本文来源公众号“AI新智力”,仅用于学术分享,侵权删,干货满满。
原文链接:AI|大模型入门(二):微调技术
“ 通用人工智能(AGI)作为 AI 发展的终极愿景,追求的是让智能系统具备像人类一样理解和处理各种复杂情况与任务的能力。正是由于Google公司在2021年提出的指令微调技术(Fine-Tuning)和OpenAI公司2022年提出的基于人类反馈的强化学习(RLHF)技术,才产生了以ChatGPT为代表的现代生成式人工智能(GAI)的诞生。”
AGI(通用人工智能)作为 AI 发展的终极愿景,追求的是让智能系统具备像人类一样理解和处理各种复杂情况与任务的能力。尽管大模型的起源追溯到2017年的论文“Attention is All You Need”(该论文将transformer大模型引入了自然语言处理(NLP)任务),但正是由于Google公司在2021年提出的指令微调技术(Instruction Tuning)和OpenAI公司2022年提出的基于人类反馈的强化学习(RLHF)技术,才促使了以ChatGPT为代表的现代生成式人工智能(GAI)的诞生。
通过前文AI新智力 | AI|大模型入门(一)-CSDN博客,主要了解到我们常说的大模型指的是狭义上的大语言模型(Large Language Models):超大规模的预训练语言模型。
因为根据重要的经验性法则是扩展定律(Scaling Law),随着模型参数规模和预训练数据规模的不断增加,模型能力与任务效果将会随之改善。模型参数规模达到千亿量级,语言大模型能够展现出多方面的能力跃升(这种现象称之为涌现)。
但是其学习目标主要通过预测下一个单词实现,仍不能很好地遵循人类指令,甚至会输出无用的、有害的信息,难以有效对齐人类的偏好。因此,大模型(此处指超大规模的预训练语言模型)只是一个基座模型,并不能直接使用。针对这些问题,主要有两种大模型改进技术,包括指令微调(Fine-Tuning)以及基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF) ,这两种技术都是微调技术(fine-tuning)的一种。
微调(Fine-Tuning)
一、什么是微调?
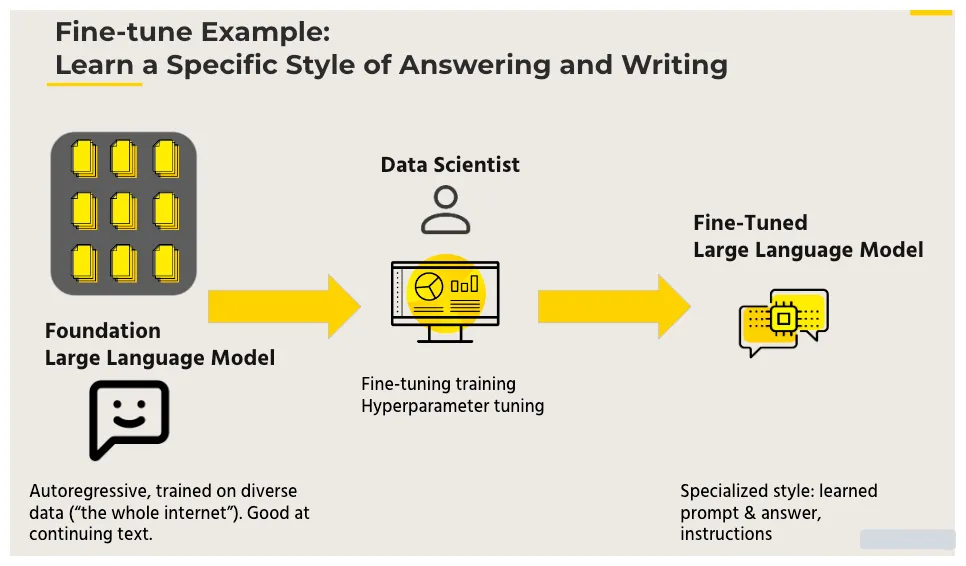
微调(Fine-tuning)是一种在自然语言处理(NLP)中使用的技术,用于将预训练的语言模型适应于特定任务或领域。Fine-tuning的基本思想是采用已经在大量文本上进行训练的预训练语言模型,然后在小规模的任务特定文本上继续训练它。
Fine-tuning的概念已经存在很多年,并在各种背景下被使用。Fine-tuning在NLP中最早的已知应用是在神经机器翻译(NMT)的背景下,其中研究人员使用预训练的神经网络来初始化一个更小的网络的权重,然后对其进行了特定的翻译任务的微调。
经典的fine-tuning方法包括将预训练模型与少量特定任务数据一起继续训练。在这个过程中,预训练模型的权重被更新,以更好地适应任务。所需的fine-tuning量取决于预训练语料库和任务特定语料库之间的相似性。如果两者相似,可能只需要少量的fine-tuning。如果两者不相似,则可能需要更多的fine-tuning。
在NLP中,fine-tuning最著名的例子之一是由OpenAI开发的OpenAI GPT(生成式预训练变压器)模型。GPT模型在大量文本上进行了预训练,然后在各种任务上进行了微调,例如语言建模,问答和摘要。经过微调的模型在这些任务上取得了最先进的性能。
二、微调技术有哪些?
常见的微调技术有Instruction Tuning、BitFit、Prefix Tuning、Prompt Tuning、P-Tuning、Adapter Tuning、LoRA、RLHF等:
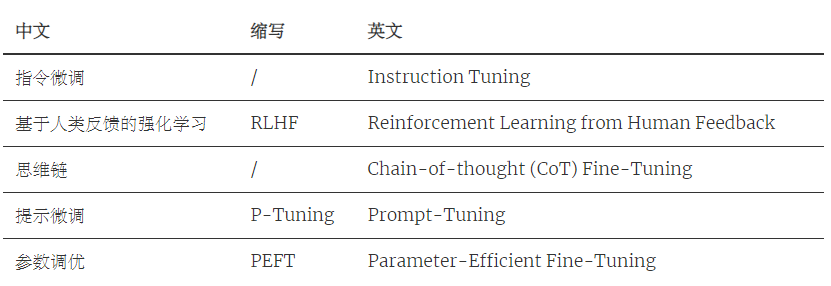
本文仅介绍前两种非常重要的微调技术:指令微调和RLHF。
指令微调(Instruction Tuning)
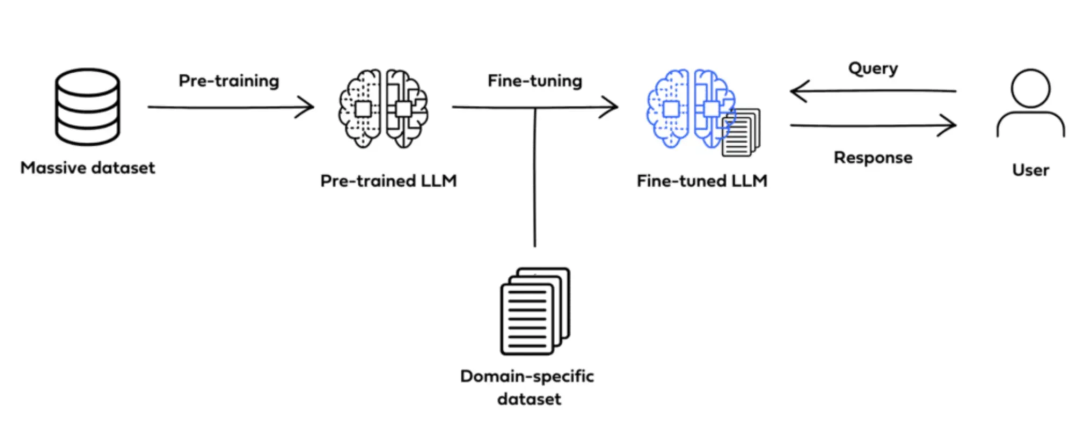
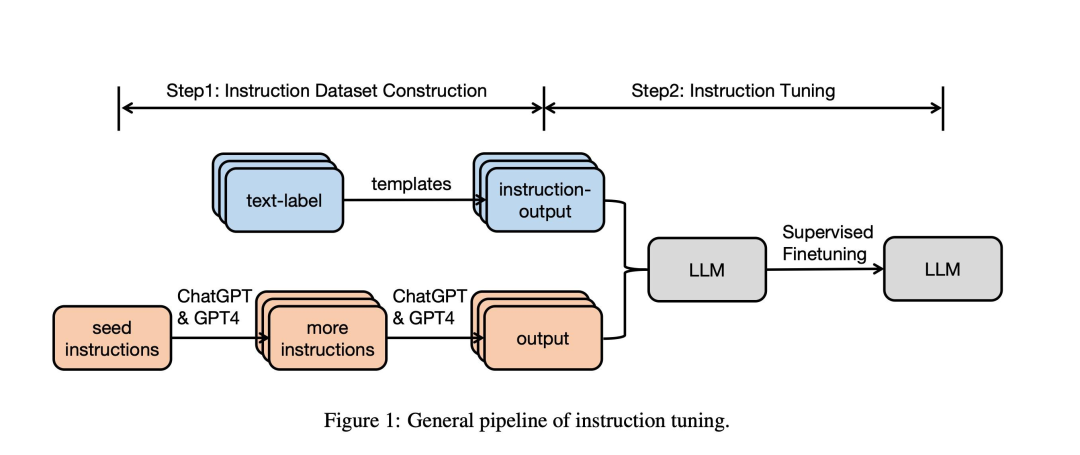
指令微调是一种用有标记的指令提示和相应输出数据集对大型语言模型(LLM)进行微调的技术。它不仅在特定任务上提高了模型的性能,而且在一般情况下提高了模型的性能,从而有助于将预训练的模型适应实际使用。
指令微调是用于调整预先训练的基础模型的更广泛的微调技术类别的子集。从样式自定义到补充预训练模型的核心知识和词汇到优化特定用例的性能,因此可以对基础模型进行微调。尽管微调并不是任何特定领域或人工智能模型体系结构的独特之处,但它已成为LLM生命周期不可或缺的一部分。
指令微调可以被视为有监督微调(Supervised Fine-Tuning,SFT)的一种特殊形式。但是,它们的目标依然有差别。SFT是一种使用标记数据对预训练模型进行微调的过程,以便模型能够更好地执行特定任务。而指令微调是一种通过在包括(指令,输出)对的数据集上进一步训练大型语言模型(LLMs)的过程,以增强LLMs的能力和可控性。指令微调的特殊之处在于其数据集的结构,即由人类指令和期望的输出组成的配对。这种结构使得指令微调专注于让模型理解和遵循人类指令。
指令微调与其他微调技术并不是互斥的。例如,聊天模型经常从人类反馈(RLHF)中进行指导调整和强化学习,这是一种微调技术,旨在提高诸如帮助和诚实之类的抽象素质;用于编码的模型经常进行指令调整(以广泛优化以下说明的响应),以及对特定于编程的数据进行其他微调(以增强模型的编码语法和词汇的了解)。
指令微调的作用与大多数微调技术一样,在于预训练的大模型没有针对对话或指令执行进行优化。从字面意义上讲,大模型不会根据提示词回答问题,它们只是根据提示词向其添加生成的文本。指令调优有助于使大模型的回答更有用。
基于人类反馈的强化学习(RLHF)
基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF) ,思想就是使用强化学习的方式直接优化带有人类反馈的语言模型。RLHF 使得在一般文本数据语料库上训练的语言模型能和复杂的人类价值观对齐。
RLHF 是一种特殊技术,用于与其他技术(例如有监督学习和无监督学习)一起训练人工智能系统,使其更加人性化。首先,将模型的响应与人类的响应进行比较。然后,人类会评测不同机器响应的质量,对哪些响应更人性化进行评分。分数可以基于人类的内在品质,例如友善、适当程度的情境化和心情。
RLHF 在自然语言理解方面表现得非常突出,但也可用于其他生成式人工智能应用程序。
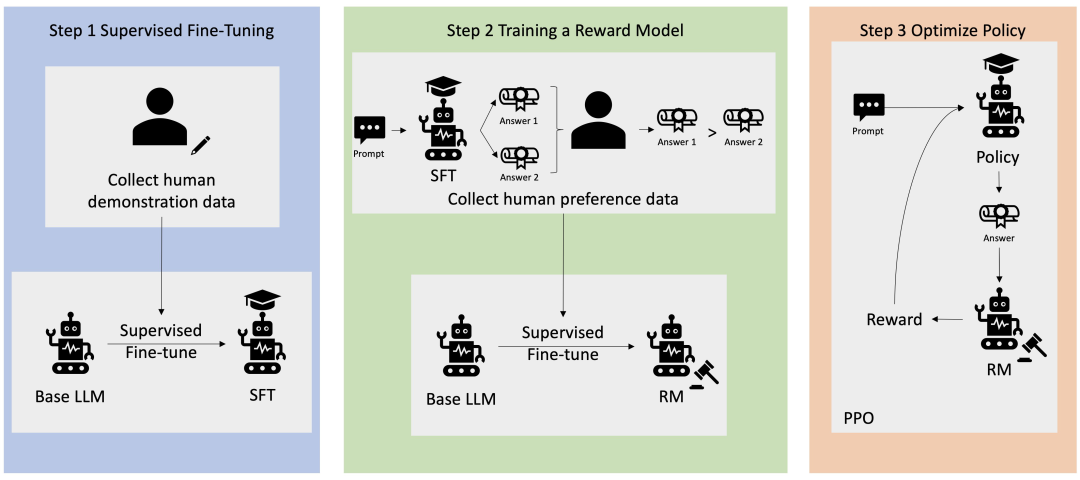
RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,一般会分为三步,这也是一个生成自己大模型所必需的:
第一步是监督微调(Supervised Fine Tuning,SFT),即用数据集进行模型微调,预训练一个语言模型 (LM);
第二步是训练一个奖励模型,它通过对于同一个 prompt 的不同输出进行人工排序,聚合问答数据并训练一个奖励模型 (Reward Model,RM);
奖励基于三个原则:
-
有用性(Helpful):判断模型遵循用户指令以及推断指令的能力。
-
真实性(Honest):判断模型产生幻觉(编造事实)的倾向。
-
无害性(Harmless):判断模型的输出是否适当、是否诋毁或包含贬义的内容。
第三步则是用强化学习算法(RL) 方式微调 LM。
下图为RLHF学习过程的概述。
Takeaways
-
超大规模的预训练语言模型的学习目标主要通过预测下一个单词实现,仍不能很好地遵循人类指令,甚至会输出无用的、有害的信息,难以有效对齐人类的偏好。因此,它只是一个基座模型,并不能直接使用。
-
解决这些问题,需要进行微调改进,其中主要有两种大模型改进技术,包括Google公司在2021年提出的指令微调(Fine-Tuning)以及OpenAI公司2022年提出的基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF) 。
-
正是因为这两项微调技术才促使了以ChatGPT为代表的现代生成式人工智能(GAI)的诞生。
参考文献:
1. Illustrating Reinforcement Learning from Human Feedback (RLHF):
https://huggingface.co/blog/rlhf
2. https://www.ibm.com/topics/instruction-tuning
3. https://zhuanlan.zhihu.com/p/682082440
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。