你还在手动爬虫?这个工具直接用让大模型来分析爬虫了
火热出炉的Firecrawl是一款强大的开源网站数据抓取工具,能够将任意网页内容转成AI模型直接能吃的Markdown或结构化数据。本文为你介绍Firecrawl的使用方法、主要功能、以及如何在项目中快速集成。
Firecrawl简介
Firecrawl 是 MendableAI 开发的一款多功能爬虫和抓取工具,支持将指定网页的内容直接转为AI模型(如大语言模型LLM)适用的格式。这意味着,无论是构建知识库、训练对话机器人,还是搭建分析工具,Firecrawl都可以自动抓取并转换数据,节省大量人工处理时间。对于开发者来说,这是一个能快速获取并结构化数据的绝佳帮手。
Firecrawl的主要特点
Firecrawl不仅功能丰富,还具有很高的可扩展性,以下是一些亮点:
-
• 多种格式输出:支持输出为Markdown、HTML、结构化数据和截图,完全适合AI使用。
-
-
• 全面爬取:输入一个主网址,即可爬取该网址下的所有页面,无需网站地图。
-
• 批量处理:可以一口气批量抓取成千上万的网页,非常适合处理大型数据集。
-
扫描二维码关注公众号,回复: 17555919 查看本文章

-
• 灵活的互动:能处理动态网页,支持滚动、点击、等待等操作,应对动态内容不在话下。
-
• 扩展性强:提供多种SDK(Python、Node、Go、Rust),并且支持与低代码平台集成(如Dify、Zapier)。
使用指南
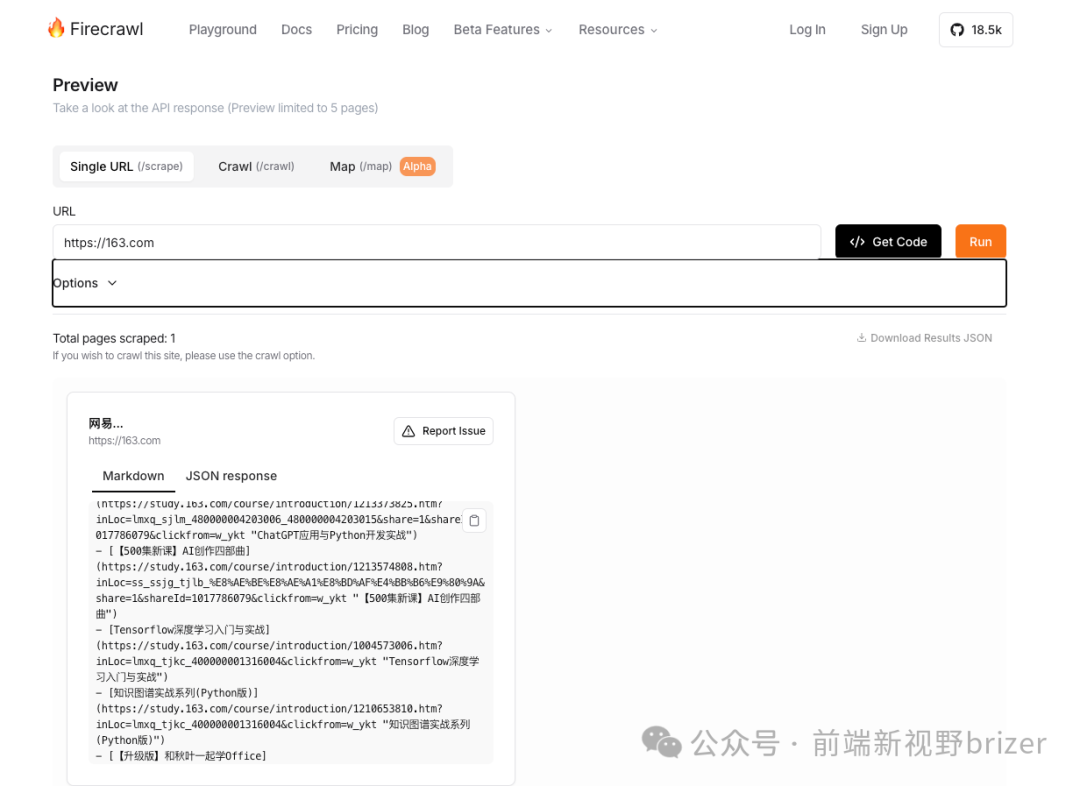
1. 快速抓取与爬取
Firecrawl 提供了简单的API接口,只需几行代码便可实现URL抓取或爬取。例如,要爬取一个网站及其子页面,可以调用API,并指定输出格式为Markdown和HTML。
示例代码(使用curl):
curl -X POST https://api.firecrawl.dev/v1/crawl \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://firecrawl.dev",
"limit": 100,
"scrapeOptions": {
"formats": ["markdown", "html"]
}
}'以上代码会返回一个爬取任务ID,便于后续查询状态或获取结果。
2. 支持结构化数据提取
Firecrawl还能提取网页中指定的信息,如文章标题、关键词等,帮助用户直接获取有价值的内容。无需编写复杂的规则,只需定义好数据的结构,Firecrawl就会自动提取。
3. 本地部署与自托管
如果你喜欢在本地或私有服务器上运行Firecrawl,开发团队提供了自托管的选项。只需下载源码并按文档部署,即可搭建一个专属于你的内容抓取服务。
技术架构
Firecrawl 的设计考虑到了数据处理的复杂性,因此其架构支持处理动态内容、代理管理、批量任务、及反爬虫机制。此外,它还支持自定义数据解析和过滤,可以设置爬取深度,甚至在需要时使用自定义请求头以突破访问限制。
典型场景
-
• 构建AI知识库:抓取公司内部文档或外部资料,将内容转为结构化数据,直接供AI模型使用。
-
• 数据收集与分析:抓取竞争对手网站内容,输出成表格或分析报告。
-
• 内容自动化管理:为电商、内容平台等提供自动内容采集功能,实时获取最新信息。
开源与云托管
Firecrawl 采用开源模式(AGPL-3.0),意味着你可以免费下载并根据需求进行二次开发。不过,为了确保稳定和可持续发展,MendableAI也提供了Firecrawl的云托管版本,更适合企业使用,享有更高的性能和功能。
获取与支持
https://github.com/mendableai/firecrawl上查看和下载Firecrawl的源码。需要注意的是,使用Firecrawl抓取内容时,请务必遵循各网站的隐私政策和使用条款。
结语
Firecrawl 是一款功能强大且简单易用的数据抓取工具。对于需要高效内容采集、数据分析和AI模型训练的开发者来说,Firecrawl无疑是一个值得一试的好工具。如果你对大规模抓取和数据转换感兴趣,不妨尝试一下!
更多好工具分享,都在群中
推荐阅读
欢迎关注我的公众号“前端新视野brizer”,原创技术文,开源好工具第一时间推送。