25年2月来自 UC Berkeley、Nvidia 和 UT Austin 的论文“Sim-to-Real Reinforcement Learning for Vision-Based Dexterous Manipulation on Humanoids”。
强化学习在不同问题领域取得有希望的成果,实现人类甚至超人-级的能力,但在灵巧机器人操作方面的成功仍然有限。这项工作调查将强化学习应用于人形机器人解决一系列接触-丰富操作任务的关键挑战。本文引入新技术来克服已发现的挑战并通过实证验证。主要贡献包括一个自动化的真实-到-模拟调整模块,使模拟环境更接近现实世界,一个广义的奖励设计方案,简化长期接触-丰富操作任务的奖励工程,一个分而治之的蒸馏过程,提高难探索问题的采样效率,同时保持模拟-到-真实的性能,以及稀疏和密集目标表示的混合,以弥合模拟-到-真实的感知差距。其在三个人形灵巧操作任务上展示有希望的结果,并对每种技术进行消融研究。
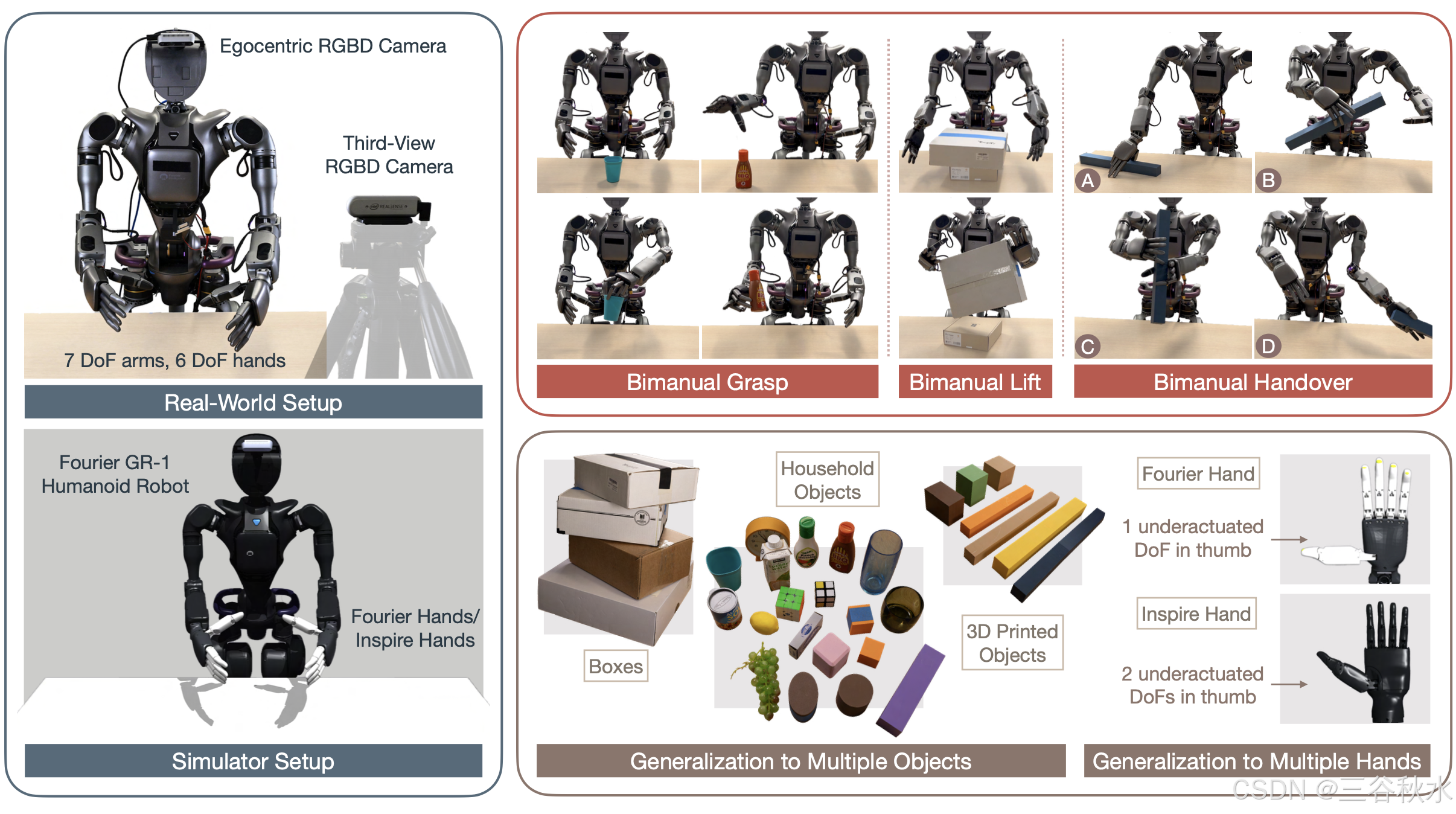
本文方法概述如图所示:训练一个拥有两个多指手的人形机器人对各种物体执行一系列接触丰富的灵巧操作任务。观察结果来自第三视角相机、自我为中心相机和机器人本体感受。部署的 RL 策略可以适应各种具有不同物理属性(例如形状、大小、颜色、材料、质量)的现实世界中未见过物体,并且能够抵抗力干扰。
近年来,深度强化学习 (RL) 取得许多深刻的成果,涵盖广泛的应用领域:经典棋盘游戏 [48]、竞争多人在线游戏 [6, 56]、大语言模型 [1, 14]、现实世界机器人运动 [21, 26]、自主无人机竞赛 [24] — 仅举几例。这些成就不仅展示 RL 在各种任务中达到或超越人类水平表现的潜力,而且还凸显其通过自主探索进行扩展和泛化的独特能力。这些固有特性使 RL 成为一种高效且长期的方法,可以解决难以用人类先验或演示解决的任务。
深度强化学习在机器人领域的应用
多年来的研究已经发现深度 RL 这种范式存在脆弱性,最明显的是对超参的敏感性 [19] 和可疑的可重复性 [23],这是由于强化学习算法固有的高方差所致。
在强化学习的未解决问题中,最重要和最长期存在的是探索。在监督学习中,通常假设数据是给定的。然而,在强化学习中,智体需要收集自己的数据并根据收集的数据更新策略。数据收集方式的问题被称为探索问题。现实世界的机器人具有高维观测和动态以及通常稀疏的奖励,这为强化学习提出一组特别具有挑战性的艰难探索问题。虽然有些研究通过鼓励访问新状态来算法扩展对高维输入的探索 [4, 7, 30, 38, 39, 50, 53],但它们并没有从根本上解决探索挑战。此外,应用 RL 解决现实世界的机器人问题还揭示 RL 中的标准基准 [5, 54] 未能捕捉的重要挑战:(1) 缺乏完全或准确的建模环境;(2) 缺乏针对感兴趣任务的明确定义的奖励函数。
机器人和 RL 交叉领域的过去研究,提出了各种实用技术来缓解这些问题,例如从人体运动数据或遥控演示中学习 [9, 45, 60, 65]、用于建模物体和视觉环境的真实-到-模拟技术 [2, 16, 17, 31, 55] 以及设计奖励的更多原则性方法 [37, 62]。虽然其中一些方法对特定任务和设置过拟合,但它们为这项工作指明了有希望的方向。
基于视觉的人形机器人灵巧操作
模仿学习和经典方法。遥操作 [10, 32, 58, 63] 的创新和从演示中学习 [11, 28] 带来许多基于视觉灵巧操作的最新进展 [10, 28, 32, 64]。然而,在实践中,让遥操作员收集高质量的灵巧操作数据仍然成本高昂,而使用纯粹从现实世界的遥操作中收集的数据进行性能扩展 [27, 29, 64] 表明,达到人类水平的性能成本可能高得令人望而却步。
强化学习方法。许多现有的研究已经成功地将强化学习应用于解决多指手的灵巧操作问题,但要么假设单手设置 [2, 8, 17, 35, 42, 49, 57],要么不使用像素输入作为目标表示 [9, 20, 31]。此外,大多数现有研究都侧重于单一操作技能,包括手内重定位 [2, 17, 42, 57]、抓握 [35, 49]、扭转 [31] 和动态接手 [20]。Chen [9] 的方法依赖于人手运动捕捉数据来学习腕部控制器,而不是从头学习完整的手臂关节控制。此外,现有研究通常侧重于物理模拟模型已经经过更广泛测试的硬件。
受 RL 潜力的激励,本文探索使用 RL 来解决具有挑战性的视觉灵巧操作任务。到目前为止,深度 RL 在这个问题域取得的成功仍然有限。先前的研究已经展示高度灵巧的操控能力,而这些能力无法由人类简单地编程或遥操作 [2, 17, 31]。然而,这些方法通常只针对单一操控技能,限制它们的广泛适用性。
是什么阻碍 RL 更普遍地应用于基于视觉的灵巧操控?本文首先通过识别灵巧操控的固有属性来研究这个问题,这些属性使该应用领域有别于其他领域。然后,研究这些属性如何导致应用 RL 算法的挑战,并开发一系列新技术来应对这些挑战。结合自身经验和技术,本文概述将模拟-到-真实的 RL 应用于基于视觉人形操控任务的方法,并展示有希望的结果。
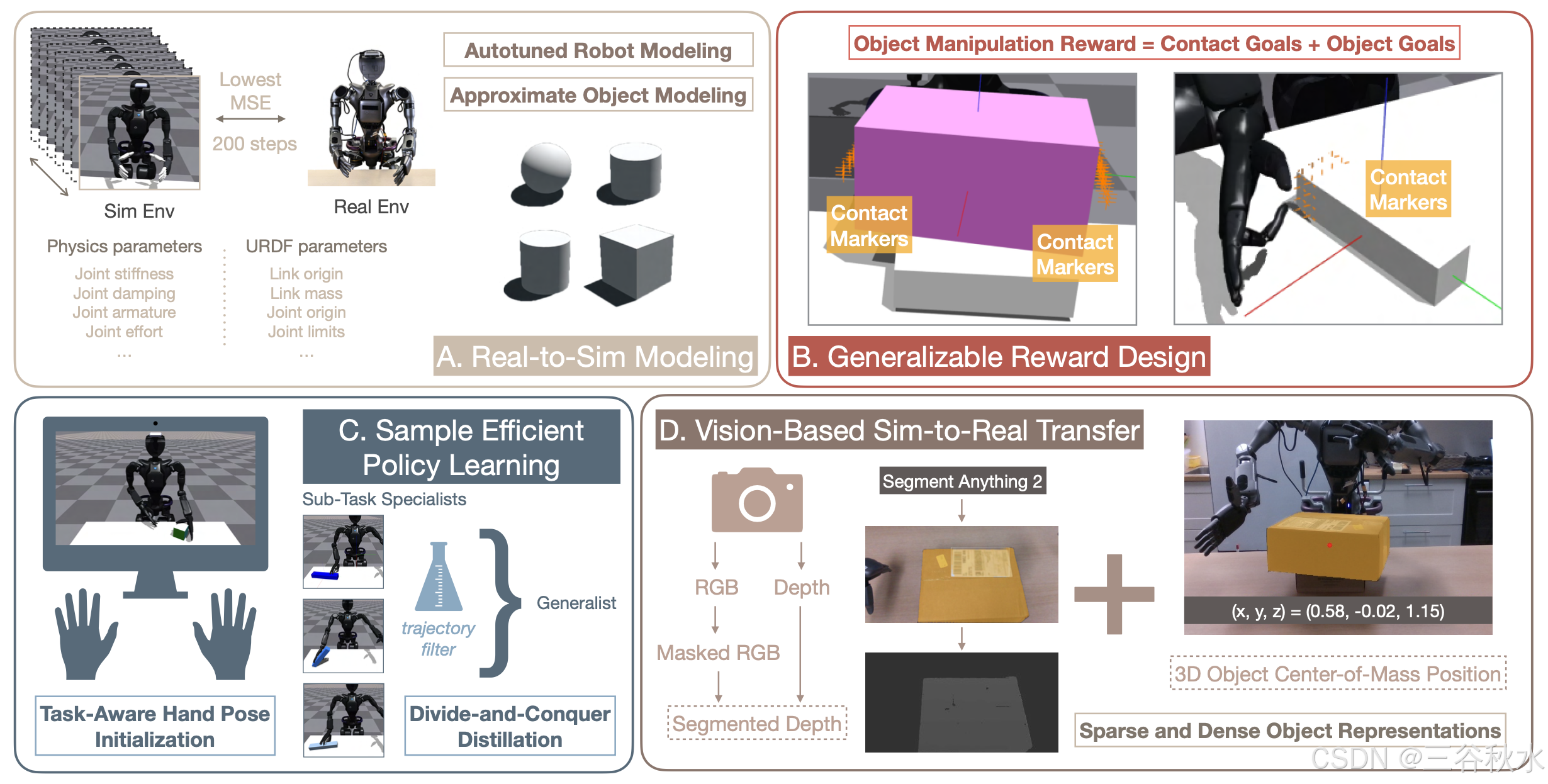
如图显示灵巧操作面临挑战和方法的概述:
真实-到-模拟建模
模拟器提供了无限的反复试验机会,以执行 RL 所需的探索。然而,在模拟中学习到的策略能否可靠地转移到现实世界,在很大程度上取决于建模的忠实度——包括机器人本身和环境。当应用模拟-到-真实 RL 来解决灵巧操作时,这种真实-到-模拟建模问题因需要对目标进行建模而进一步加剧,这些目标具有很大的可变性,并且其全部物理属性无法轻易量化。即使假设已知真值物理参数,定量匹配模拟与现实世界也很困难:由于物理引擎的限制,模拟和现实世界中物理常数的相同值不一定对应于相同的运动学和动力学关系。
自动调整机器人建模。虽然机器人制造商通常能够为他们的机器人硬件提供专有模型文件,但这些模型大多作为机器人真实-到-模拟工作的起始参考,而不是无需修改即可使用的真值模型。提高建模精度的经验解决方案包括手动调整机器人模型常数和可模拟物理参数 [2] 以及在所选模拟器中重新制定特别的运动结构(例如四连杆)[44]。这是一个费力的过程,因为现实世界和模拟世界之间没有“基本事实”配对。其提出一种实用的技术,通过“自动调节”模块来加速这个从真实-到-模拟的建模过程。自动调节模块可以快速标定模拟器参数,以匹配真实机器人行为,方法是自动搜索参数空间,在四分钟内(或 10 Hz 下 2000 个模拟步骤)确定模拟器物理和机器人模型常数的最佳值。如上图 A 和算法 1 中说明该模块。

该模块对两种参数类型进行操作:影响运动学和动力学的模拟器物理参数,以及来自 URDF 文件的机器人模型常量(包括连杆惯性值、关节限制和关节/连杆姿势)。标定过程首先使用从参数空间随机采样的参数组合初始化多个模拟环境,这些参数组合由制造商的机器人模型文件引导。然后,它在真实机器人硬件(单次运行)和所有模拟环境中并行执行由关节位置目标组成的 N 个标定序列。通过比较每个模拟环境和真实机器人在跟踪相同关节目标时之间的跟踪误差,模块选择使跟踪性能的均方误差最小化的参数集。这种方法只需要在真实机器人上进行一组标定运行,自动优化传统上难以调整的 URDF 参数,并支持并行评估多个参数组合,从而消除迭代手动调整。该方法的通用性使其能够调整影响运动行为的任何公开模拟器或机器人模型参数。
近似目标建模。如前文 [31, 41] 所述,将目标建模为具有随机参数的圆柱体等原始形状足以学习模拟-到-真实的可迁移灵巧操作策略。本文处方采用这种方法并且证明它是有效的。
可泛化的奖励设计
在 RL 的标准公式 [51] 中,奖励函数是 RL 范式中的关键元素,因为它全权负责定义智体的行为。尽管如此,RL 研究的主流一直专注于学习算法的开发和分析,将奖励信号视为给定的且不会改变的 [13]。随着感兴趣的任务变得越来越普遍,设计奖励机制以引发期望的行为变得越来越重要和困难 [12]——就像机器人应用的情况一样。当涉及到用多指手进行灵巧操作时,由于接触模式和物体几何形状的多样性,奖励设计变得更加困难。
操作作为接触和物体的目标。从各种各样的人类操作活动 [15] 中,灵巧操作的一般模式:执行任务的每个动作序列都可以定义为手与物体接触和物体状态的组合。基于这种直觉,提出一种通用的奖励设计方案,甚至可以用于长期接触丰富的操作任务。对于每个感兴趣的任务,首先将其分解为接触状态和物体状态的交错序列。例如,移交任务可以分解为以下步骤:(1)一只手接触物体;(2)将物体举到靠近另一只手的位置;(3)另一只手接触物体;(4)将物体转移到最终目标位置。然后可以仅基于“接触目标”和“物体目标”来定义奖励:每个接触目标可以通过惩罚手指-到-理想接触点的距离或仅仅是物体的质心位置来指定;每个物体目标可以通过惩罚其当前状态(例如,当前 xyz 位置)-到-其目标状态(例如,目标 xyz 位置)的距离来指定。为了降低指定接触目标的难度,提出一种基于关键点的技术:对于每个模拟资产,程序化地生成一组附着在物体表面的“接触贴纸(contact sticker)”,其中每个贴纸代表一个潜在的理想接触点。上图(B)所示接触贴纸的可视化。
样本高效策略学习
由于在探索高维空间时样本复杂度高且奖励稀疏(尤其是在具有多指手的人形机器人上),即使使用定义明确的奖励函数,策略学习也可能需要非常长的时间。本文提出两种更有效地提高策略学习样本效率的技术:(1)使用任务-觉察手势初始化任务;(2)将具有挑战性的任务划分为较容易的子任务,然后将子任务专家蒸馏为一个通才策略。
用于初始化的任务-觉察手势。通过从人类那里收集任务-觉察手势数据来减少探索挑战。这可以通过将任何用于双手多指手的遥操作系统连接到所选模拟器来实现。然后,在模拟中随机抽样收集的状态(包括物体姿势和机器人关节位置)作为任务初始化状态。与之前需要完整演示轨迹 [3] 的研究不同,遥控操作员无需完成任务,只需在收集环境状态时牢记任务目标“操作”即可。这种方法大大减少遥控所需的时间,因为人类操作员无需花时间“加速”来收集高质量数据。在实验中,每个任务只需不到 30 秒即可收集到足够数量的手势数据。
分而治之的蒸馏。以前提高策略学习样本效率的方法主要侧重于更有效地探索状态空间 [7, 30, 39, 52]。然而,这些方法并没有从根本上降低探索问题的难度:从探索“正确”状态中接收学习信号的概率保持不变。根据这一观察推断,在稀疏奖励设置中克服探索问题的更简单方法是分解可探索状态空间本身。例如,多目标操作任务可以分为多个单目标操作任务。将复杂任务划分为更简单的子任务后,可以为每个子任务训练专门的策略,并将它们提炼为通才策略。这种方法的另一个好处是,可以根据子任务策略的最优性灵活地从子任务策略中筛选出轨迹数据,只保留高质量的样本进行训练。这有效地使强化学习更接近从演示中学习,其中子任务策略充当模拟环境中任务数据收集的遥控操作员,而通才策略充当从精选数据中训练的一个集中化模型。
基于视觉的模拟-到-现实迁移
由于模拟-到-现实的差距,将模拟中学习的策略迁移到现实世界具有挑战性。在基于视觉灵巧操作的情况下,模拟-到-现实的差距源于动力学和视觉感知——两者都是具有挑战性的开放研究问题。如下有两种用于缩小差距的关键技术。
混合目标表示。目标感知对于灵巧操作至关重要,因为该任务不可避免地与目标交互相结合。先前的研究表明,成功的模拟-到-现实迁移操作策略已经探索广泛的目标表示,包括(按维度和复杂性增加的顺序)3D 目标位置 [31]、6D 目标姿势 [2]、深度 [35, 42]、点云 [33] 和 RGB 图像 [17]。使用这些不同的目标表示之间存在微妙的权衡:虽然高维表示可以编码有关目标的更丰富信息,但这些数据模态中较大的模拟-到-真实差距使学习的策略更难迁移;另一方面,由于信息量有限,使用低维目标表示更难学习最优策略。因此,提出两种类型的目标表示组合来平衡权衡:低维 3D 目标位置和高维深度图像。重要的是,3D 目标位置是从第三视角相机获得的,以确保目标也在相机视图中,并且可以一致地跟踪其噪声位置。深度图像补充有关目标几何的信息。
动态和感知的域随机化。应用广泛的域随机化来确保可靠的模拟-到-真实域迁移。
使用 Fourier GR1 人形机器人,它有两条手臂和两只多指手。每条手臂有 7 个自由度 (DoF)。对于大多数实验,使用 Fourier 手,每只手有 6 个驱动 DoF 和 5 个欠驱动 DoF。为了展示跨具身的泛化,在 Inspire 手上包含结果,每只手有 6 个驱动 DoF 和 6 个欠驱动 DoF。硬件的质量特性、表面摩擦、手指和手掌形态以及拇指驱动都有很大不同。本文使用 NVIDIA Isaac Gym 模拟器 [36]。
感知。在模拟和现实世界迁移中使用密集和稀疏目标特征的组合进行策略学习。在现实世界中,通过将 RealSense D435 深度摄像头安装到人形机器人的头部来设置自我为中心视角摄像头,并通过将另一个 RealSense D435 深度摄像头放在机器人前面的三脚架上来设置第三视角摄像头。在模拟中,同样设置一个自我为中心视角摄像头和一个第三视角摄像头,通过根据真实摄像头姿势标定摄像头姿势。密集物体特征是通过直接从自我中心视角摄像头读取深度观测值获得的。稀疏特征是通过从第三视角摄像头近似物体的质心获得的,使用与 Lin [31] 类似的技术。如上图所示,利用 Segment Anything Model 2 (SAM2) [46] 在每个轨迹序列的第一帧为感兴趣的目标生成分割掩码,并利用 SAM2 的跟踪功能在所有剩余帧中跟踪该掩码。为了近似计算物体的 3D 质心坐标,计算图像平面中掩码的中心位置,然后从深度摄像头获取噪声深度读数以恢复相应的 3D 位置。感知流水线以 5 Hz 运行,以匹配神经网络策略的控制频率。