25年3月来自休斯敦 Rice U 的论文“Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models”。
大语言模型 (LLM) 在复杂任务中表现出卓越的能力。大型推理模型 (LRM)(例如 OpenAI o1 和 DeepSeek-R1)的最新进展通过利用监督微调 (SFT) 和强化学习 (RL) 技术来增强思维链 (CoT) 推理,进一步提高了数学和编程等系统 2 推理领域的性能。然而,虽然较长的 CoT 推理序列可以提高性能,但它们也会因冗长和冗余的输出而引入大量计算开销,这被称为“过度思考现象”。
高效推理旨在优化推理长度,同时保留推理能力,可提供实际好处,例如降低计算成本和提高对实际应用的响应能力。尽管高效推理具有潜力,但仍处于研究的早期阶段。
本文是一个结构化综述,系统地调查和探索当前在 LLM 中实现高效推理的进展。总体而言,依托 LLM 的内在机制,将现有工作分为几个关键方向:(1)基于模型的高效推理,考虑将全-长度推理模型优化为更简洁的推理模型或直接训练高效推理模型;(2)基于推理输出的高效推理,旨在在推理过程中动态减少推理步骤和长度;(3)基于输入提示的高效推理,旨在根据输入提示的属性(例如难度或长度控制)来提高推理效率。此外,介绍使用高效数据训练推理模型的方法,探索小型语言模型的推理能力,并讨论评估方法和基准测试。
大语言模型 (LLM) 已成为极为强大的 AI 工具,在自然语言理解和复杂推理方面展现出先进的能力。最近,专注于推理的 LLM(也称为大型推理模型 (LRM) [91])的出现,例如 OpenAI o1 [61] 和 DeepSeek-R1 [31],显著提高了它们在 System-2 推理领域 [8, 44](包括数学 [16, 35] 和编程 [7, 17])中的性能。这些模型从基础预训练模型(例如 LLaMA [30, 80]、Qwen [95])和下一个 token 预测训练 [23] 演变而来,利用思维链 (CoT) [86] 提示在得出最终答案之前生成明确的、逐步的推理序列,大大提高它们在推理密集型任务中的有效性。
LLM 中的推理能力通常是通过监督微调 (SFT) 和强化学习 (RL) 来开发的,这可以促进迭代和系统性的问题解决能力。具体来说,OpenAI o1 [61] 训练流水线可能将 SFT 和 RL 与蒙特卡洛树搜索 (MCTS) [71] 和处理奖励模型 (PRM) [47] 结合起来。DeepSeek-R1 最初使用 SFT 和由 RL 训练的 DeepSeek-R1-Zero 生成的长 CoT 推理数据进行微调,然后通过基于规则的奖励函数通过 RL 进一步完善。
然而,虽然长 CoT 推理显著提高了推理能力和准确性,但引入类似 CoT 的机制(例如,自洽性 [84]、思维树 [96]、激励 RL [31])也会导致输出响应过长,从而导致大量的计算开销和思考时间。例如,在向 OpenAI-o1、DeepSeek-R1 和 QwQ-32B-Preview 询问“2 加 3 的答案是多少?”[10] 时,就会出现“过度思考问题”。此类模型的推理序列有时会跨越数千个 tokens,其中许多是冗余的,对得出正确答案没有实质性贡献。这种冗长直接增加了推理成本和延迟,限制了推理模型在计算敏感的现实应用中的实际使用,包括实时自动驾驶系统、交互式助手、机器人控制和在线搜索引擎。
高效推理,特别是缩短推理长度,具有显著的好处,例如降低成本和增强实际部署中的推理能力。最近,许多研究 [32、33、54、56、98] 试图开发更简洁的推理路径,使高效推理成为一个突出且快速发展的研究领域。
如图所示:一个开发 LLM 高效推理的流水线

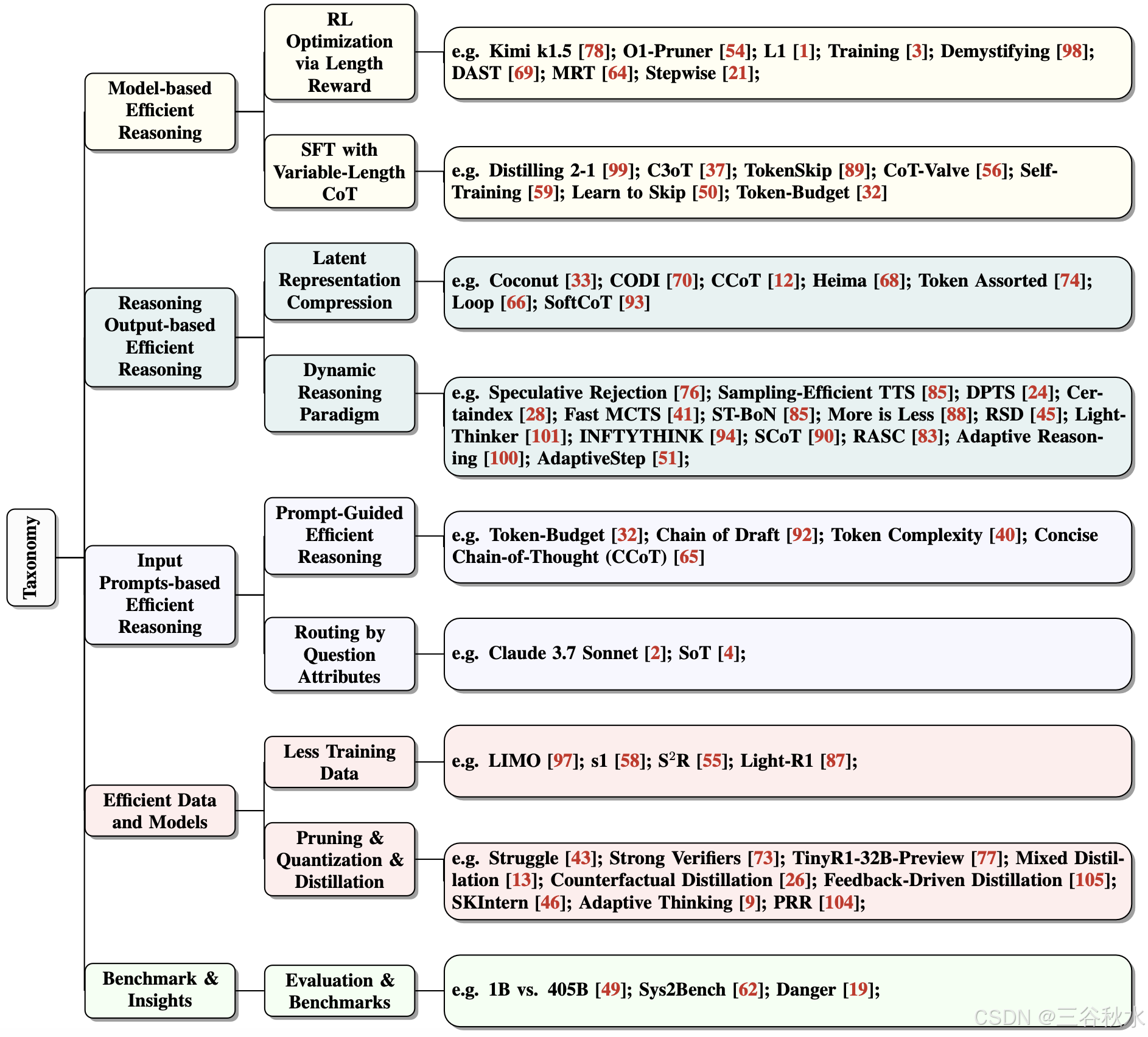
如图所示,现有的高效推理工作分为以下几个主要方向:(1)基于模型的高效推理,包括将全-长度推理模型优化为更简洁的推理模型或直接微调模型以实现高效推理;(2)基于推理输出的高效推理,在推理过程中动态减少推理步骤和输出长度;(3)基于输入提示的高效推理,通过利用提示属性(如提示引导长度或提示难度)来提高推理效率。与 LLM 中模型压缩技术的定义正交,例如量化 [27, 48] 或 kv-缓存压缩 [52, 103],它们专注于压缩模型大小并实现轻量级推理,LLM 中的高效推理强调通过优化推理长度和减少思考步骤来实现智能和简洁的推理。
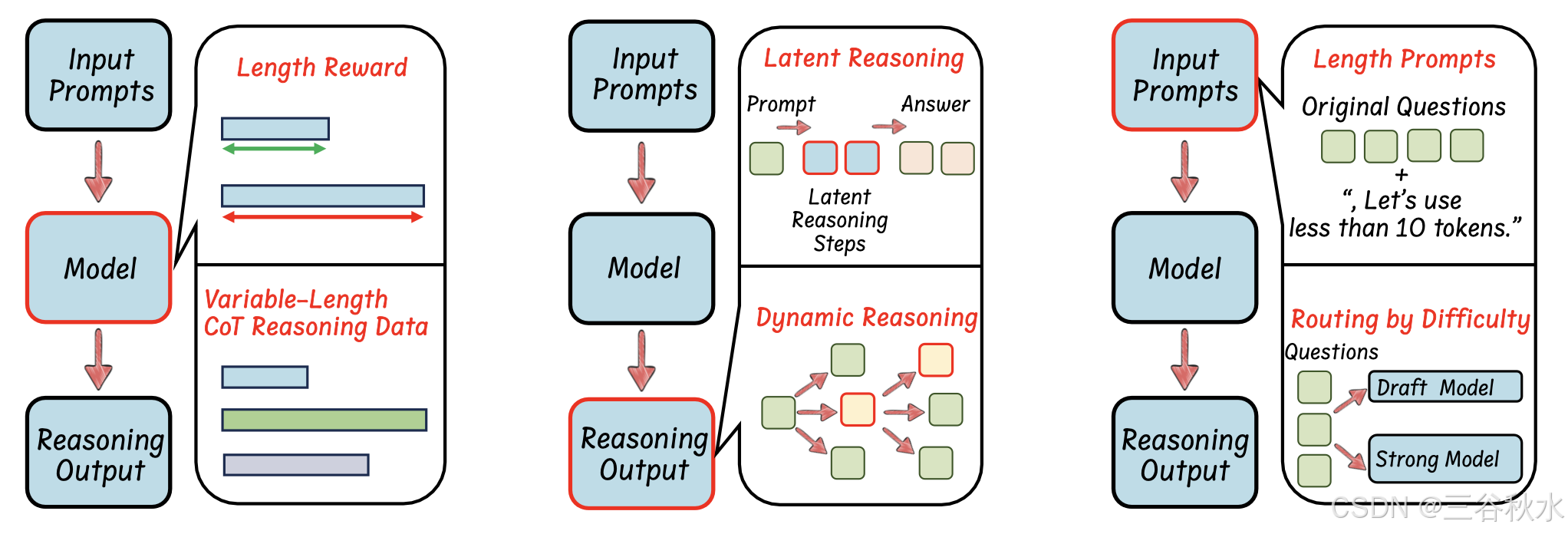
本文综述对各种方法的分类如下图所示:基于模型的高效推理,包括长度奖励的 RL 优化和可变长度 CoT 的 SFT;(2)基于推理输出的高效推理,包括潜表征压缩和动态推理范式;(3)基于输入提示的高效推理,包括提示-引导的高效推理和问题属性的路由方法;(4)高效数据和模型,包括少训练数据和裁剪、量化&蒸馏;(5)基准和视角,即评估。
长 CoT 推理中的“过度思考现象” [10,78] 是指 LLM 生成过于详细或不必要复杂的推理步骤,从而损害其解决问题的效率的现象。具体而言,一些现代推理 LLM(尤其是一些具有推理能力的较小参数规模模型)往往会产生冗长的推理或多余的中间步骤,使得它们无法在用户定义的 token 预算用完之前提供答案,甚至更糟:由于冗长的推理步骤引入错误或降低逻辑清晰度而提供不正确的答案。
如图展示过度思考的例子。虽然过度思考 CoT 推理在其初始步骤中产生正确的答案,但其生成的推理步骤通常包括多个多余的中间步骤,从而导致不必要的复杂性和清晰度降低。考虑到与 LLM 解码阶段相关的极端资源成本(例如,OpenAI o1 每生成 100 万个 token 的成本为 60 美元),这是非常不受欢迎的行为;不言而喻,如果扩展推理生成导致错误答案,情况会更糟。相比之下,步骤更少的高效思考可以获得正确答案,这凸显了减少过度思考 token 的额外预算的可能性。

注:高效推理的挑战之所以被认为意义重大,是因为具有推理能力模型的预训练配方通常明确鼓励模型生成扩展推理步骤以追求正确答案。例如,当 DeepSeek-R1-Zero 训练时间更长时,其响应长度和基准性能都会增加 [31];观察这两种趋势通常被认为是成功推理支持训练配方的代表。因此,想要在推理时实现推理效率,在设计上就是违背模型的某些预训练目标,因此需要进行不凡的考虑。这项工作旨在总结不同的思维流派及其示范方法,以实现拥有高效而有能力推理模型这一具有挑战性但有益的目标。
基于模型的高效推理
从模型角度来看,这类工作侧重于对 LLM 进行微调,以提高其简洁高效推理的内在能力。
具有长度奖励设计的 RL
大多数推理模型都是使用基于 RL 的方法进行训练的(例如,DeepSeek-R1 [31]、DeepSeek-R1-Zero [31]、OpenAI o1 [61]、QwQ-32B-Preview [79]),这些方法侧重于准确性奖励和格式奖励 [31]。为了提高推理长度效率,一些研究提出将长度奖励整合到 RL 框架中,从而有效缩短推理过程(如图所示)。原则上,长度奖励会为简短、正确的答案分配更高的分数,同时惩罚冗长或不正确的答案,从而优化推理路径的长度。

现有的工作利用传统的 RL 优化技术结合显式的基于长度奖励来控制 CoT 推理的长度。下表显示一些详细的长度奖励。
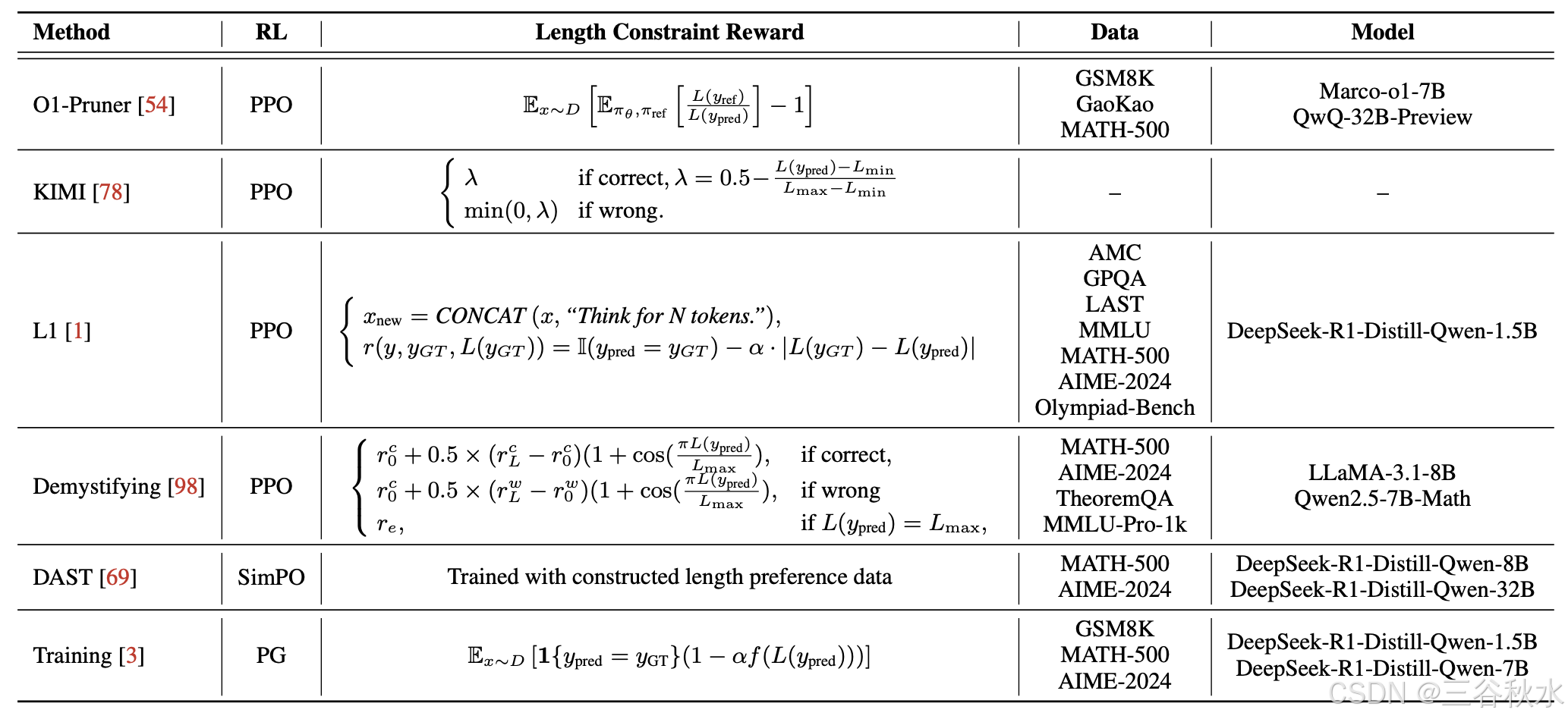
这些基于 RL 的方法可以缓解具有推理能力的 LLM 中的过度思考,其中过度思考是指不必要地延长推理过程,导致推理时间更长并超出计算预算。通过实现与 LLM 原始推理能力的几乎无损对齐,这些预算高效的 RL 策略使资源受限场景中推理 LLM 的部署变得民主化。
带有可变长度 CoT 数据的 SFT
使用可变长度 CoT 数据对 LLM 进行微调是提高推理效率的有效方法。如图所示,这一系列工作通常涉及:(1)通过各种方法构建可变长度 CoT 推理数据集,以及(2)将 SFT 与收集的推理模型数据结合使用,使 LLM 能够学习封装有效知识的紧凑推理链。注:这种方法不仅限于 RL 训练的推理模型;它还可以通过注入高效的推理能力来直接增强推理模型,类似于蒸馏推理模型中使用的能力。(例如,DeepSeek-R1-Distill-Qwen [31])。

下表是 CoT 长度控制中不同策略优化方法的比较:

构建可变长度 CoT 推理数据集。可变长度 CoT 推理数据集是指可以指导 LLM 获得正确答案的长/短推理步骤的数据集。现有的研究通常通过向预训练的推理模型提出问题来收集长 CoT 数据。基于长 CoT 数据,关键挑战是:如何收集短 CoT 数据?总体而言,可变长度 CoT 推理数据集可以通过后推理或推理过程中创建。在下表中列出一些详细方法。
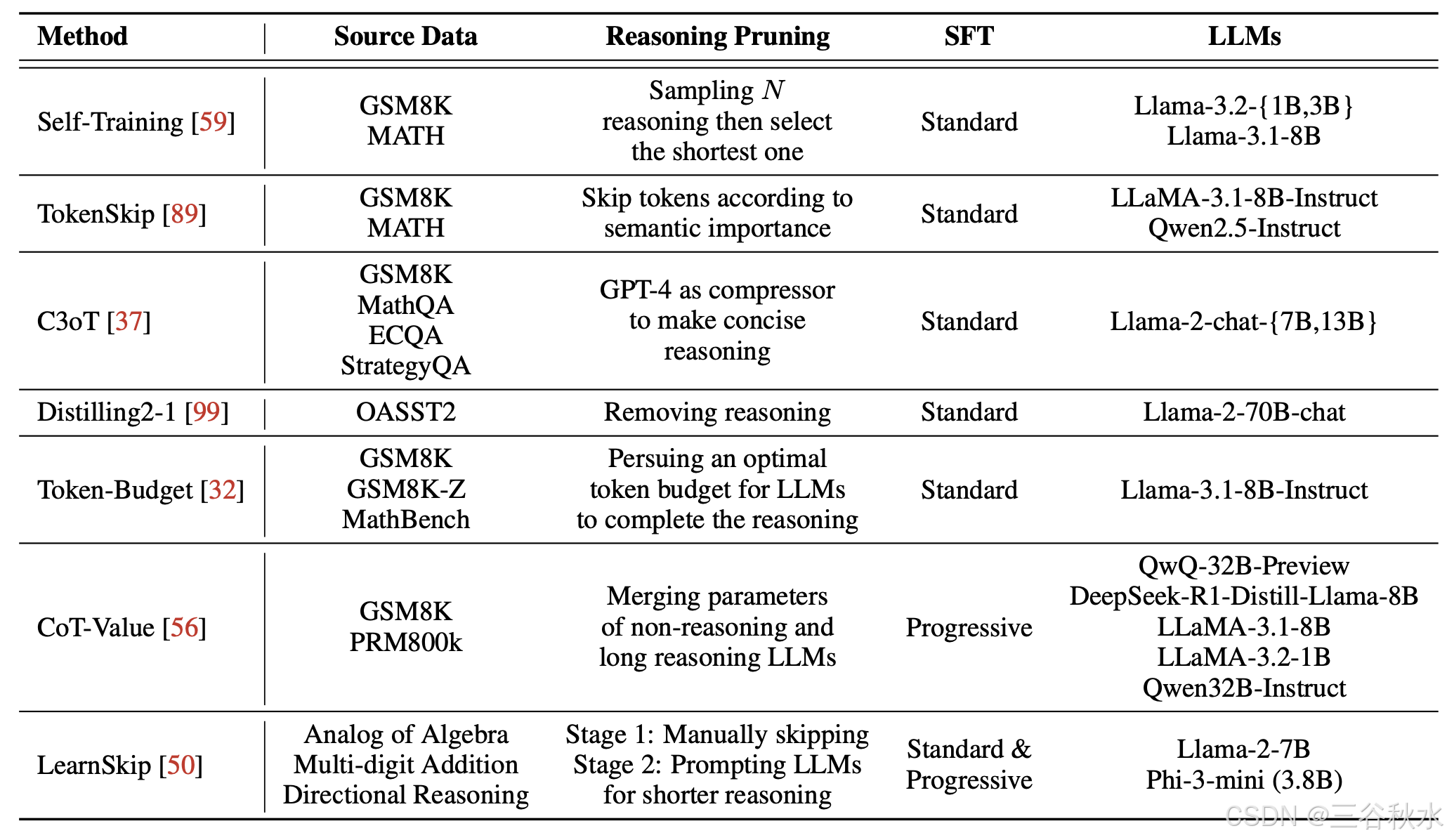
微调方法。在收集可变长度的 CoT 数据后,现有的研究通过多种方式对 LLM 进行微调以实现高效推理,其中包括标准微调(例如,参数高效微调,如 LoRA [36] 或全微调)和渐进微调。