引言
最近数据分析特别火,很多小伙伴也开始学习或从事数据采集相关的工作。然而现在网站数据是一个非常重要的资产,网站一般都不会让外人随便把数据采集走,为此设计了一系列的反爬机制。为了避开这些问题,使用代理IP访问网站是最简单有效的方法。它可以使访问流量看起来像多用户发出而非同一用户,避免被网站识别为爬虫软件。
现在市面上代理IP服务平台也有很多了,由于工作需求和日常研究,我使用过很多家的代理ip产品,整体感受是速度差不多、价格差不多;一次偶然的搜索,让我注意到了这家在百度搜索中稳居榜首的代理IP服务商------青果网络;对这家代理的印象是挺有名的、业界数一数二的代理服务商,听说不少大厂的同行们有长期在合作;那就随机来测试一下,看看它究竟好不好用。

获取代理
首先我们打开青果网络的首页,在注册/登录后进行实名认证,之后便可选购需要的服务了。这次我们体验一下短效代理。从导航栏直接进去购买页面。
在购买页面可以根据需求选购IP,这里我们使用默认的配置。
结算之后,在控制台就可以找到我们购买的服务。

如果要使用的话,最好是使用API接口获取代理IP。点击提取IP即可进去API接口配置页面。
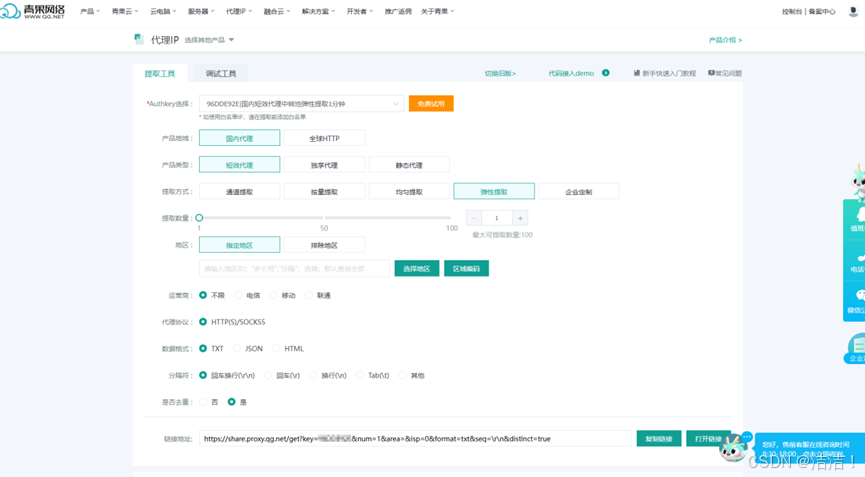
在这里调整参数就可以使用底部的链接获取到IP地址了。不过在开始使用前一定要将自己的IP地址添加到白名单中。怎么样,配置代理服务是不是很简单呢?
性能测试
接下来我们使用程序测试一下青果网络的IP代理好不好用。我们主要从重复率、可用率、响应速度和稳定性几个角度来测试。先说说测试结果,再来给大家分享一下测试思路。
重复率
有些网站因为有防爬虫机制,访问IP可能会被屏蔽,并且屏蔽期一般都比较长,所以平台提供的IP重复率一定要低,否则会严重影响业务开展的效率。这里我们获取了500次IP,重复率为0%。这说明我们获取到的IP完全没有重复的,这真的非常难得,因为重复率越低就说明厂家持有的IP数量越多。而完全无重复则说明厂家自信自己的IP池足够大,敢于主动为用户过滤重复IP。
可用率
由于平台的IP地址来源比较广泛,加上前面说过的网站屏蔽的情况,所以难免会有些IP从一开始就不通。这里我们获取了500次IP,可用率为100.00%。要知道一般来说,这种代理IP服务都是多用户复用的,所以一些IP在上一个用户那里被屏蔽了,再下发到下一个用户这种事非常常见。而全部可用则说明厂家为每个用户准备的IP是相对独立的。
响应速度
我们使用IP访问网站的时候,需要IP对应的代理服务器转发业务,所以我们本地和代理服务器通信的延迟对业务执行效率影响会特别大。这里我们获取了500次IP并测试它们的响应速度,它们的响应时间平均值为0.41197032s。这个响应时间并不算很快,但对于全自动爬虫来说,在巧妙利用多线程的情况下是完全够用的。
稳定性
一般做爬虫任务的时候,为了避免IP太快消耗,每次发送请求都会切换一次IP,所以如果IP之间的响应速度差别特别大的话,会对业务的效率产生极大影响。一个理想的状态是所有的IP的响应速度都保持在一个比较低的区间里,所以这里我们计算了上面IP响应速度的方差为0.00043602043。这个方差非常小了,说明响应速度基本变化不大,一方面说明确实速度都不太快,但另一方面也说明整体的运行状况会非常稳定,更像正常的用户。
测试方法
整个测试的过程分为两个部分。首先我们从平台获取代理IP,之后使用IP访问百度并计算各项数据。首先我们规定了被测网址为百度,填入之前获取到的平台api接口地址,每次测试之间的等待时间为1s,最大测试次数为500次。
test_url = 'https://www.baidu.com/'
timeout = 4
api_url = 'https://share.proxy.qg.net/get?key=96DDE92E&num=1&area=&isp=0&format=txt&seq=\r\n&distinct=true'
wait = 1
max_ = 500
test_object = '青果代理'
之后我们通过get_proxy()函数来获取代理IP。先设置User-Agent头信息,模拟浏览器访问,然后发送GET请求到url。如果响应状态码为200,表示请求成功,打印并返回代理IP地址。如果连接失败,捕获ConnectionError异常,返回False表示获取代理失败。
def get_proxy(url):
try:
headers = {
'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(response.text)
return True, response.text
except ConnectionError:
return False, None
由于可能会有没获取到IP的情况存在,所以我们使用is_proxy()函数检查一下获取的结果。这里我们使用正则表达式检查结果是否满足IP地址的格式。
def is_proxy(proxy):
if re.match(r'\d+.\d+.\d+.\d+:\d+', proxy):
return True
return False
接下来我们利用刚获得的代理访问目标网站。首先我们需要把代理配置为字典模式。然后记录请求前的时间start_time。接下来使用刚才构造的proxies代理访问test_url,设定超时时间。此时记录请求后的时间end_time,就可以计算出请求所用时间used_time。最后打印代理可用性和所用时间,返回True和used_time。如果请求超时或代理失效,捕获异常并打印"代理无效",返回False。
def test_proxy(proxy=None, proxies=None):
try:
if not proxies:
proxies = {
'http': proxy
}
start_time = time.time()
requests.get(test_url, timeout=timeout, proxies=proxies)
end_time = time.time()
used_time = end_time - start_time
print('Proxy Valid', 'Used Time:', used_time)
return True, used_time
except (ProxyError, ConnectTimeout, SSLError, ReadTimeout, ConnectionError):
print('Proxy Invalid:', proxy)
return False, None
完成请求后我们需要统计和记录代理测试结果。在stats_result()函数中,将used_time_list转换为numpy数组used_time_array,用来计算均值和方差。然后打印本轮测试数、有效代理数、有效百分比、平均测试时间和方差。并且将测试结果以指定格式写入test_object测试记录.txt文件,文件名中带上当前时间戳。
def stats_result(test_object, used_time_list, valid_count, total_count):
if not used_time_list or not total_count:
return
used_time_array = np.asarray(used_time_list, np.float32)
print('Total Count:', total_count,
'Valid Count:', valid_count,
'Valid Percent: %.2f%%' % (valid_count * 100.0 / total_count),
'Used Time Mean:', used_time_array.mean(),
'Used Time Var', used_time_array.var())
now_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
with open("%s测试记录.txt" % test_object, "a+", encoding='utf-8') as f:
f.write('\n')
f.write(
'Total Count: %s, Valid Count: %s, Valid Percent: %.2f%%, Used Time Mean: %s, Used Time Var: %s 【%s】' % (
total_count, valid_count, (valid_count * 100.0 / total_count),
used_time_array.mean(), used_time_array.var(), now_time))
最后通过一个主函数调度各个功能模块。首先初始化计数器和结果列表。然后通过循环从API获取代理。如果成功获取,检查代理格式。如果格式正确,则增加测试计数total_count,并打印正在测试的代理。然后调用test_proxy函数测试代理,如果代理有效,增加有效代理数valid_count,并记录测试时间。最后调用stats_result记录统计结果。每次测试后暂停wait秒,当测试次数达到max_时,终止循环。
def main():
print('开始测试...')
used_time_list = []
valid_count = 0
total_count = 0
while True:
flag, result = get_proxy(api_url)
if flag:
proxy = result.strip()
if is_proxy(proxy):
total_count += 1
print('Testing proxy', proxy)
test_flag, test_result = test_proxy(proxy=proxy)
if test_flag:
valid_count += 1
used_time_list.append(test_result)
stats_result(test_object, used_time_list, valid_count, total_count)
time.sleep(wait)
if total_count == max_:
break
完整测试代码如下:
import requests
import time
import numpy as np
from requests.exceptions import ProxyError, ConnectTimeout, ReadTimeout, SSLError, ConnectionError
import re
test_url = 'https://www.baidu.com/'
timeout = 4
api_url = 'https://share.proxy.qg.net/get?key=96DDE92E&num=1&area=&isp=0&format=txt&seq=\r\n&distinct=true'
wait = 1
max_ = 500
test_object = '青果代理'
def get_proxy(url):
try:
headers = {
'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' }
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(response.text)
return True, response.text except ConnectionError:
return False, None
def is_proxy(proxy):
if re.match(r'\d+.\d+.\d+.\d+:\d+', proxy):
return True return False
def test_proxy(proxy=None, proxies=None):
try:
if not proxies:
proxies = {
'http': proxy }
start_time = time.time()
requests.get(test_url, timeout=timeout, proxies=proxies)
end_time = time.time()
used_time = end_time - start_time print('Proxy Valid', 'Used Time:', used_time)
return True, used_time except (ProxyError, ConnectTimeout, SSLError, ReadTimeout, ConnectionError):
print('Proxy Invalid:', proxy)
return False, None
def stats_result(test_object, used_time_list, valid_count, total_count):
if not used_time_list or not total_count:
return used_time_array = np.asarray(used_time_list, np.float32)
print('Total Count:', total_count,
'Valid Count:', valid_count,
'Valid Percent: %.2f%%' % (valid_count * 100.0 / total_count),
'Used Time Mean:', used_time_array.mean(),
'Used Time Var', used_time_array.var())
now_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
with open("%s测试记录.txt" % test_object, "a+", encoding='utf-8') as f:
f.write('\n')
f.write(
'Total Count: %s, Valid Count: %s, Valid Percent: %.2f%%, Used Time Mean: %s, Used Time Var: %s 【%s】' % (
total_count, valid_count, (valid_count * 100.0 / total_count),
used_time_array.mean(), used_time_array.var(), now_time))
def main():
print('开始测试...')
used_time_list = []
valid_count = 0 total_count = 0 while True:
flag, result = get_proxy(api_url)
if flag:
proxy = result.strip()
if is_proxy(proxy):
total_count += 1 print('Testing proxy', proxy)
test_flag, test_result = test_proxy(proxy=proxy)
if test_flag:
valid_count += 1
used_time_list.append(test_result)
stats_result(test_object, used_time_list, valid_count, total_count)
time.sleep(wait)
if total_count == max_:
break
if __name__ == '__main__':
main()
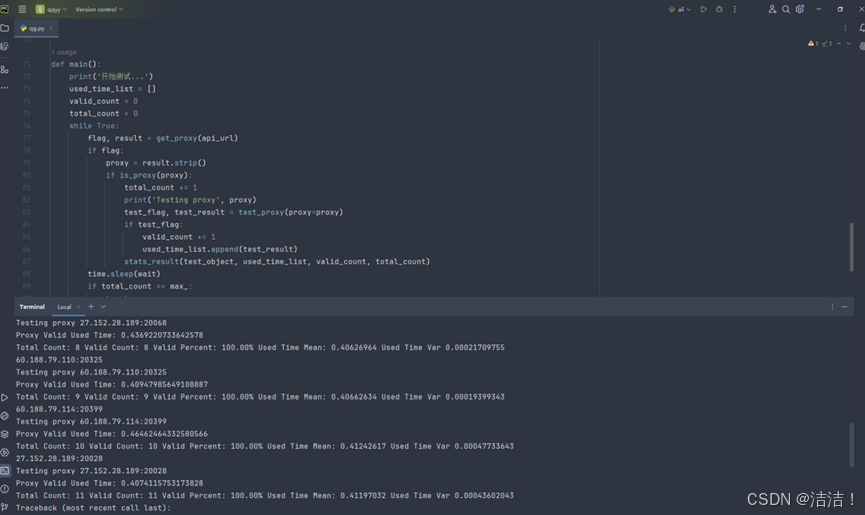
运行之后可以看到测试结果随着每次获取IP在逐条更新,等全部运行完即可看到最终结果。
总结
同时也对其它家的代理产品进行了测试,通过对比数据可以得出:
| 名称 | 套餐 | 月租价格 | API频率限制 | 每次提取上限 | 每天提取上限 | 重复率 | 可用性 | 响应速度 | 稳定性 |
|---|---|---|---|---|---|---|---|---|---|
| 青果网络 | 短效代理IP | ¥55 | 不限 | 100 | 1000 | 0% | 100% | 0.41197032s | 0.00043602043 |
| 迅代理 | 优质代理 | ¥210 | 5s | 20 | 1000 | 6.04% | 94.38% | 2.709128s | 35.12306 |
| 蘑菇代理 | 包月套餐 | ¥169 | 1s | 100 | 2000 | 10.13% | 98.4% | 0.7039269s | 2.1934047 |
| 蚂蚁代理 | - | 每个并发3元/天 | - | - | - | - | 100% | 0.56895095 | 0.14352864 |
可以看到青果网络的月租价格是最低的,并且限制都比较宽松,所以说无论是在价钱还是性能上都属于很优秀的一档。现在正好有**6小时试用活动**,感兴趣的朋友不妨来亲自体验一下。