本文来源公众号“AI新智力”,仅用于学术分享,侵权删,干货满满。
原文链接:AI|大模型入门(一)
“大模型有广义和狭义之分,由于以ChatGPT为代表的大规模参数训练的预训练语言模型的火爆,用大语言模型特指这一模型,我们常说的大模型就是特指大语言模型。”

深度学习技术是机器学习的一种方法,机器学习是人工智能的一个分支;通过深度学习方法,利用海量无标注的数据进行自我学习来进行预训练,从而获得具备通用知识能力的大语言模型;大模型是AIGC(人工智能生成内容)的一个典型技术,而AIGC属于生成式人工智能(GAI)领域的一个典型应用。
AGI(通用人工智能)作为AI发展的终极愿景,追求的是让智能系统具备像人类一样理解和处理各种复杂情况与任务的能力。中国AGI行业应用厂商图谱如下。
人工智能(AI)
一、相关定义
人工智能(Artificial Intelligence,AI):是使计算机模拟人类智能行为的科学,包括学习、推理和自我改进。
机器学习(Mechine Learning,ML):机器学习是人工智能的一个分支,它使计算机能够通过数据和算法自动学习并改进其性能。
深度学习(Deep Learning, DL):深度学习是机器学习的一种方法,通过使用复杂的神经网络结构来处理大量数据,使得机器能够执行高级模式识别和预测。
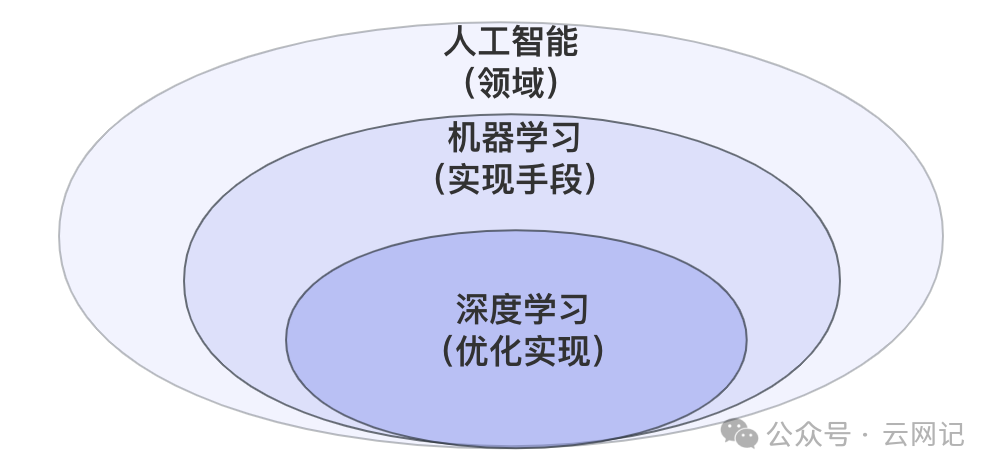
机器学习 vs. 深度学习:
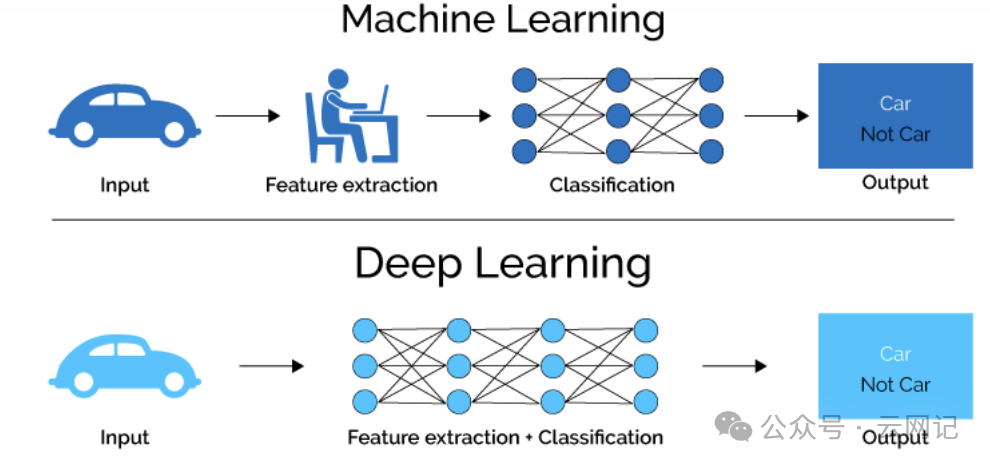
如上图所示,对于机器学习来说它需要人工介入进行特征提取来帮助机器学习来实现分类处理,而深度学习不需要人工介入干预,自身便可以实现特征提取,这是两者最大的区别。
机器学习:需要人工介入进行特征提取
深度学习:不需要人工介入干预,自身便可以实现特征提取
二、人工智能分类
人工智能可以根据能力、功能和技术大致分为几种类型。以下是不同类型AI的概述:
基于能力分类:
1.弱人工智能/狭义人工智能(ANI,Artificial Narrow Intelligence,Weak AI)
这种类型的人工智能被设计用于执行狭窄的任务(例如图像识别、互联网搜索推荐功能)。当前大多数人工智能系统,包括那些可以玩像国际象棋和围棋(AlphaGo)这样复杂游戏的系统。这些系统通常通过大量数据训练和复杂的算法来优化其在特定任务上的性能,但它们缺乏人类般的普遍智能、自我意识和跨领域推理能力。它们在有限的预定义范围或一组上下文下操作。
2.强人工智能/通用人工智能(AGI,Artificial General Intelligence,Strong AI)
一种具有广泛的人类认知能力的人工智能,使其能够自主处理新的和不熟悉的任务。这样一个强大的人工智能框架拥有识别、吸收和利用其智能来解决任何挑战的能力,而不需要人类的指导。理论上能够执行人类能够执行的任何智力任务的AI,具备广泛的理解、学习、推理和自我修正能力。例如自动驾驶汽车的未来形态、高级智能医疗顾问、全能型机器人助手等。目前,强人工智能仍然是一个研究目标,尚未实现。
3.超人工智能(ASI,Artificial Superintelligent AI)
这代表了AI的未来形式,机器可以在所有领域都超越人类智能,包括创造力,一般智慧和解决问题的能力。ASI属于假设性阶段,是许多科幻作品探讨的主题。
基于功能分类:
交互式AI(Reactive Machines):
这些人工智能系统不会为未来的行动存储记忆或过去的经验,只是分析和应对不同的情况。IBM的“深蓝”(Deep Blue)就是一个例子,它在国际象棋中击败了加里·卡斯帕罗夫(Garry Kasparov)。
有限记忆AI(Limited Memory):
这些AI系统可以通过研究他们收集的过去数据来做出明智和改进的决策。从聊天机器人和虚拟助手到自动驾驶汽车,大多数当今的AI应用程序都属于这一类。
心智理论AI(Theory of mind):
这是研究人员仍在研究的更高级的AI类型。它需要理解和记住情绪,信念,需求和根据这些做出决定。这种类型要求机器真正了解人类。
Self-aware AI
这代表了人工智能的未来,机器将拥有自己的意识、感知和自我意识。这种类型的人工智能仍然是理论的,能够理解和拥有情感,这可能导致他们形成信仰和欲望。
基于模型分类:
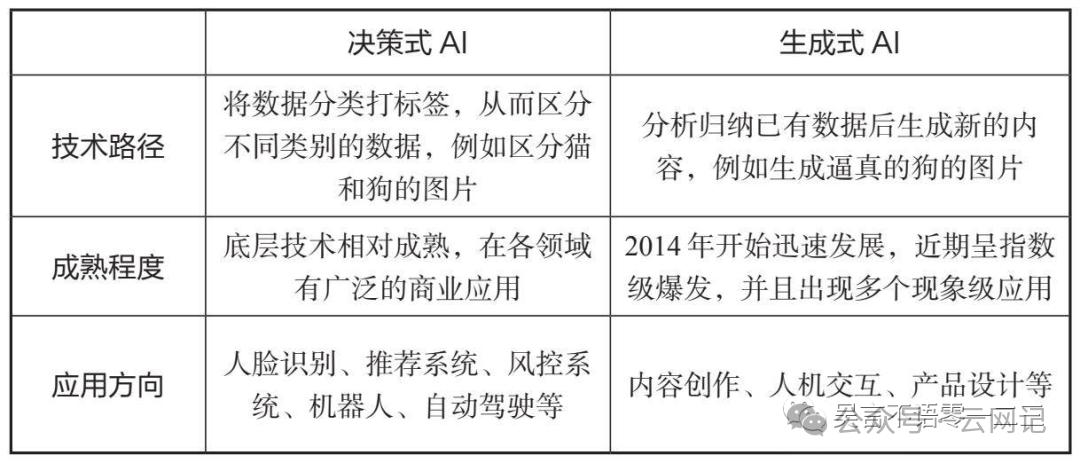
决策式人工智能(Discriminant/Analytical AI)
决策式AI(也被称作判别式AI)学习数据中的条件概率分布,即一个样本归属于特定类别的概率,再对新的场景进行判断、分析和预测。决策式AI有几个主要的应用领域:人脸识别、推荐系统、风控系统、其他智能决策系统、机器人、自动驾驶。例如在人脸识别领域,决策式AI对实时获取的人脸图像进行特征信息提取,再与人脸库中的特征数据匹配,从而实现人脸识别。
生成式人工智能(Generative AI,GAI)
生成式AI则学习数据中的联合概率分布,即数据中多个变量组成的向量的概率分布,对已有的数据进行总结归纳,并在此基础上使用深度学习技术等,创作模仿式、缝合式的内容,相当于自动生成全新的内容。生成式AI可生成的内容形式十分多样,包括文本、图片、音频和视频等。
三、GAI应用:人工智能生成内容AIGC
人工智能生成内容(AI-Generated Content, AIGC):生成式AI在娱乐媒体领域的应用指利用人工智能技术自动生成的内容,是继专业生成内容(Professional Generated Content, PGC)和用户生成内容(User Generated Content, UGC)之后一种新型生成内容的方式。国际上被称为人工智能合成媒体(AI-generated Media或Synthetic media),是通过人工智能算法对数据或媒体进行生产、操作和修改的统称。
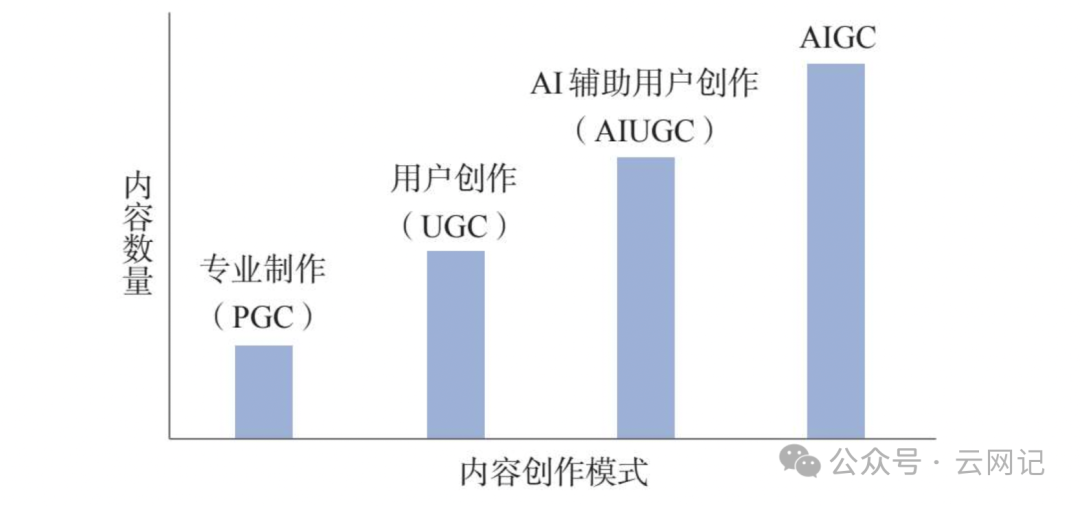
GAI vs AIGC:
GAI(Generative Artificial Intelligence,生成式人工智能),强调的是人工智能系统能够根据已学习的数据创建新内容的能力,比如生成文本、图像、音乐等。这包括了使用如生成对抗网络(GANs)、变分自编码器(VAEs)及其他深度学习模型来生成创意内容的技术。
AIGC(Artificial Intelligence Generated Content,人工智能生成内容),这个术语直接指向由人工智能生成的内容本身,而不特指技术框架。AIGC可以视为GAI所生成产物的一个描述,强调这些内容是由AI技术自动生成的,包括但不限于文章、图像、音频、视频等。
简之,AIGC是GAI(生成式人工智能)技术在娱乐媒体领域的应用。
大模型
大模型有广义和狭义之分,由于以ChatGPT为代表的大规模参数训练的预训练语言模型的火爆,用大语言模型特指这一模型,我们常说的大模型就是特指大语言模型。
一、广义上的大模型
广义上,大模型指的是在计算机视觉 、语音、自然语言处理等众多领域的基于深度学习的人工智能技术研究范式:从早期的“标注数据监督学习”的任务特定模型,到“无标注数据预训练+ 标注数据微调”的预训练模型,再到如今的“大规模无标注数据预训练+指令微调+人类对齐”的大模型。经历了从小数据到大数据,从小模型到大模型,从专用到通用的发展历程,人工智能技术正逐步进入大模型时代。
二、狭义上的大模型(特指大语言模型)
狭义上,大模型又叫大语言模型或语言大模型(Large Language Model,LLM)、预训练模型,是通过深度学习方法,利用庞大的文本数据集进行训练的机器学习模型,它具备生成自然流畅的语言文本以及准确理解语言文本深层语义的能力。大语言模型广泛应用于各种自然语言处理任务,包括但不限于文本分类、智能问答以及人机交互对话等,是AI领域的重要支柱之一。
2022年底,由OpenAI发布的语言大模型ChatGPT引发了社会的广泛关注。在“大模型+大数据+大算力”的加持下,ChatGPT能够通过自然语言交互完成多种任务,具备了多场景、多用途、跨学科的任务处理能力。
语言大模型是如何出现的,大体现在什么地方?这要从语言模型的发展历程说起。
三、语言大模型发展历程
语言大模型通过在海量无标注数据上进行大规模预训练,能够学习到大量的语言知识与世界知识,并且通过指令微调、人类对齐等关键技术拥有面向多任务的通用求解能力。在原理上,语言大模型旨在构建面向文本序列的概率生成模型,其发展过程主要经历了四个主要阶段:
1.统计语言模型:统计语言模型主要基于马尔可夫假设建模文 本序列的生成概率。此类语言模型的问题在于容易受到数据稀疏问题的影响,需要使用平滑 策略改进概率分布的估计,对于文本序列的建模能力较弱。
2.神经语言模型:针对统计语言模型存在的问题,神经语言模型主要通过神经网络(MLP、RNN)建模目标词汇与上下文词 汇的语义共现关系,能够有效捕获复杂的语义依赖关系,更为精准建 模词汇的生成概率。
3.预训练语言模型:预训练语言模型主要是基于“预训练+微调”的学习范式构建,首先通过自监督学习任务从无标注文本中学习可迁移的模型参数,进而通过有监督微调适配下游任务。早期的代表性预训练语言模型包括ELMo、GPT-1和BERT等。其中,ELMo 模型基于传统的循环神经网络(LSTM)构建,存在长距离序列建模能力弱的问题;随着 Transformer的提出,神经网络序列建模能力得到了显著的提升,GPT-1 和BERT都是基于Transformer架构构建的,可通过微调学习解决大部分的自然语言处理任务。
补充:Transformer是一种革命性的深度学习模型,最初由Vaswani等人在2017年的论文《Attention Is All You Need》中提出,主要针对序列数据的处理任务,如自然语言处理(NLP)。它颠覆了以往循环神经网络(RNN)和长短时记忆网络(LSTM)在NLP领域的主导地位,通过引入自注意力(Self-Attention)机制,实现了对序列数据的强大处理能力,特别是在处理长距离依赖问题上表现优异。
4.语言大模型(探索阶段):在预训练语言模型的研发过程中,一个重要的经验性法则是扩展定律(Scaling Law):随着模型参数规模和预训练数据规模的不断增加,模型能力与任务效果将会随之改善。当模型参数规模达到千亿量级,语言大模型能够展现出多方面的能力跃升。例如,GPT-3在没有微调的情况下,可以仅通过提示词或少数样例(In-context learning,上下文学习)完成多种任务,甚至在某些任务上超过当时最好的专用模型。学术界引入了“语言大模型”(Large language models)来特指这种超大规模的预训练语言模型,以突出与早期预训练语言模型的不同。
5)语言大模型(提升阶段):虽然早期的语言大模型表现出一定的少样本学习能力,但是其学习目标主要通过预测下一个单词实现, 仍不能很好地遵循人类指令,甚至会输出无用的、有害的信息,难以有效对齐人类的偏好。针对这些问题,主要有两种大模型改进技术,包括指令微调(Instruction Tuning)以及基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF) 。指令微调利用格式化(指令和回答配对)的训练数据加强大模型的通用任务泛化能力;基于人类反馈的强化学习将人类标注者引入到大模型的学习过程中,训练与人类偏好对齐的奖励模型,进而有效指导语言大模型的训练,使得模型能够更好地遵循用户意图,生成符合用户偏好的内容。
大语言模型拥有推理能力,TA 是一切应用的基石。
大模型生态发展
不同的大模型产品正通过不同的技术路线发展,主要技术演进如下图所示。
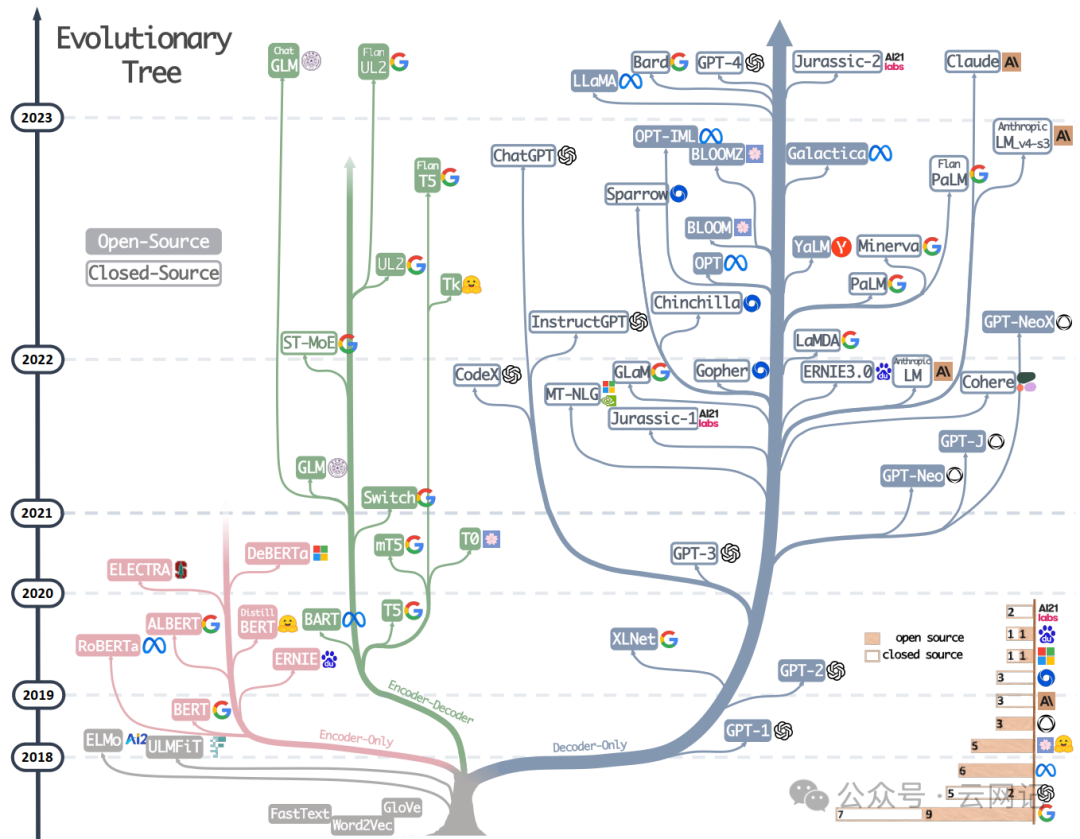
上图是一个现代大模型演进树,标识为非灰色的是基于Transformer模型:
-
用蓝色标注的分支是decoder-only模型
-
用粉色标注的分支是encoder-only模型
-
用绿色标注的分支是encoder-decoder模型
最后
AGI(通用人工智能)作为 AI 发展的终极愿景,追求的是让智能系统具备像人类一样理解和处理各种复杂情况与任务的能力。在实现这一宏伟目标的过程中,AI 大模型(LLMs)、提示词工程(Prompt Engineering)、Agent 智能体、知识库、向量数据库、RAG 以及知识图谱等技术扮演着至关重要的角色。这些技术元素在多样化的形态中相互协作,共同推动 AI 技术持续向前发展,为实现 AGI 的最终目标奠定坚实基础。
参考文献:
1.https://mp.weixin.qq.com/s/EejTII09DMWytxvw24DDPA
2.Kimi Chat如何一步步破圈?带给AI的启示https://www.woshipm.com/ai/6018735.html
3.深入理解生成式AI技术原理https://www.51cto.com/article/758048.html
4.https://mp.weixin.qq.com/s/ur7O3csVyi0lDz5xU6eGZg
5.https://www.infoq.cn/minibook/6WyXxdu179Di1O75JPUM
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。