代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# 设置 Chrome 浏览器选项
chrome_options = Options()
chrome_options.add_argument("--start-maximized") # 启动时最大化窗口
# 指定 ChromeDriver 路径
driver_path = r'D:\software\chromedriver\chromedriver127\chromedriver-win64\chromedriver.exe'
# 定义公共常量
BASE_URL = "http://www.***.com"
TARGET_XPATH = "/html/body/div[6]/ul[1]/li/font[1]/b"
SUCCESS_TEXT = "5"
NEW_PAGE_URL = "http://www.***.com/Home/Category/index/fClass/295.html"
LI_TARGET_XPATH = "//ul[@class='class_gdlist_frm']//li"
# 创建 Service 对象并传入 ChromeDriver 路径
service = Service(executable_path=driver_path)
# 启动浏览器并打开百度首页
driver = webdriver.Chrome(service=service, options=chrome_options)
driver.get(BASE_URL)
# 等待页面加载完成,假设等待某个元素加载完成
# 企查查已陪伴您1428天
WebDriverWait(driver, 600).until(
EC.presence_of_element_located((By.XPATH, TARGET_XPATH))
)
# 获取目标元素
element = driver.find_element(By.XPATH, TARGET_XPATH)
# 获取并打印该元素的文本内容
element_text = element.text
if element_text == SUCCESS_TEXT:
driver.get(NEW_PAGE_URL) # 跳转到新页面
# 等待页面加载完成
time.sleep(2) # 等待 2 秒以确保页面加载
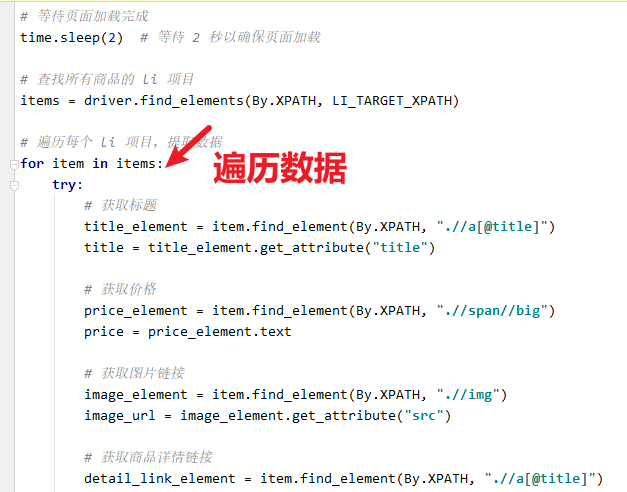
# 查找所有商品的 li 项目
items = driver.find_elements(By.XPATH, LI_TARGET_XPATH)
# 遍历每个 li 项目,提取数据
for item in items:
try:
# 获取标题
title_element = item.find_element(By.XPATH, ".//a[@title]")
title = title_element.get_attribute("title")
# 获取价格
price_element = item.find_element(By.XPATH, ".//span//big")
price = price_element.text
# 获取图片链接
image_element = item.find_element(By.XPATH, ".//img")
image_url = image_element.get_attribute("src")
# 获取商品详情链接
detail_link_element = item.find_element(By.XPATH, ".//a[@title]")
detail_link = detail_link_element.get_attribute("href")
# 打印提取的数据
print(f"标题: {title}")
print(f"价格: {price}")
print(f"图片: {image_url}")
print(f"超链接: {detail_link}")
print("-" * 50) # 分隔符
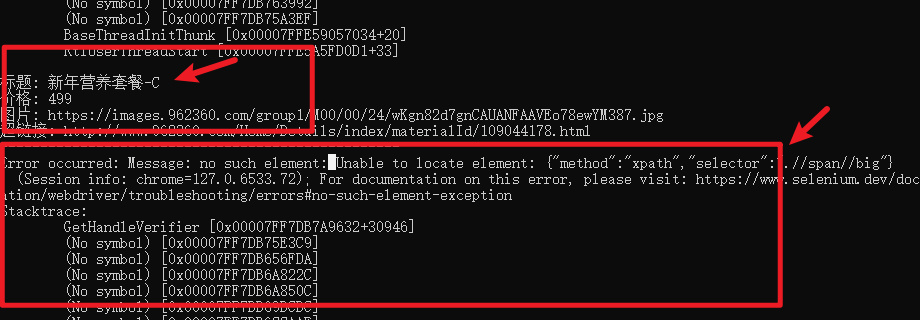
except Exception as e:
print(f"Error occurred: {e}")
print("Element Text:", element_text)
# 等待一段时间,保持浏览器开启
input("Press Enter to close the browser...")
# 关闭浏览器
# driver.quit()
解释:
为什么有些时候获取到数据有些时候没有获取到并报错:这是因为有些时候遍历下的元素不规整,没有获取到对应的标签导致的: