本文来源公众号“AI新智力”,仅用于学术分享,侵权删,干货满满。
原文链接:AI|大模型入门(三):提示工程

“ 提示工程就是为了优化“用户输入”信息的,以便于更精确的从大模型中“抽取”我们想要的知识或信息。”
前文AI新智力 | AI|大模型入门(二):微调技术-CSDN博客提到,超大规模的预训练语言模型(大语言模型)只是一个基座模型(Base Model),需要使用微调技术对模型进行优化。然而优化后的大模型仅是一个通用大模型,在使用过程中还会遇到诸如胡言乱语的问题(幻觉)、不专业的问题、不与时俱进的问题,还需要使用其他技术如提示工程(Prompt Engineering)、检索增强生成(RAG)等进行强化。
为什么大模型存在这么多的问题?这要从大模型的知识构成说起。
大模型的知识构成
为什么大模型这么不够“智能”,存在这么多问题?这要从大模型的知识构成说起。
前文AI新智力 | AI|大模型入门(一)-CSDN博客提到大模型本质上是一个提词器,仅仅是具有“把话说的漂亮(顺畅)”的能力,它并不具有意识,本质上没有创造力,它输出的一切知识都基于大模型本身已有的知识和输入的知识。
下面我们来看一下大模型的知识构成:
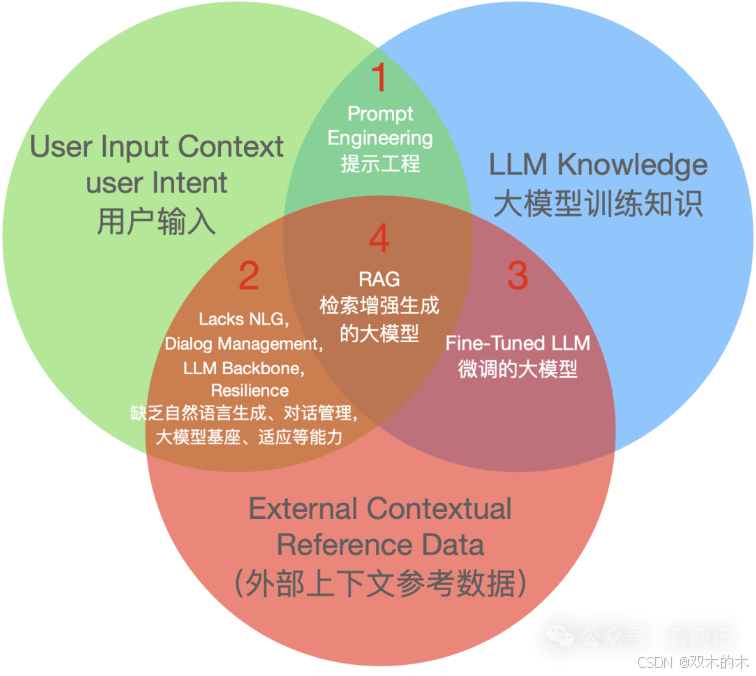
大模型获取知识有三种途径:大模型训练知识(蓝图)、用户输入的文本(绿图)、引入的外部知识库(红图)。
-
仅用大模型训练知识(蓝图)和用户输入(绿图):就是我们常用的底模,如果用户输入太简单,这通常会导致胡乱回答。对应的优化方法就是【1】提示工程(Prompt Engineering)。
-
仅用户输入(绿图)和外部数据库(红图):就是平时使用的搜索【2】,它没有自然语言输入、对话管理、大模型以及推理能力。
-
仅用大模型训练知识(蓝图)和外部数据库(红图):如果没有外部专家数据库的强化训练,就不能很好地遵循人类指令,甚至会输出无用的、有害的信息,难以有效对齐人类的偏好。对应的优化方法就是【3】微调(Fine-Tuning)。
-
把用户输入(绿图)、外部数据库(红图)和大模型训练知识(蓝图)结合:如果没有准确的上下文输入,专家数据库的参考,就回答的不与时俱进、专有的或某个特定领域的信息,对应的优化方法就是【4】检索增强生成(RAG,Retrieval-Augumented Generation)。
下面就重点介绍一下提示工程(又通常叫做Prompt工程)。
什么是提示工程
提示工程就是研究如何提高和大模型的沟通效率的,核心关注提示的开发和优化。提示工程就是为了优化“用户输入”信息的,以便于更精确的从大模型中“抽取”我们想要的知识或信息。
什么是提示(Prompt):提示就是我们给AI聊天助手输入的问题或者指令。
Prompt工程,把大模型当成一种编程语言来看待。人们通过描述角色技能、任务关键词、任务目标及任务背景,告知大模型需要输出的格式,并调用大模型进行输出。这种方法就是经典的把大模型当做工具来调用,可以称为工具模式。
提示词万能公式:
角色+角色技能+任务核心关键词+任务目标+任务背景+任务范围+任务解决与否判定+任务限制条件+输出格式+输出量
小样本提示和零样本提示
一、零样本提示
零样本提示:就是直接丢问题给大模型。
提示:
将文本分类为中性、负面或正面。文本:我认为这次假期还可以。情感:
输出:
中性在上面的提示中,我们没有向模型提供任何示例——这就是零样本能力的作用。当零样本不起作用时,建议在提示中提供演示或示例,这就引出了少样本提示。
二、小样本提示
虽然大型语言模型展示了惊人的零样本能力,但在使用零样本设置时,它们在更复杂的任务上仍然表现不佳。少样本提示可以作为一种技术,以启用上下文学习,我们在提示中提供演示以引导模型实现更好的性能。演示作为后续示例的条件,我们希望模型生成响应。
提示:
“whatpu”是坦桑尼亚的一种小型毛茸茸的动物。一个使用whatpu这个词的句子的例子是:我们在非洲旅行时看到了这些非常可爱的whatpus。“farduddle”是指快速跳上跳下。一个使用farduddle这个词的句子的例子是:
输出:
当我们赢得比赛时,我们都开始庆祝跳跃。我们可以观察到,模型通过提供一个示例(即1-shot)已经学会了如何执行任务。对于更困难的任务,我们可以尝试增加演示(例如3-shot、5-shot、10-shot等)。
以下是在进行少样本学习时关于演示/范例的一些额外提示:
-
“标签空间和演示指定的输入文本的分布都很重要(无论标签是否对单个输入正确)”
-
使用的格式也对性能起着关键作用,即使只是使用随机标签,这也比没有标签好得多。
-
其他结果表明,从真实标签分布(而不是均匀分布)中选择随机标签也有帮助。
总的来说,提供示例对解决某些任务很有用。当零样本提示和少样本提示不足时,这可能意味着模型学到的东西不足以在任务上表现良好。接下来,我们将讨论一种流行的提示技术,称为思维链提示,它已经获得了很多关注。
思维链(CoT)
一、什么是思维链提示
思维链(CoT,Chain of Thought)提示过程是一种最近开发的提示方法,它鼓励大语言模型解释其推理过程。下图显示了 few shot standard prompt(左)与链式思维提示过程(右)的比较。

思维链的主要思想是通过向大语言模型展示一些少量的样例,在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。
二、思维链的本质是什么
通过在少样本学习中提供一系列中间推理步骤作为“思路链”,可以明显改善语言模型在算术、常识和符号推理任务上的表现,尤其是在一些标准提示效果不佳的难题上。这种“思路链提示”方法模拟了人类逐步推理的过程,让语言模型也能够逐步组织语言进行多步推理。
这种通过简单提示就能激发语言模型强大推理能力的发现极具启发意义。它展示了模型规模增长带来的惊人结果,以及探索语言内在的逻辑结构的巨大潜力。当然,语言模型生成的思路链不一定准确合理,还需要进一步提高其事实性。
三、思维链提示适用场景
算术推理:在数学文本问题解答等任务上,思路链提示可以大幅提高模型的算术推理能力,例如在 GSM8K 数据集上准确率提高了两倍。
常识推理:在需要常识推理的 CSQA、StrategyQA 等数据集上,思路链提示也显示出明显提升,证明其适用范围广。
符号推理:在符号操作任务上,思路链提示可以帮助模型推广到更长的未见过的序列,实现长度泛化。
总体来说,实验结果显示,相比标准提示学习,思路链提示可以显著提升大规模语言模型在需要复杂推理的任务上的表现,特别是在标准提示效果不佳的情况下,效果更加明显。
这证明了思路链提示可以有效增强语言模型的复杂推理能力,为语言模型注入人类式的逻辑思维模式,是一种有效的训练范式。
分步骤思考(Zero-shot-CoT)
分步骤思考,学名叫Zero Shot Chain of Thought (Zero-shot-CoT)。它的意思是即使不用小样本提示,只是在问题后面加一句“let's think step by step”(让我们来分步骤思考)也能提升大模型得到正确答案的概率。这是一种成本非常低的方法,用思维链还需要我们设计样本示范,而这种方法只需要加上简单一句话,大模型就会自行生成中间步骤进行推理。
添加之前:
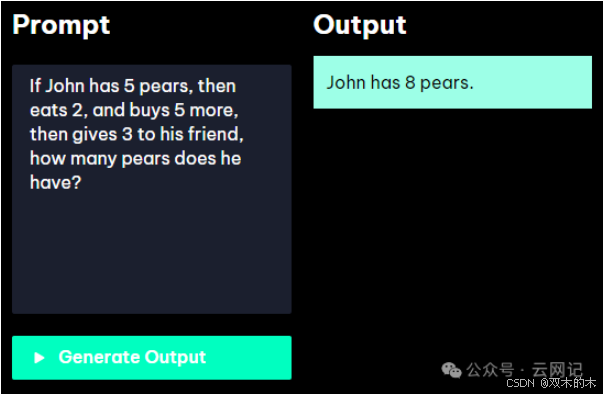
添加“Let's think step by step.”之后:

Zero-shot-CoT在提高算术、常识和符号推理任务的成绩方面很有效。
Takeaways
提示工程就是为了优化“用户输入”信息的,以便于更精确的从大模型中“抽取”我们想要的知识或信息。
提示词万能公式=角色+角色技能+任务核心关键词+任务目标+任务背景+任务范围+任务解决与否判定+任务限制条件+输出格式+输出量
仅凭Prompt工程根本无法满足人们日益增长的大模型需要,鉴于大模型本身的诸多缺陷,比如如不能及时更新知识,上下文有限等等,因此人们开始给大模型加入插件,如引入向量数据库,把数据索引进向量数据库,再召回数据,再提交给大模型做Prompt工程,这样就可以使用最新的知识和比大模型里的知识更准确的知识,这种方法叫做检索增强生成(RAG)。
参考文献:
1. https://blog.csdn.net/qq_40773212/article/details/135819676
2. 提示工程指南https://www.promptingguide.ai/zh
3. https://aws.amazon.com/cn/what-is/prompt-engineering/
4. https://www.53ai.com/news/qianyanjishu/1768.html
5. https://learnprompting.org/docs/intermediate/zero_shot_cot
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。