欢迎拜访:雾里看山-CSDN博客
本篇主题:算法思想之滑动窗口(二)
发布时间:2025.4.7
隶属专栏:算法

目录
滑动窗口算法介绍
滑动窗口是一种用于处理数组/字符串子区间问题的高效算法,通过维护动态窗口减少重复计算,将时间复杂度从暴力法的 O(n²) 优化至 O(n)。
核心思想
- 窗口定义:用两个指针(
left和right)表示当前处理的区间[left, right]。 - 窗口移动:根据问题规则,右指针扩展窗口,左指针收缩窗口,动态调整窗口大小。
- 核心优势:避免重复遍历元素,每个元素最多被访问两次。
时间复杂度
O(n),左右指针各遍历一次数组。
适用场景
- 子数组/子串的极值问题(最大、最小)。
- 需要统计满足条件的连续元素序列。
- 窗口内元素满足单调性或有明确的收缩规则。
注意事项
- 边界处理:空输入、窗口大于数组长度等情况。
- 数据结构选择:根据问题使用哈希表、数组等记录窗口状态。
- 负数处理:如求最大子数组和时,可能需要动态调整窗口起始位置(此时需结合前缀和或 Kadane 算法)。
例题
水果成篮
题目链接
题目描述
你正在探访一家农场,农场从左到右种植了一排果树。这些树用一个整数数组
fruits表示,其中fruits[i]是第i棵树上的水果 种类 。
你想要尽可能多地收集水果。然而,农场的主人设定了一些严格的规矩,你必须按照要求采摘水果:
- 你只有 两个 篮子,并且每个篮子只能装 单一类型 的水果。每个篮子能够装的水果总量没有限制。
- 你可以选择任意一棵树开始采摘,你必须从 每棵 树(包括开始采摘的树)上 恰好摘一个水果 。采摘的水果应当符合篮子中的水果类型。每采摘一次,你将会向右移动到下一棵树,并继续采摘。
- 一旦你走到某棵树前,但水果不符合篮子的水果类型,那么就必须停止采摘。
给你一个整数数组
fruits,返回你可以收集的水果的 最大 数目。
示例 1:输入:fruits = [1,2,1]
输出:3
解释:可以采摘全部 3 棵树。示例 2:
输入:fruits = [0,1,2,2]
输出:3
解释:可以采摘 [1,2,2] 这三棵树。
如果从第一棵树开始采摘,则只能采摘 [0,1] 这两棵树。示例 3:
输入:fruits = [1,2,3,2,2]
输出:4
解释:可以采摘 [2,3,2,2] 这四棵树。
如果从第一棵树开始采摘,则只能采摘 [1,2] 这两棵树。示例 4:
输入:fruits = [3,3,3,1,2,1,1,2,3,3,4]
输出:5
解释:可以采摘 [1,2,1,1,2] 这五棵树。提示:
1 <= fruits.length <= 1050 <= fruits[i] < fruits.length
算法思路
研究的对象是一段连续的区间,可以使用滑动窗口思想来解决问题。
让滑动窗口满足:窗口内水果的种类只有两种。
做法:右端水果进入窗口的时候,用哈希表统计这个水果的频次。这个水果进来后,判断哈希表的大小:
- 如果大小超过 2:说明窗口内水果种类超过了两种。那么就从左侧开始依次将水果划出窗口,直到哈希表的大小小于等于 2,然后更新结果;
- 如果没有超过 2,说明当前窗口内水果的种类不超过两种,直接更新结果 ret。
代码实现
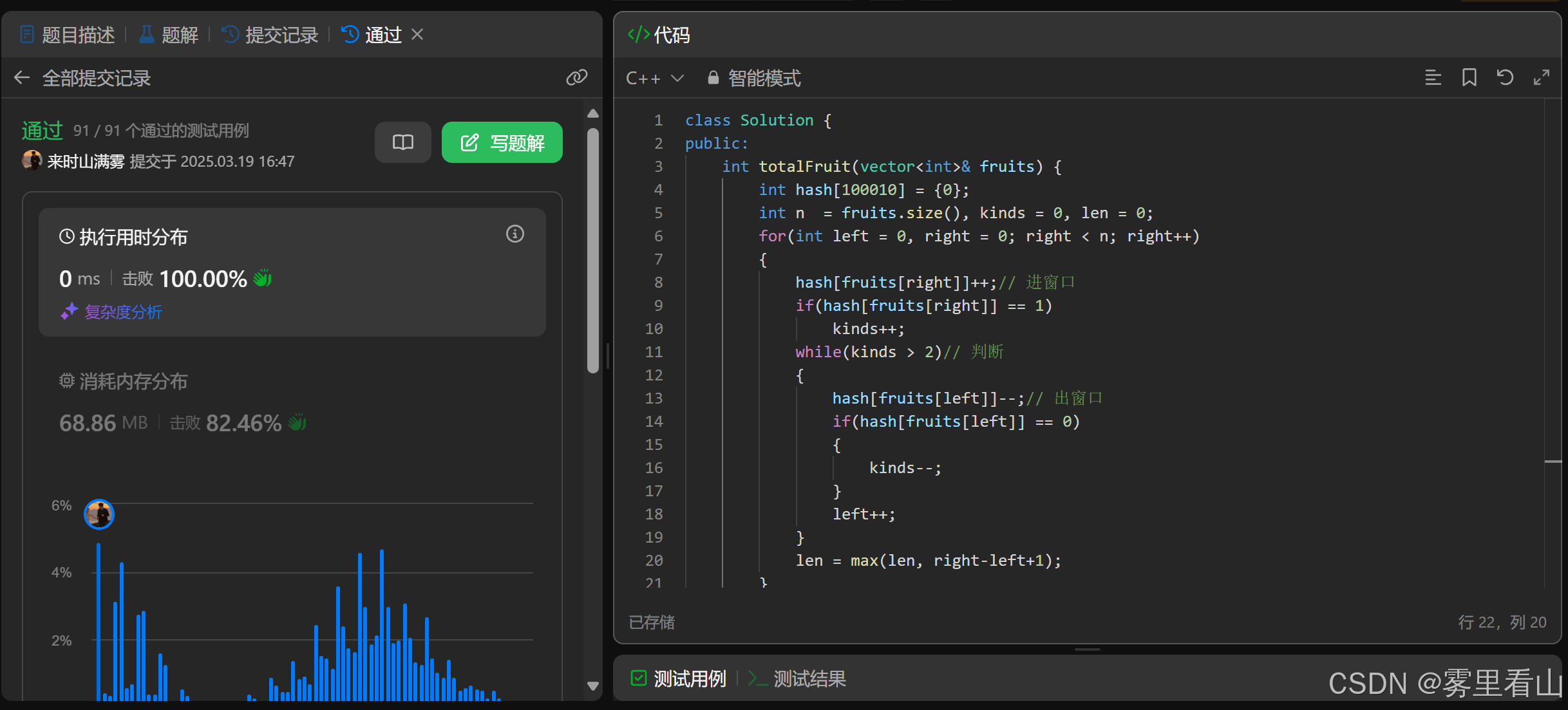
class Solution {
public:
int totalFruit(vector<int>& fruits) {
int hash[100010] = {
0};
int n = fruits.size(), kinds = 0, len = 0;
for(int left = 0, right = 0; right < n; right++)
{
hash[fruits[right]]++;// 进窗口
if(hash[fruits[right]] == 1)
kinds++;
while(kinds > 2)// 判断
{
hash[fruits[left]]--;// 出窗口
if(hash[fruits[left]] == 0)
{
kinds--;
}
left++;
}
len = max(len, right-left+1);
}
return len;
}
};
找到字符串中所有字母异位词
题目链接
题目描述
给定两个字符串
s和p,找到s中所有p的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
示例 1:输入: s = “cbaebabacd”, p = “abc”
输出: [0,6]
解释:
起始索引等于 0 的子串是 “cba”, 它是 “abc” 的异位词。
起始索引等于 6 的子串是 “bac”, 它是 “abc” 的异位词。示例 2:
输入: s = “abab”, p = “ab”
输出: [0,1,2]
解释:
起始索引等于 0 的子串是 “ab”, 它是 “ab” 的异位词。
起始索引等于 1 的子串是 “ba”, 它是 “ab” 的异位词。
起始索引等于 2 的子串是 “ab”, 它是 “ab” 的异位词。提示:
1 <= s.length, p.length <= 3 * 104s和p仅包含小写字母
算法思路
- 因为字符串
p的异位词的长度一定与字符串p的长度相同,所以我们可以在字符串s中构造一个长度为与字符串p的长度相同的滑动窗口,并在滑动中维护窗口中每种字母的数量; - 当窗口中每种字母的数量与字符串
p中每种字母的数量相同时,则说明当前窗口为字符串p的异位词; - 因此可以用两个大小为
26的数组来模拟哈希表,一个来保存s中的子串每个字符出现的个数,另一个来保存p中每一个字符出现的个数。这样就能判断两个串是否是异位词。
代码实现
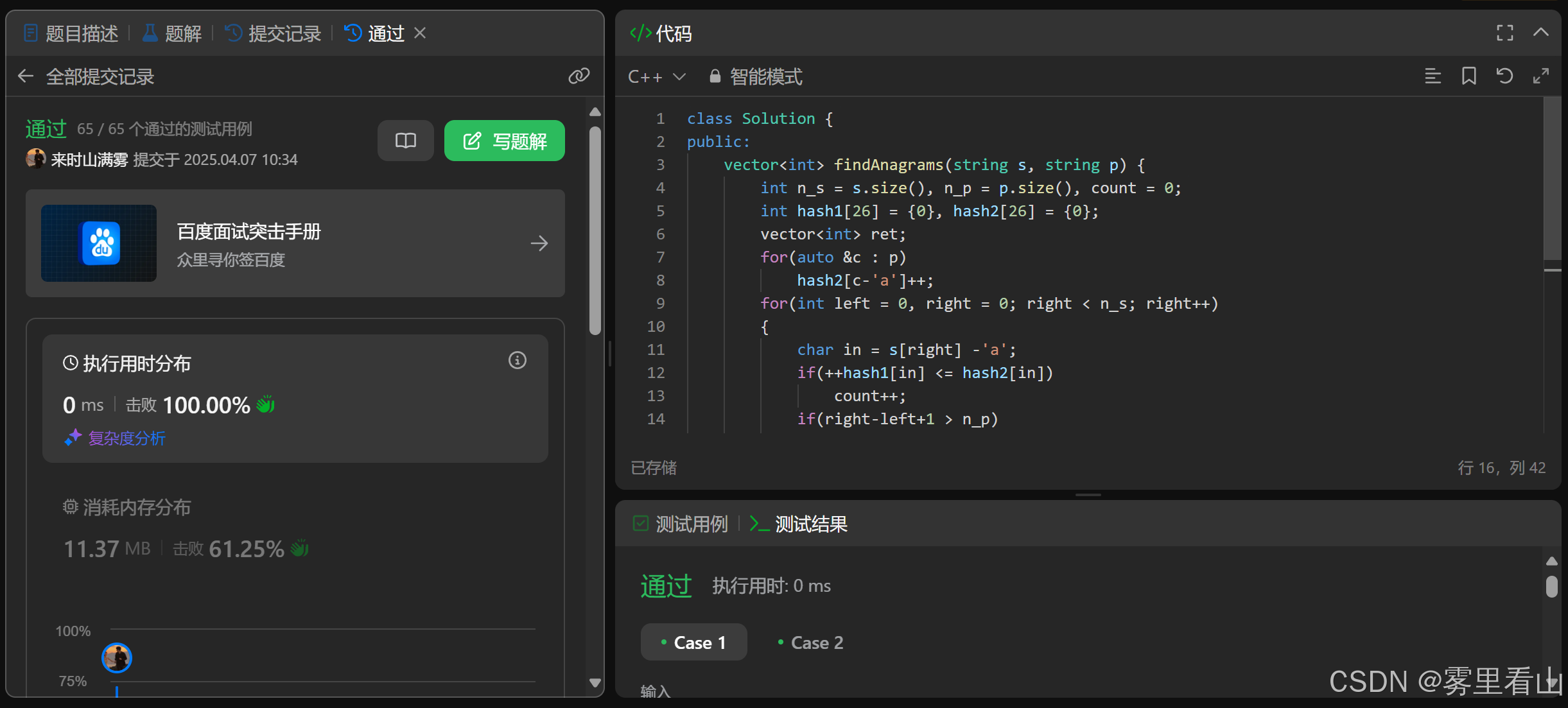
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
int n_s = s.size(), n_p = p.size(), count = 0;
int hash1[26] = {
0}, hash2[26] = {
0};
vector<int> ret;
for(auto &c : p)
hash2[c-'a']++;
for(int left = 0, right = 0; right < n_s; right++)
{
char in = s[right] -'a';
if(++hash1[in] <= hash2[in])
count++;
if(right-left+1 > n_p)
{
char out = s[left++]-'a';
if(hash1[out]-- <= hash2[out])
count--;
}
if(count == n_p)
ret.push_back(left);
}
return ret;
}
};
串联所有单词的子串
题目链接
题目描述
给定一个字符串
s和一个字符串数组words。words中所有字符串 长度相同。
s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。
- 例如,如果
words = ["ab","cd","ef"], 那么"abcdef","abefcd","cdabef","cdefab","efabcd", 和"efcdab"都是串联子串。"acdbef"不是串联子串,因为他不是任何words排列的连接。返回所有串联子串在
s中的开始索引。你可以以 任意顺序 返回答案。
示例 1:输入:s = “barfoothefoobarman”, words = [“foo”,“bar”]
输出:[0,9]
解释:因为 words.length == 2 同时 words[i].length == 3,连接的子字符串的长度必须为 6。
子串 “barfoo” 开始位置是 0。它是 words 中以 [“bar”,“foo”] 顺序排列的连接。
子串 “foobar” 开始位置是 9。它是 words 中以 [“foo”,“bar”] 顺序排列的连接。
输出顺序无关紧要。返回 [9,0] 也是可以的。示例 2:
输入:s = “wordgoodgoodgoodbestword”, words = [“word”,“good”,“best”,“word”]
输出:[]
解释:因为 words.length == 4 并且 words[i].length == 4,所以串联子串的长度必须为 16。
s 中没有子串长度为 16 并且等于 words 的任何顺序排列的连接。
所以我们返回一个空数组。示例 3:
输入:s = “barfoofoobarthefoobarman”, words = [“bar”,“foo”,“the”]
输出:[6,9,12]
解释:因为 words.length == 3 并且 words[i].length == 3,所以串联子串的长度必须为 9。
子串 “foobarthe” 开始位置是 6。它是 words 中以 [“foo”,“bar”,“the”] 顺序排列的连接。
子串 “barthefoo” 开始位置是 9。它是 words 中以 [“bar”,“the”,“foo”] 顺序排列的连接。
子串 “thefoobar” 开始位置是 12。它是 words 中以 [“the”,“foo”,“bar”] 顺序排列的连接。提示:
1 <= s.length <= 1041 <= words.length <= 50001 <= words[i].length <= 30words[i]和s由小写英文字母组成
算法思路
如果我们把每一个单词看成一个一个字母,问题就变成了找到字符串中所有的字母异位词。无非就是之前处理的对象是一个一个的字符,我们这里处理的对象是一个一个的单词。
代码实现
class Solution {
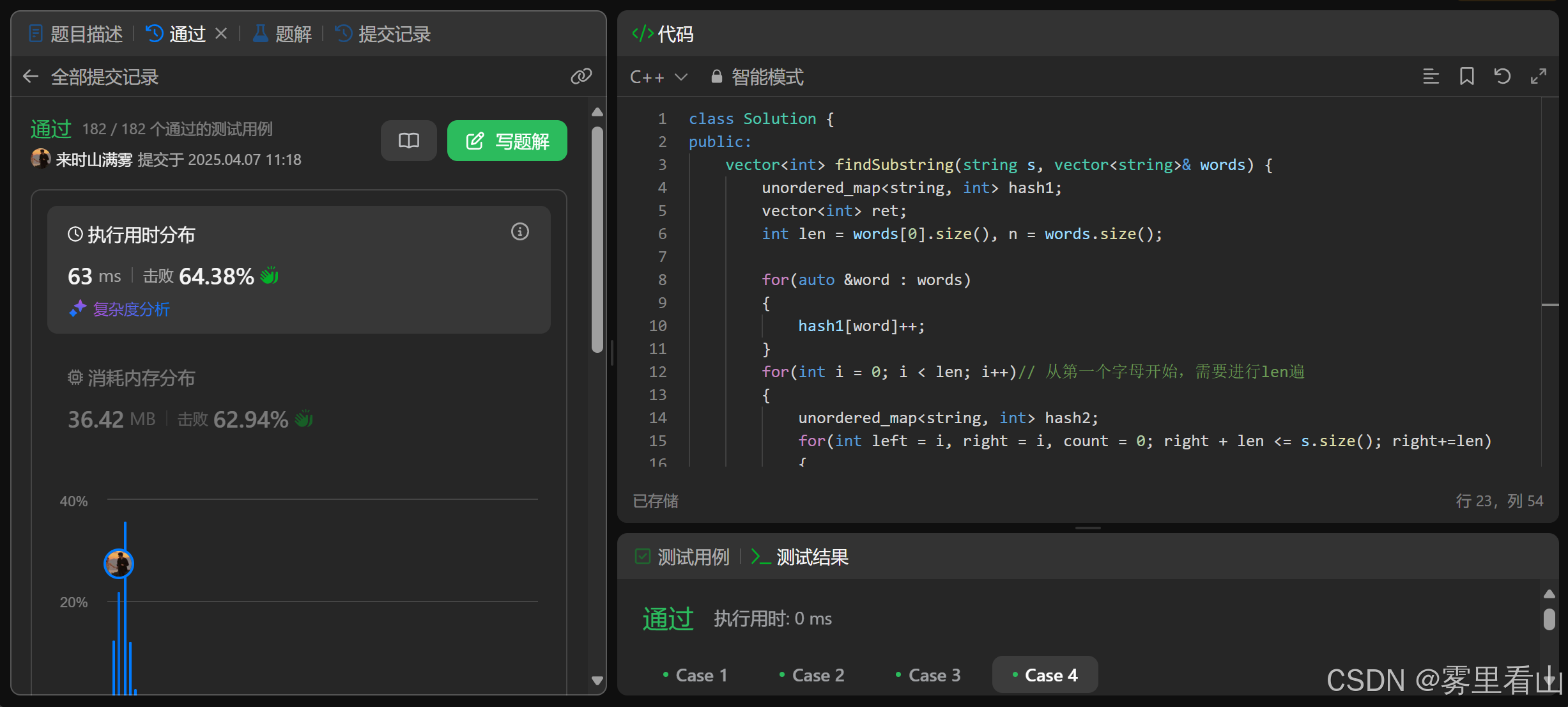
public:
vector<int> findSubstring(string s, vector<string>& words) {
unordered_map<string, int> hash1;
vector<int> ret;
int len = words[0].size(), n = words.size();
for(auto &word : words)
{
hash1[word]++;
}
for(int i = 0; i < len; i++)// 从第一个字母开始,需要进行len遍
{
unordered_map<string, int> hash2;
for(int left = i, right = i, count = 0; right + len <= s.size(); right+=len)
{
string in = s.substr(right,len);
hash2[in]++;
if(hash1.count(in) && hash1[in] >= hash2[in])
count++;
if(right-left+1 > n*len)
{
string out = s.substr(left, len);
if(hash1.count(out) && hash1[out] >= hash2[out])
count--;
hash2[out]--;
left+=len;
}
if(count == n)
ret.push_back(left);
}
}
return ret;
}
};
最小覆盖子串
题目链接
题目描述
给你一个字符串
s、一个字符串t。返回s中涵盖t所有字符的最小子串。如果s中不存在涵盖t所有字符的子串,则返回空字符串""。
注意:
- 对于
t中重复字符,我们寻找的子字符串中该字符数量必须不少于t中该字符数量。- 如果
s中存在这样的子串,我们保证它是唯一的答案。示例 1:
输入:s = “ADOBECODEBANC”, t = “ABC”
输出:“BANC”
解释:最小覆盖子串 “BANC” 包含来自字符串 t 的 ‘A’、‘B’ 和 ‘C’。示例 2:
输入:s = “a”, t = “a”
输出:“a”
解释:整个字符串 s 是最小覆盖子串。示例 3:
输入: s = “a”, t = “aa”
输出: “”
解释: t 中两个字符 ‘a’ 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。提示:
m == s.lengthn == t.length1 <= m, n <= 105s和t由英文字母组成进阶:你能设计一个在 o(m+n) 时间内解决此问题的算法吗?
算法思路
研究对象是连续的区间,因此可以尝试使用滑动窗口的思想来解决。
如何判断当前窗口内的所有字符是符合要求的呢?
- 我们可以使用两个哈希表,其中一个将目标串的信息统计起来,另一个哈希表动态的维护窗口内字符串的信息。
- 当动态哈希表中包含目标串中所有的字符,并且对应的个数都不小于目标串的哈希表中各个字符的个数,那么当前的窗口就是一种可行的方案。
代码实现
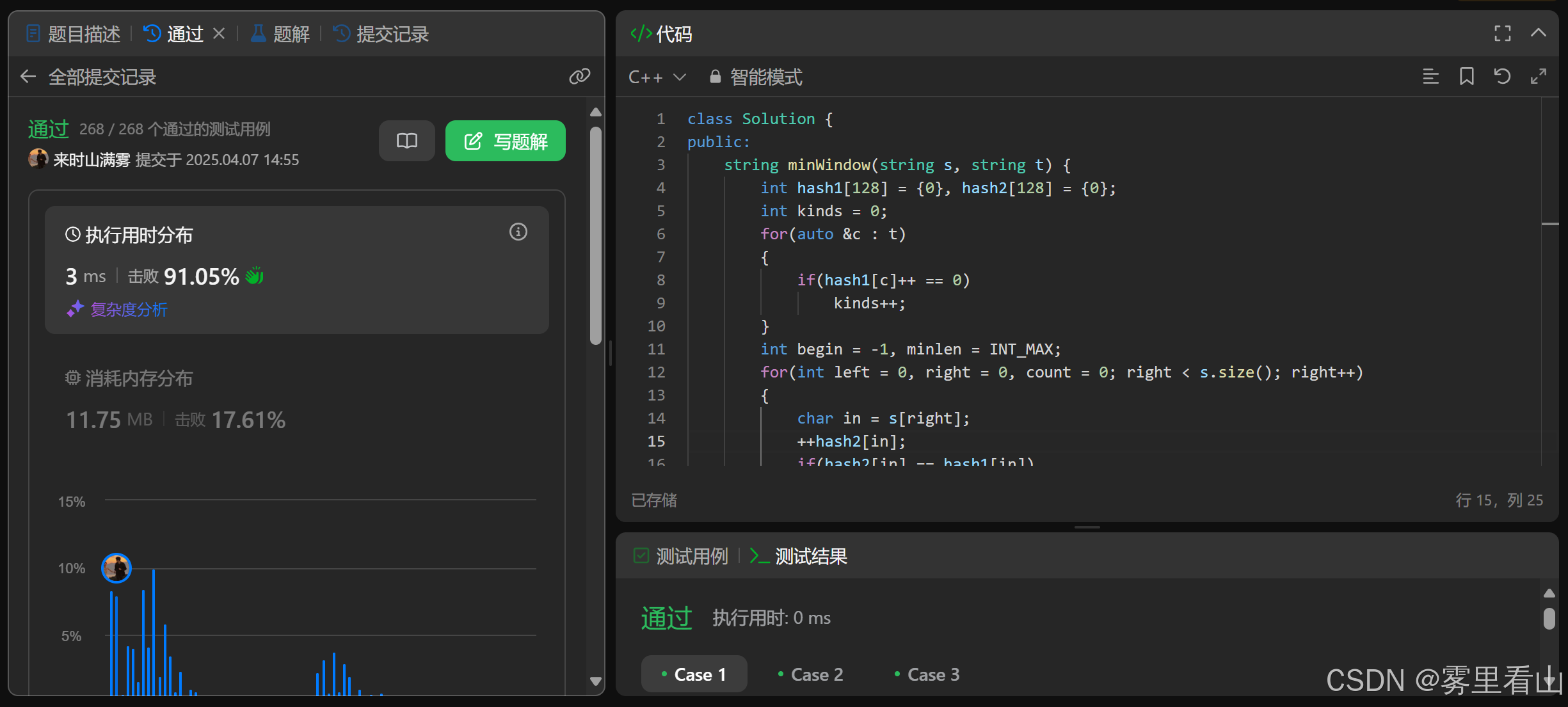
class Solution {
public:
string minWindow(string s, string t) {
int hash1[128] = {
0}, hash2[128] = {
0};
int kinds = 0;
for(auto &c : t)
{
if(hash1[c]++ == 0)
kinds++;
}
int begin = -1, minlen = INT_MAX;
for(int left = 0, right = 0, count = 0; right < s.size(); right++)
{
char in = s[right];
++hash2[in];
if(hash2[in] == hash1[in])
count++;
while(count == kinds)
{
if(right - left + 1 < minlen)
{
begin = left;
minlen = right - left + 1;
}
char out = s[left];
if(hash1[out] == hash2[out])
count--;
hash2[out]--;
left++;
}
}
if(begin == -1)
return "";
else
return s.substr(begin, minlen);
}
};
⚠️ 写在最后:以上内容是我在学习以后得一些总结和概括,如有错误或者需要补充的地方欢迎各位大佬评论或者私信我交流!!!