获取网址的xpath:
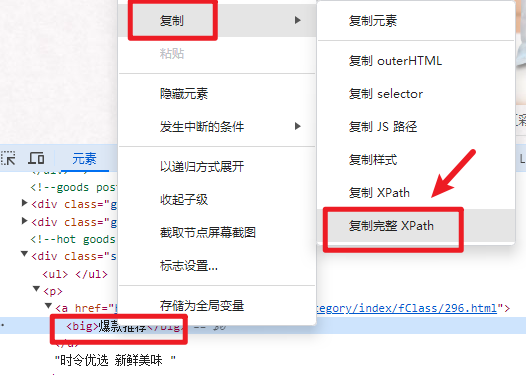
代码:修改网址
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 设置 Chrome 浏览器选项
chrome_options = Options()
chrome_options.add_argument("--start-maximized") # 启动时最大化窗口
# 指定 ChromeDriver 路径
driver_path = r'D:\software\chromedriver\chromedriver127\chromedriver-win64\chromedriver.exe'
# 创建 Service 对象并传入 ChromeDriver 路径
service = Service(executable_path=driver_path)
# 启动浏览器并打开百度首页
driver = webdriver.Chrome(service=service, options=chrome_options)
driver.get("http://www.****.com")
# 等待页面加载完成,假设等待某个元素加载完成
WebDriverWait(driver, 10).until(
# EC.presence_of_element_located((By.XPATH, "/html/body/div[6]/ul[1]/li/font[1]/b"))
EC.presence_of_element_located((By.XPATH, "/html/body/div[8]/p/a/big"))
)
# 获取目标元素
# element = driver.find_element(By.XPATH, "/html/body/div[6]/ul[1]/li/font[1]/b")
element = driver.find_element(By.XPATH, "/html/body/div[8]/p/a/big")
# 获取并打印该元素的文本内容
element_text = element.text
print("Element Text:", element_text)
# 等待一段时间,保持浏览器开启
input("Press Enter to close the browser...")
# 关闭浏览器
# driver.quit()
不关闭浏览器 解释:
