文章目录
融合文本、图像与语音的多模态AI技术-利用多模态AI进行内容生成【附核心代码】
在近年来,人工智能(AI)的技术发展突飞猛进,其中,多模态AI作为一种新兴的技术,凭借其结合多种输入形式(如文本、图像、语音等)来生成内容的能力,迅速引起了各行业的广泛关注。本文将深入探讨多模态AI的基本原理、实际应用场景,并通过代码实例解析如何在实际应用中实现多模态AI内容生成。
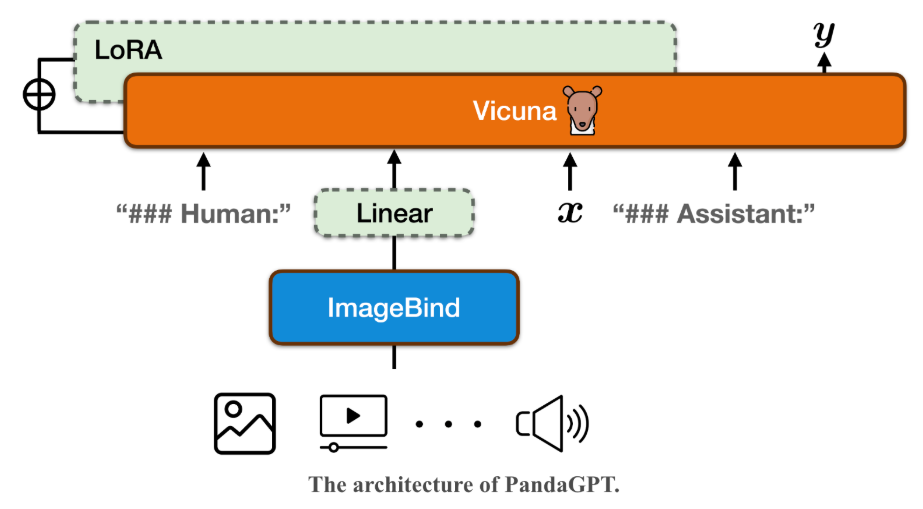
一、多模态AI的概述
1.1 什么是多模态AI?
多模态AI指的是能够同时处理和理解来自多个模态(如文本、图像、视频、音频等)的信息,并将这些信息结合在一起以进行推理、决策或生成内容的人工智能技术。传统的AI系统通常只能处理单一模态的信息,而多模态AI则通过融合多种输入形式,能够更准确、更智能地进行任务执行。
1.2 多模态AI的核心技术
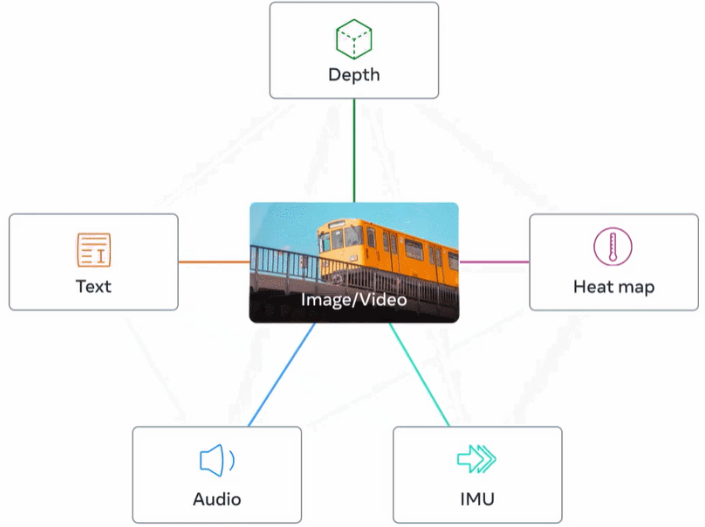
多模态AI的核心技术主要包括以下几个方面:
- 深度学习模型:多模态AI依赖于深度神经网络来处理不同类型的输入数据。例如,卷积神经网络(CNN)常用于图像处理,循环神经网络(RNN)或变换器(Transformer)则常用于文本和语音处理。
- 跨模态学习:不同模态之间的关联学习是多模态AI的关键技术。通过训练模型理解不同模态之间的关系,AI可以实现跨模态的任务,如文本生成图像或图像描述生成文本。
- 注意力机制:在多模态AI中,注意力机制能够帮助模型聚焦于关键信息,尤其是在处理多个模态的输入时,能够有效地捕捉到不同模态之间的相互关系。
二、多模态AI的应用场景
2.1 自动内容生成
多模态AI在内容生成领域的应用非常广泛。例如,文本-图像生成模型(如OpenAI的DALL·E)能够根据输入的文本描述自动生成相应的图像。此外,图像-文本模型(如CLIP)则可以通过图像进行文本理解,或者通过文本生成相关图像。
2.2 跨模态搜索
跨模态搜索是指通过一种模态的信息检索另一种模态的相关数据。例如,输入一段文字,AI可以根据这段文字查找相关的图像;或者输入一张图片,AI可以提供描述该图像的文字。这种技术广泛应用于电子商务、社交媒体平台以及医学图像处理等领域。
2.3 智能助手
智能助手如Siri、Alexa等,利用多模态AI技术将语音、图像和文本结合,提供更智能的交互体验。比如,用户可以通过语音指令要求系统生成图片或处理图像数据,AI根据用户的指令理解多模态信息并提供反馈。
三、如何实现多模态AI内容生成
3.1 构建多模态AI模型
要实现多模态AI内容生成,首先需要构建能够处理多种模态数据的深度学习模型。下面是一个基本的框架,其中利用了图像和文本模态来生成图像。
3.1.1 数据准备
首先,确保你拥有一个包含图像和相应文本描述的数据集。例如,Microsoft COCO数据集就包含了大量的图像及其对应的文本描述。
3.1.2 模型设计
我们可以设计一个基于Transformer的多模态AI模型。以下是一个简化的多模态文本到图像生成的代码框架:
import torch
import torch.nn as nn
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import matplotlib.pyplot as plt
# 加载CLIP模型和处理器
model_name = "openai/clip-vit-base-patch16"
clip_model = CLIPModel.from_pretrained(model_name)
processor = CLIPProcessor.from_pretrained(model_name)
# 假设输入文本和图像
text = "a photo of a cat"
image_path = "cat_image.jpg"
# 加载图像
image = Image.open(image_path)
# 处理文本和图像
inputs = processor(text=text, images=image, return_tensors="pt", padding=True)
# 获取图像和文本的特征表示
outputs = clip_model(**inputs)
image_features = outputs.image_embeds
text_features = outputs.text_embeds
# 计算文本和图像的相似度
similarity = torch.cosine_similarity(image_features, text_features)
print(f"Cosine similarity between text and image: {
similarity.item()}")
# 可视化结果
plt.imshow(image)
plt.title(f"Similarity: {
similarity.item():.4f}")
plt.axis('off')
plt.show()
3.1.3 训练模型
在实际应用中,训练多模态AI模型需要使用大量标注数据,并进行长时间的训练。这里的模型结合了CLIP(Contrastive Language-Image Pre-training)模型,通过将图像和文本嵌入到同一空间进行对比学习,从而实现图像和文本之间的映射。
3.2 文本到图像生成
对于文本到图像的生成,我们可以使用像DALL·E、VQGAN等生成模型。通过输入文本描述,模型会生成相应的图像。DALL·E使用变换器模型(Transformer)将文本信息转换为图像。其核心思想是将图像生成问题转化为一个条件生成任务,模型学习如何根据文本输入生成高质量的图像。
# 示例:使用Transformers库加载DALL·E模型进行文本到图像生成(伪代码)
from transformers import DALL_E
model = DALL_E.from_pretrained("openai/dall-e")
generated_image = model.generate_image_from_text("a futuristic cityscape at sunset")
generated_image.show()
3.3 图像到文本生成
图像到文本生成(Image Captioning)是另一类重要的多模态任务。例如,我们可以使用类似Show, Attend and Tell这样的模型,将图像中的内容通过自然语言描述出来。
# 示例:图像到文本生成
from transformers import VisionEncoderDecoderModel, ViTImageProcessor, AutoTokenizer
# 加载模型
model = VisionEncoderDecoderModel.from_pretrained("nlpconnect/vit-gpt2-image-captioning")
processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# 加载和处理图像
image = Image.open("image.jpg")
inputs = processor(images=image, return_tensors="pt")
# 生成文本描述
output = model.generate(**inputs)
caption = tokenizer.decode(output[0], skip_special_tokens=True)
print(f"Generated Caption: {
caption}")
四、挑战与前景
4.1 持续优化跨模态学习
虽然当前的多模态AI系统已经取得了显著进展,但如何更高效地融合不同模态的数据,减少计算复杂度,仍然是一个技术挑战。未来,随着硬件和算法的不断优化,多模态AI的性能将得到进一步提升。
4.2 应用拓展
多模态AI在内容生成、广告创意、虚拟现实等领域的应用将越来越广泛。通过持续的技术创新,预计多模态AI将在更多实际场景中展现出巨大的潜力。
5. 多模态AI在实际应用中的优化策略
尽管多模态AI展示了强大的潜力,但在实际应用中,还存在许多挑战,尤其是在模型训练、数据处理和结果生成的质量方面。为了提升多模态AI系统的性能,优化策略显得尤为重要。
5.1 数据预处理与增强
在多模态AI中,数据预处理和增强是提高模型性能的关键。不同模态的数据往往有不同的分布和噪声,需要采取适当的预处理策略来标准化和优化输入数据。
5.1.1 图像数据增强
图像是多模态AI中最常见的模态之一。在图像数据的处理中,常见的数据增强方法包括裁剪、旋转、平移、缩放和颜色调整等。这些操作不仅可以增加训练数据的多样性,还能帮助模型在处理不同的输入时具备更强的鲁棒性。
from torchvision import transforms
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop(224),
transforms.RandomRotation(30),
transforms.ToTensor(),
])
# 应用到图像
image_transformed = transform(image)
5.1.2 文本数据处理
文本数据的处理也同样重要。对于文本数据,通常使用分词、去除停用词、词干化等方法来清理文本。为了进一步提升模型的性能,可以使用预训练的词向量(如Word2Vec、GloVe)来初始化词嵌入,使得模型能够更好地捕捉文本中的语义信息。
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
inputs = tokenizer("This is a sample text", return_tensors="pt")
5.2 模型融合与集成
多模态AI模型的优化不仅仅依赖于单一模型的改进,还可以通过模型融合与集成策略来进一步提升性能。模型融合是通过结合多个模型的预测结果,来提高整体的准确性和稳定性。在多模态AI中,常见的模型融合方法包括:
- 加权平均:将多个模型的输出进行加权求和,从而得到最终结果。
- 堆叠(Stacking):通过将多个模型的输出作为输入,使用一个新的模型来学习最优的输出。
- 对抗训练:利用生成对抗网络(GAN)来训练生成模型,通过对抗性训练优化生成的内容。
from sklearn.ensemble import VotingClassifier
# 假设我们有多个模型
model1 = SomeModel()
model2 = AnotherModel()
# 使用投票法融合
ensemble_model = VotingClassifier(estimators=[('m1', model1), ('m2', model2)], voting='hard')
ensemble_model.fit(X_train, y_train)
5.3 注意力机制与自注意力(Self-Attention)
在多模态AI中,注意力机制(Attention Mechanism)和自注意力机制(Self-Attention)被广泛应用于提升模型在处理多模态数据时的效率。通过在模型中引入自注意力机制,AI能够动态地为输入数据中的各个部分分配不同的权重,使得模型能够关注到更重要的部分。
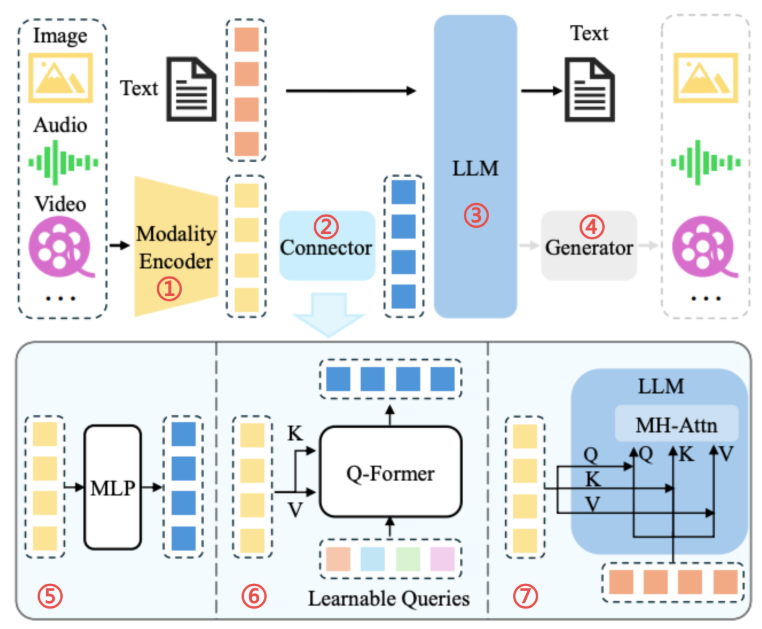
例如,Transformers中的自注意力机制使得模型在处理文本、图像等信息时,能够根据上下文信息来调整每个输入特征的权重,从而增强了模型的表示能力。
import torch
import torch.nn as nn
class SimpleAttentionModel(nn.Module):
def __init__(self, input_dim):
super(SimpleAttentionModel, self).__init__()
self.attention = nn.MultiheadAttention(input_dim, num_heads=2)
def forward(self, x):
attn_output, _ = self.attention(x, x, x)
return attn_output
# 使用注意力机制
input_tensor = torch.rand(10, 32, 256) # 假设有32个序列,每个序列256维
model = SimpleAttentionModel(256)
output = model(input_tensor)
5.4 模型蒸馏与轻量化
在实际应用中,尤其是在资源受限的环境中,模型的大小和推理速度是非常关键的因素。为了在保证性能的同时提高模型的效率,模型蒸馏(Model Distillation)和轻量化(Model Pruning)技术应运而生。
- 模型蒸馏:通过将一个大模型的知识传递给一个小模型,使得小模型在尽量减少参数量的同时,仍然能够达到接近大模型的性能。
- 模型剪枝:通过删除一些不重要的权重或神经元,减小模型的复杂度和计算量。
from torch import nn
class DistilledModel(nn.Module):
def __init__(self, base_model):
super(DistilledModel, self).__init__()
self.base_model = base_model
self.fc = nn.Linear(512, 10)
def forward(self, x):
x = self.base_model(x)
return self.fc(x)
# 蒸馏技术实现
small_model = DistilledModel(base_model=large_model)
6. 多模态AI的伦理与安全问题
随着多模态AI技术的广泛应用,随之而来的是一系列伦理和安全问题。AI生成内容的能力越来越强,是否能够确保生成内容的真实、合法以及不造成社会危害,成为了一个重要的议题。
6.1 内容的真实性与责任
多模态AI能够生成逼真的文本、图像、视频等内容,但这些内容的真实性往往难以验证。在社交媒体和新闻报道中,假信息的传播可能会造成严重后果。因此,如何建立起合理的审查机制,确保生成的内容符合道德规范和法律要求,是亟待解决的问题。
6.2 数据隐私与安全
在训练多模态AI模型时,往往需要大量的数据,包括个人信息、图像数据、语音数据等。这些数据的收集和使用必须遵循隐私保护法律,如GDPR等,以防止用户数据的滥用。如何在不侵犯隐私的前提下使用数据,成为了技术发展的一个重要方向。
6.3 模型的公平性
在多模态AI的训练过程中,数据集的偏见问题是不可忽视的。如果训练数据包含了性别、种族、年龄等方面的偏见,生成的内容也可能反映出这些偏见。因此,如何消除模型中的偏见,保证生成内容的公平性和包容性,是AI研究者和开发者需要关注的问题。
7. 多模态AI的未来发展趋势
7.1 跨领域集成与泛化能力
未来的多模态AI系统将不仅局限于文本、图像和视频的组合,更可能融合更多领域的数据。例如,AI可能同时处理生物医学图像、基因数据、文本描述等多种类型的复杂信息,进一步拓展其应用范围。
此外,跨模态学习的泛化能力也将逐步增强,模型能够从不同领域的多模态数据中提取更有用的信息,并将其应用于不同的任务中。
7.2 更高效的训练方法
随着技术的进步,我们可以预见到多模态AI训练方法将变得更加高效。例如,基于少量样本学习(Few-shot Learning)和自监督学习(Self-supervised Learning)等新兴技术的应用,能够大大降低训练成本并提高模型的性能。
7.3 多模态AI与人类智能的融合
未来,多模态AI的发展可能不仅是为了增强机器的生成能力,更是为了与人类智能的更深层次融合。例如,AI可以成为人类的创作伙伴,协助艺术家、设计师、写作者等进行创作,同时增强人类的创新能力。
结语
多模态AI正在成为各行业中的重要技术,它不仅仅改变了内容生成的方式,更为人类的创作、学习和工作提供了新的可能性。尽管在实际应用中存在一些挑战,但随着技术的不断发展,未来多模态AI的应用将会越来越广泛,也将为我们带来更多的创新和突破。