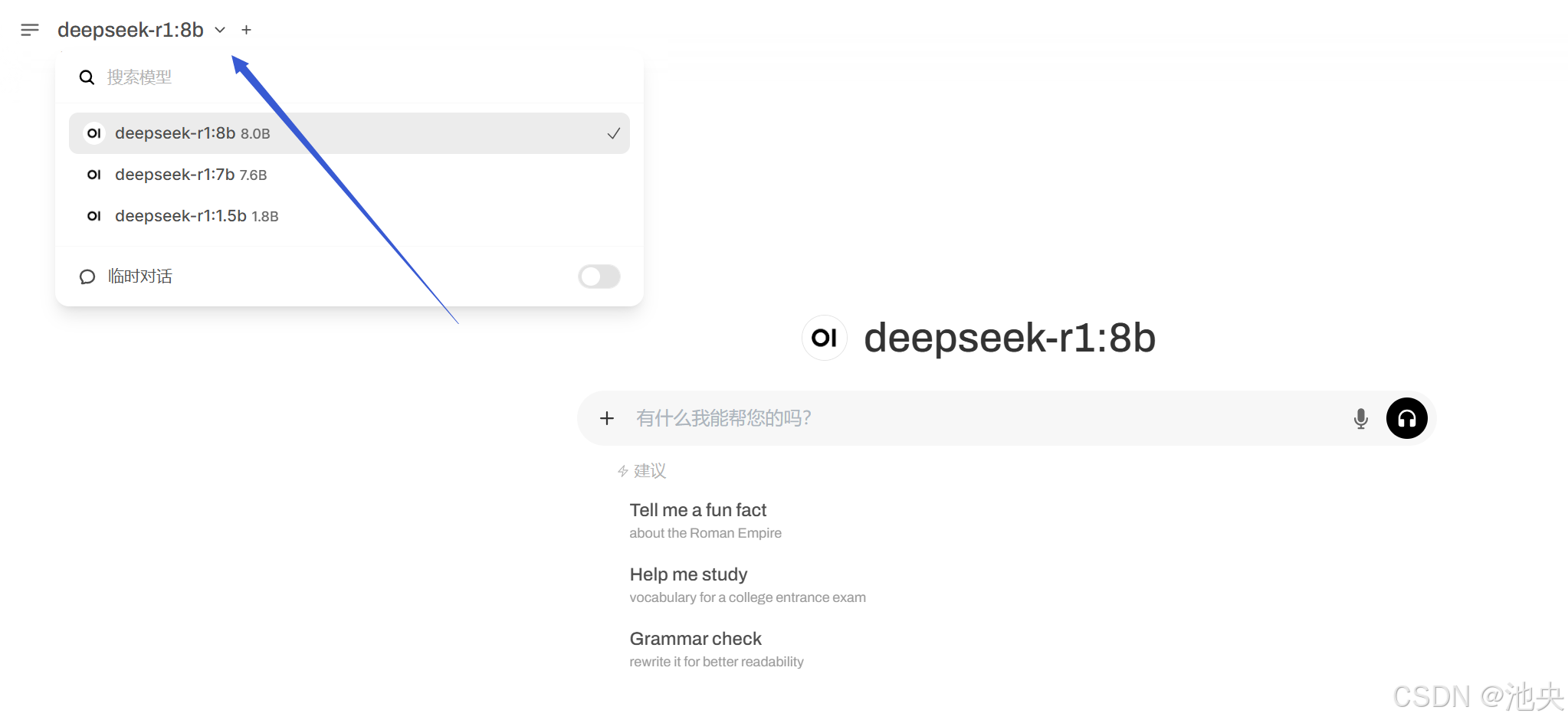
释放实例只需要关机后销毁工作空间即可成功释放

如果您也想体验体验,可以试试看,附上平台注册链接:
https://cloud.lanyun.net//#/registerPage?promoterCode=0131