25年3月来自北京人形机器人创新中心和香港科大(广州分校)的论文“Trinity: A Modular Humanoid Robot AI System”。
近年来,人形机器人的研究越来越受到人们的关注。随着各类人工智能算法的突破,以人形机器人为代表的具身智能备受期待。强化学习(RL)算法的进步大大提高人形机器人的运动控制和泛化能力。同时,大语言模型(LLM)和视觉-语言模型(VLM)的突破性进展为人形机器人带来更多的可能性和想象力。LLM使人形机器人能够从语言指令中理解复杂任务并执行长期任务规划,而VLM则大大增强机器人对环境的理解和交互。本文介绍一种集成 RL、LLM 和 VLM 的人形机器人 AI 系统Trinity。通过结合这些技术,Trinity 可以在复杂环境中高效控制人形机器人。
多年来,机器人技术经历了重大的发展与研究,并以各种形式取得了令人瞩目的成果。其中,人形机器人由于与人类高度相似,近年来受到越来越多的关注。由于人形机器人可以直接在人类的生活和工作空间中操作,因此有望完成更复杂的任务。波士顿动力公司的 Atlas 人形机器人展示出色的机动性,而 Digit 则针对工业场景精心打磨人形机器人。特斯拉和 Figure AI 等公司在使用大语言模型和端到端学习方面表现出巨大潜力。此外,来自 宇树(Unitree) 和 PNDbotics [1] 的机器人通过不同的算法实现类人特征。基于大语言模型的机器人研究和应用层出不穷。大量研究表明,大语言模型(LLM)[2]–[4]和视觉-语言模型(VLM)[5]–[9]可以赋予机器人显著的语义规划和逻辑推理能力,使它们能够直接通过自然语言理解和执行复杂的指令。但这些研究通常针对配置相对简单的机器人,几乎所有的机器人都已经拥有优秀的控制器。相比之下,由于人形机器人的控制难度极大,基于人形机器人的大型模型研究很少,或者只能完成仅涉及上身控制的任务,更多的是注重任务理解和规划。随着强化学习在机器人领域应用的突破[10]–[12],在解决复杂人形机器人的控制问题上取得重大进展[13],[14]。首先,基于强化学习的双足机器人控制器可以完成许多任务,包括行走[15]、跳跃[11]和跑步[16]。其次,越来越多的工作是使用基于强化学习的控制器来完成全尺寸人形机器人的复杂任务。目前,强化学习严重依赖于模拟环境中的训练[17]。对于有腿机器人,充分利用模拟环境可以模拟许多场景,从而训练出鲁棒的控制器。然而,当研究全身控制和操控问题时,模拟和现实之间的差距变得更大。这使得在模拟环境中训练可以泛化到现实世界的控制器变得困难,特别是当它涉及到人形机器人所需复杂的长期交互和变形环境时。
未来人形机器人的软件架构应该是什么样的?模块化和分层结构是一个不错的选择。人形机器人是最复杂的机器人系统之一,使用模块化和分层方法来处理复杂系统的想法已经存在很长时间了[18],[19]。如上所述,目前有许多模型适合处理人形机器人上的不同任务,例如视觉理解、运动规划和控制。然而,这些模型往往是孤立的,尚未成功地集成并应用于人形机器人。因此,未来人形机器人的软件系统需要一个能够整合这些不同模型的框架,使它们协同工作,实现更高效、更智能的控制和操作。这种集成不仅可以提高系统的整体性能,还可以增强其在复杂环境中的适应性。此外,模块化和层次化设计可以为系统提供更好的可解释性,这对于复杂机器人的操作非常重要。
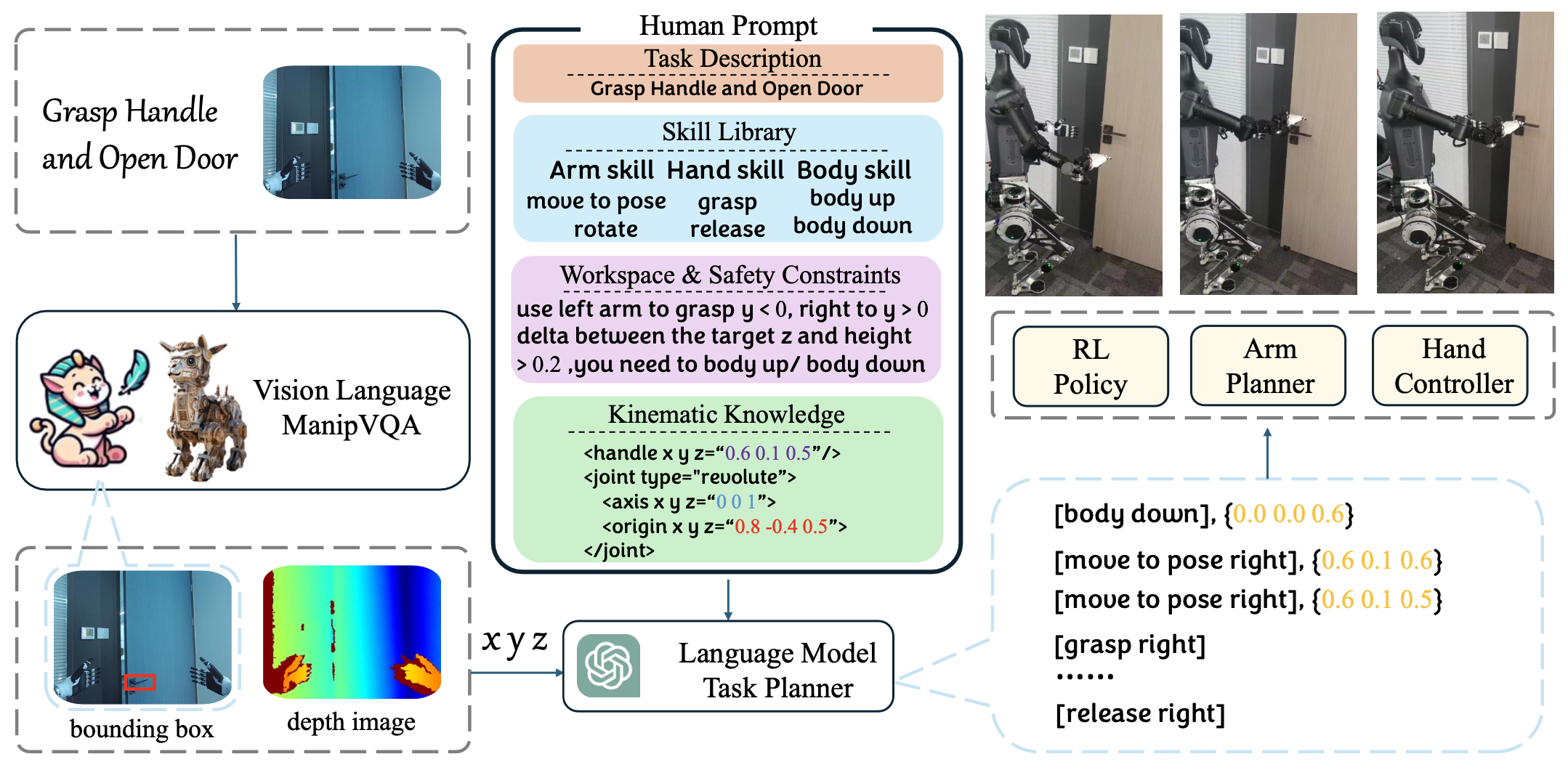
本文提出的Trinity 是一个综合性人形机器人系统,集成大语言模型 (LLM)、视觉-语言模型 (VLM) 和强化学习 (RL)。模块化人形机器人 AI 系统如图所示:
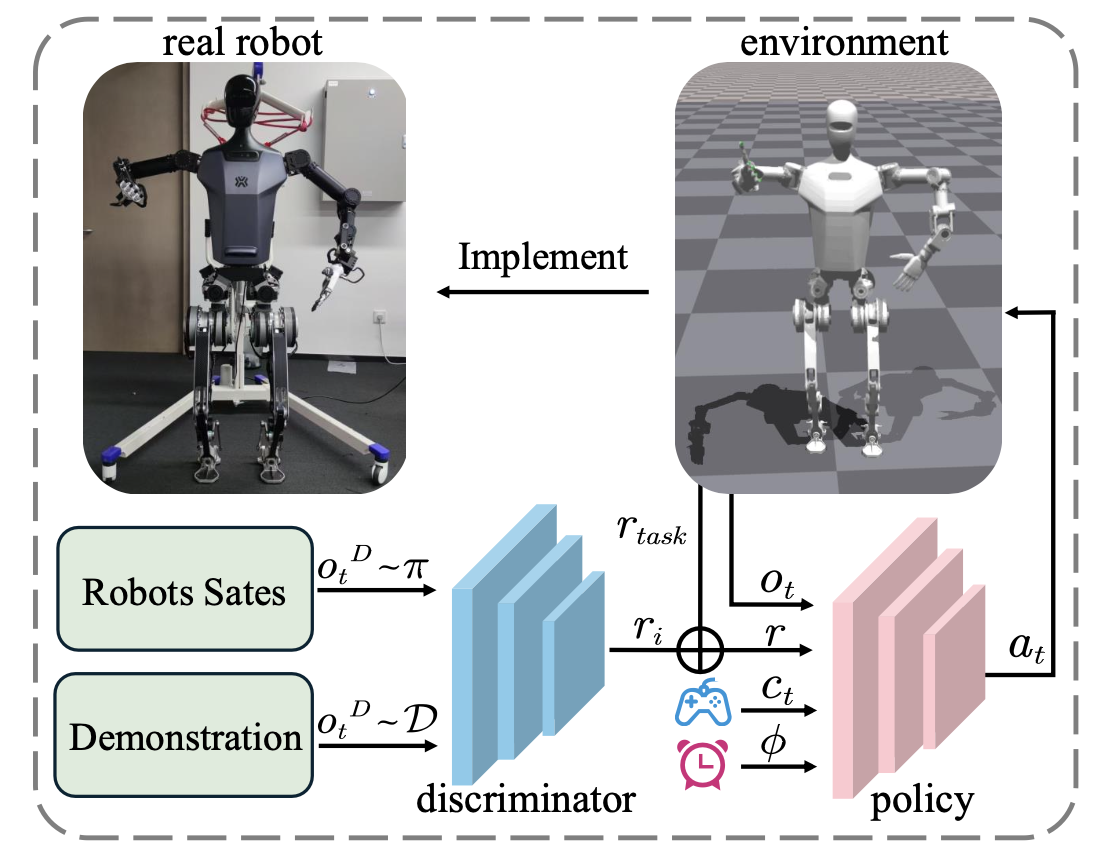
模块 1:基于对抗性运动先验的人形运动
将人形运动表述为具有 (S, A, R, p, γ) 的马尔可夫决策过程 (MDP)。S 是状态空间。A 表示动作空间,R 表示奖励函数,p 表示从当前状态 s_t 到下一个状态 s_t+1 的转换概率,γ ∈ [0, 1] 是奖励折扣因子。在 时刻 t 时,策略根据当前状态输出动作。随后,状态根据转换函数 s_t+1 ∼ p(s_t+1 |s_t , a_t) 转换到 s_t+1。训练的目标函数是通过优化策略 π(a_t|s_t) 的参数 θ 来最大化回报奖励。
为了让机器人能够更自然地与世界互动,引入对抗性运动先验 (AMP) [27],以强制策略以人类的方式执行动作,而不是跟踪演示的关节。AMP 设计一个鉴别器 D(s_t , a_t) 来区分从演示中采样或由策略生成的状态转换。
RL 和 AMP 损失将加在一起,并通过包含actor、critics和鉴别器的策略网络反向传播。对于运动策略训练,遵循之前的工作 [1] 来构建周期性奖励 r_p、命令奖励 r_c 和正则化奖励 r_re。与之前的方法相比,这里将手臂动作与策略分开,并随机设置每个手臂关节的扭矩。通过这种方式,将关节运动视为扰动,并使策略能够处理各种上身运动。对于周期性奖励,模拟脚在摆动阶段和站立阶段在空中移动,此时脚应该稳稳地固定在地面上。
每个周期性奖励成分由一个系数 α_i、一个使用冯·米塞斯分布数学期望(如 [20])的相位指示函数 I_i (φ) 和一个相位特定的奖励函数 V_i (s_t) 组成。φ 表示周期时间,i 表示相位是站立阶段还是摆动阶段。摆动阶段和站立阶段依次发生,共同覆盖整个周期。摆动阶段的持续时间由比率 ρ ∈ (0,1) 定义,而站立阶段则持续剩余时间 1−ρ。
在现实世界的移动操作任务中,人形机器人需要站立或移动。为了通过调整步态参数使策略能够在两种模式之间转换,引入了周期性奖励系统。利用这两种步态,实现有限状态机 (FSM) 来管理行走和站立之间的转换,站立步态旨在保持双脚静止或保持站立姿势。与站立相比,行走步态在从较大干扰中恢复人形机器人方面具有显著优势。
命令奖励,鼓励机器人在特定方向上保持速度不变。
为了提高从模拟-到-现实的迁移,将正则化奖励纳入框架。正则化奖励旨在减少网络输出带来的扰动,提高平滑度和安全性。奖励项如表所示。

接着,a_t 表示策略生成的动作,q ̇ 和 q ̈ 表示每个关节的速度和加速度。动作差异奖励,迫使网络输出更平滑的动作,从而减少全身人形机器人的抖动。其余正则化奖励,分别限制机器人的速度、加速度和扭矩,以避免电机过载。总之,策略训练的概览如图所示。
模块 2:VLM 感知
视觉-语言模型 (VLM) 是一种结合视觉和语言信息的人工智能模型,能够处理图像和文本数据,以理解和生成与视觉内容相关的自然语言描述。VLM 的核心在于其多模态学习能力,它从视觉和语言模态中提取特征并建立它们之间的关联。通过这种多模态学习,VLM 不仅可以识别物体,还可以理解场景中的语义信息,从而为人形机器人提供增强的感知和理解能力。
在该模块化人形机器人系统中,视觉-语言模型 (VLM) 起着至关重要的作用。VLM 使机器人能够更好地理解和解释自然语言指令,同时整合视觉信息来感知和理解周围环境。通过 VLM,机器人可以将语言与视觉信息联系起来,使其能够更准确地执行各种任务。从数学上讲,可以将 VLM 的核心功能描述如下:给定一个输入图像 I 和一个相关文本查询 Q,VLM 的目标是生成响应 R。
VLM 通常由视觉编码器和语言编码器组成。视觉编码器 f_v 将图像 I 转换为特征 v,语言编码器 f_l 将查询 Q 转换为特征 q。这些特征由多模态模块 f_m 融合以生成 z,解码器 f_d 以此生成响应 R。
通过这种方式,VLM 学会将视觉和语言信息关联起来,为人形机器人提供强大的环境理解能力。
之所以选择使用 ManipVQA [43] 作为 VLM 的一部分,有几个原因。ManipVQA 是一个专门为机器人操作任务设计的框架,能够注入机器人的可操作性和物理基础信息,这对于人形机器人系统在执行实际操作任务时至关重要。传统的 VLM 可能缺乏对机器人特定知识的理解,通过视觉-问答,可以更好地帮助机器人理解物体的可操作性和物理概念,从而提高其在操作任务中的表现。
ManipVQA 收集了多样化的图像数据集,并采用了统一的 VQA 格式和微调策略,使其能够有效地将机器人特定知识与视觉推理能力结合起来。这意味着机器人系统可以更好地应对不同场景下的各种挑战,增强其通用性和适应性。它在实证评估中表现出色,在机器人模拟器和各种视觉任务基准测试中取得优异的成绩。这为人形机器人系统提供可靠的技术支持,使其能够更高效地完成各种复杂的操作任务。
模块 3:LLM 任务规划器
框架的核心是基于大语言模型的任务规划器,将感知结果与用户指令相结合,通过顺序调用人形机器人基本技能库,高效执行日常任务。
机器人技能库由手臂技能、手部技能和身体技能三部分组成。手臂技能包括向左移动和向右移动,控制左臂或右臂的末端执行器到目标姿势。换臂是指人形机器人将物体从一只手转移到另一只手,从而扩展其双手工作空间。此动作允许机器人在其操作区域内重定位物体,使其在操作物品时具有更大的灵活性和范围,特别是在可能需要重新定位一只手或释放一只手以执行其他任务的情况下。此外,遵循 [44] 来制定旋转技能和目标姿势。手部技能包含每只手的抓握和释放。将手指的每个自由度预定义为抓握状态或释放状态,以与可移动物体交互。身体技能由上身和下身组成,改变骨盆的高度,以增加人形机器人的工作空间。利用 GPT-4 作为基于 LLM 的任务规划器在 Trinity 系统中进行推理。为了处理双手任务所需的顺序或同时控制,利用链式结构来形式化任务规划器的操作。该框架允许 LLM 逐步生成一系列技能。除了手部技能之外,其他技能都需要分配从推理结果中获得的目标值。除了任务说明之外,设计的提示还包括人形机器人的背景细节,例如用于手部切换和高度调整的双手坐标和工作空间。为了操纵铰接体,按照 [44] 引入运动-觉察提示框架,以帮助智体理解可移动体的运动学。
总体而言,该方法采用视觉-语言感知模块与大语言模型 (LLM) 结合来解释和执行人形机器人的任务指令。感知模块利用 RGB-D 摄像头,通过生成边框来识别物体的可移动部分,并从深度数据中计算它们的精确 3D 位置。目标的姿态获取方式与 [44] 类似。这些空间细节随后由基于 LLM 的任务规划器处理,该规划器根据多个输入(包括任务描述、技能库、工作空间约束、安全提示和先前的运动学知识)合成动作序列。然后,机器人的控制系统执行生成的动作命令,从而高效、安全地完成任务。
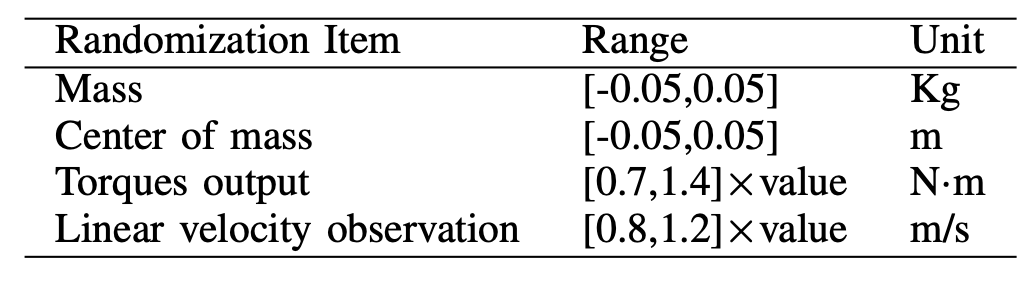
通过近端策略优化 (PPO) [45] 训练策略,这是一种流行的无模型强化学习算法,在 Isaac Gym 上并行运行 4096 个模拟环境。在人形机器人运动场景中,动作用 a_t 表示,即每个腿驱动关节的期望位置。观测值 o_t 包含当前的线速度和角速度、(x, y, yaw) 中的平均速度、局部框架中骨盆的方向、每个腿和手臂关节的位置和速度以及最后一步的动作。除了本体感觉之外,c_t = (v^x, v^y, h^z, ω^yaw) 也被设计用来驱动人形机器人按照命令移动。周期信号包括周期时间的正弦和余弦以及摆动相比率 ρ。随机化项目的详细信息如表所示。机器人刚体质量值和位置的随机化,使策略能够适应机器人组件、电机模型和观测噪声中的不确定性。
为了验证方法在操纵铰接式体时的鲁棒性,设计一个场景,要求人形机器人抓住把手并打开门。实验细节如图所示。结果表明,当机器人与铰接式工件之间的相对距离不理想,导致操作过程中受到外力干扰时,该方法使人形机器人能够根据外力调整其静态位置,从而成功完成任务。
