前言
在目标检测算法中,训练出一个模型,想要知道这个模型的效果怎么样,主要是从模型的指标得出的,指标不仅在论文还是在自己学习的过程中,都是十分重要的,下边就来详细介绍一下指标的这个概念。
一、准确率(Accuracy)
定义:正确识别的目标数量与总目标数量的比率。
目标数量:图像中实际存在的目标数量,列如物体、人、车辆等,列如给出一张照片,其中有100个人,这100个人是总目标数量,然后预测出来了90个并且是正确的,那准确率就为90%。
二、IOU交并比
1、IoU计算的是“预测的边框”和“真实的边框”的交叠率,即它们的交集和并集的比值。
2、IoU等于“预测的边框”和“真实的边框”之间交集和并集的比值。
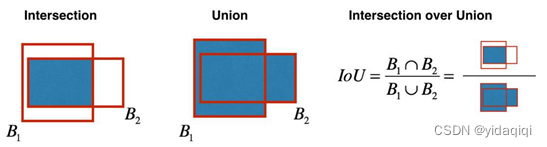
简单说,交集面积与并集面积之比,值越接近于1表示两个边界框的的重叠程度越高。
计算方法:
- 计算两个边界框的相交区域的面积。
- 计算两个边界框的并集区域的面积。
- 将相交区域的面积除以并集区域的面积,得到IoU值。
代码:
def calculate_iou(bbox1, bbox2):
# bbox: [x1, y1, x2, y2]
x1 = max(bbox1[0], bbox2[0])
y1 = max(bbox1[1], bbox2[1])
x2 = min(bbox1[2], bbox2[2])
y2 = min(bbox1[3], bbox2[3])
#上述是得出了交集的对角线的坐标
# 计算交集的面积
intersection_area = max(0, x2 - x1 + 1) * max(0, y2 - y1 + 1)
# 计算并集区域的面积
area_bbox1 = (bbox1[2] - bbox1[0] + 1) * (bbox1[3] - bbox1[1] + 1)
area_bbox2 = (bbox2[2] - bbox2[0] + 1) * (bbox2[3] - bbox2[1] + 1)
union_area = area_bbox1 + area_bbox2 - intersection_area
# 加一的目的是为了避免重合的时候的情况
# 计算IoU值
iou = intersection_area / union_area
return iou
bbox1 = [10, 20, 50, 60] # 左上角和右下角坐标
bbox2 = [30, 40, 70, 80]
iou = calculate_iou(bbox1, bbox2)
print("IoU:", iou)
三、TP、TN、FP、FN
T是True,F是False,P是positive,N是negative
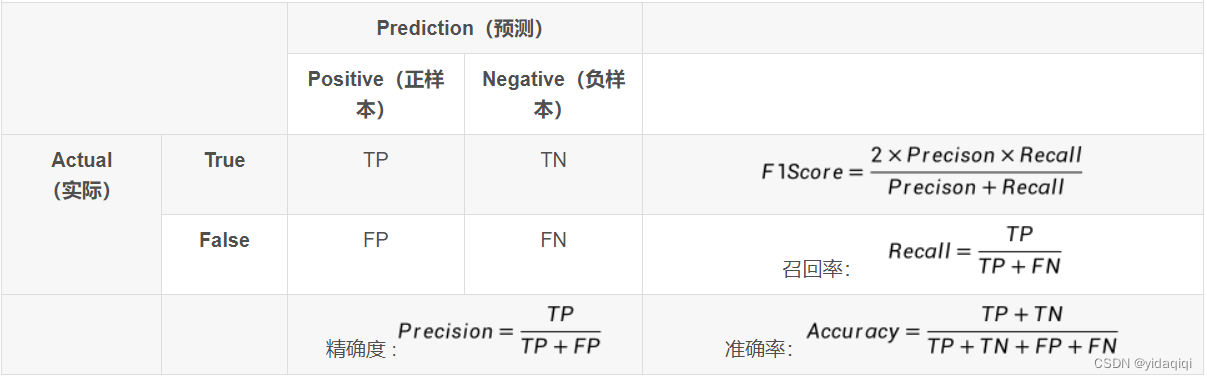
关于这四个词的概念,我就通俗易懂的讲一下:
假如, 原始图片中有10张人脸,输入到一个人脸检测模型,检测的结果是9张人脸,然后9张人脸的框,有8个和原图是相似对应的,有1个框里面啥也没有,没有人脸。那计算这个情况下的四个值。
TP:就是预测人脸然后预测正确了的,这个题就知道有8个。
FP:就是将一个不是标签的给预测出来,预测的结果是标签,这次 预测中,有一个是空气但是预测成人脸了,所以的值就为1了。
FN:就是模型判断错了,他是标签,但是没有预测出来,这个题的结果为2,因为有两个人脸没有预测出来。
TN:这个概念的意思就是说,就如有一张照片,这张照片没有人脸,然后模型也没有给出任何的结果,对于这种情况下,TN的值就是1.
对于上述表中,对内容进行详细地解释一下。
首先,感到的第一个疑惑的地方就是,是如何判断自己到底预测的是对的还是错的,也就是表中的正负样本的这些概念,个人理解是会去计算预测框和真实的框( GT)的IOU,然后和阈值进行比较,大于阈值的时候,然后看这个框内物体的类别有没有预测正确,如果预测正确就是正样本,这样理解起来应该通俗易懂了。然后还有四个指标的解释,下边分标题来讲解,并且给出代码。
四、准确率、召回率、F1-Score、
Precision
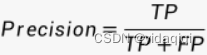
解释:预测正确的框除以预测框的数量。准确率越高越好。
Accuracy

解释:该指标和上边的那个有点类似,这个指标是用来评估模型预测的目标位置与实际目标位置的一个匹配程度的情况。也是越高越好就对了。
Recall
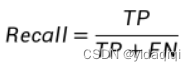
召回率,就是预测正确的标签数量除于标签的数量,举例就是,一共10张人脸,然后预测出来9张正确的,拿这张的准确率就是0.9。也叫做查全率,这个值的话越接近1越好。
F1-Score

这个参数引入也是很有必要的,因为要看一个模型好不好,不能单独只看上边两个参数。该参数认为上边的两个参数同等重要,很多多分类的机器学习竞赛,把这个作为最终测评的方法。它是准确率和召回率的调和平均数,最大为1,最小为0,该分数又叫做F1分数。
给出上述指标的代码,代码如下:
def calculate_precision_recall_f1(predicted_boxes, ground_truth_boxes, threshold=0.5):
true_positives = 0
false_positives = 0
false_negatives = 0
for pred_box, pred_class, pred_confidence in predicted_boxes:
best_iou = 0
for gt_box, gt_class in ground_truth_boxes:
iou = calculate_iou(pred_box, gt_box)
if iou > best_iou and pred_class == gt_class:
best_iou = iou
if best_iou >= threshold:
true_positives += 1
else:
false_positives += 1
for gt_box, gt_class in ground_truth_boxes:
best_iou = 0
for pred_box, pred_class, pred_confidence in predicted_boxes:
iou = calculate_iou(pred_box, gt_box)
if iou > best_iou and pred_class == gt_class:
best_iou = iou
if best_iou < threshold:
false_negatives += 1
precision = true_positives / max((true_positives + false_positives), 1)
recall = true_positives / max((true_positives + false_negatives), 1)
f1_score = 2 * (precision * recall) / max((precision + recall), 1)
return precision, recall, f1_score五、ROC曲线、PR曲线
ROC曲线
概念:ROC曲线是以 为横坐标,以
为横坐标,以 为纵坐标。其中TPR叫真阳率或灵敏度,就是召回率,指在实际为1的样本中预测为1的概率;FPR叫假阳率或特异度,是指实际为0的样本中预测为1的概率。概念能理解就理解,不是很容易懂。
为纵坐标。其中TPR叫真阳率或灵敏度,就是召回率,指在实际为1的样本中预测为1的概率;FPR叫假阳率或特异度,是指实际为0的样本中预测为1的概率。概念能理解就理解,不是很容易懂。
ROC曲线的走势如下图所示,曲线越往左上凸表明模型效果越好。ROC曲线和P-R曲线都是通过选择不同的阈值得到不同的点,从而画出曲线。

2、作用
ROC曲线上的每一个点都代表了分类器在不同的阈值下的表现。阈值是分类器用来决定什么样的预测结果是正例、什么样的是负例的一个参数。通常情况下,我们会选择一个合适的阈值来平衡分类器的性能。ROC曲线越靠近左上角,表示分类器的性能越好。
可以利用ROC曲线对不同模型进行比较,如果一个模型的ROC曲线被另一个模型的曲线完全包住,则可断言后者的性能由于前者。
ROC曲线下方的面积(AUC)可以用来作为评估模型模型性能的指标.如当两个模型的ROC曲线发生交叉,则很难说哪一个模型更好,这时候可以用AUC(ROC曲线下面区域的面积,参考)来作为一个比较合理的判据。
ROC曲线有个很好的特性,当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。
ROC曲线可以反映二分类器的总体分类性能,但是无法直接从图中识别出分类最好的阈值,事实上最好的阈值也是视具体的场景所定。ROC曲线一定在y=x之上,否则就是一个不好的分类器。
尽管ROC用处很大但是如果我们的数据中类别分布非常不均衡的时候,ROC就不再适用了。
P-R曲线(查准率-查全率曲线)
1、P-R图直观的显示出学习器在样本总体上的查全率、查准率,再进行比较时,若一个学习器的 P-R曲线被另外一个学习器的曲线完全“包住”,则可断言后者的性能优于前者。P-R曲线下面积的大小,在一定程度上表征了学习器在查准率和查全率上取得相对“双高”的比例。
2、在PR关系中,是一个此消彼长的关系,但往往我们希望二者都是越高越好,所以PR曲线是右上凸效果越好(也有例外,有比如在风险场景当预测为1实际为0时需要赔付时,大致会要求Recall接近100%,可以损失Precision)。所以除了特殊情况,通常情况都会使用Precision-recall曲线,来寻找分类器在Precision与Recall之间的权衡。AP就是Precision-recall 曲线下面的面积,通常来说一个越好的分类器,AP值越高。
3、当PR曲线越靠近右上方时,表明模型性能越好,与ROC曲线类似,在对不同模型进行比较时,若一个模型的PR曲线被另一个模型的PR曲线完全包住则说明后者的性能优于前者.如图中橘色线代表的模型要优于蓝色线代表的模型,若模型的PR曲线发生了交叉,则无法直接判断哪个模型更好.在周志华老师的机器学习上中提到了可以用平衡点.它是查准率=查全率时的取值,如图黑色线代表的模型的平衡点要大于橘色线模型代表的平衡点,表明前者优于后者,除此之外更为常用的是F1 score。
4、作用:
(1)PR曲线反映了分类器对正例的识别准确程度和对正例的覆盖能力之间的权衡。
(2)PR曲线有一个缺点就是会受到正负样本比例的影响。比如当负样本增加10倍后,在Racall不变的情况下,必然召回了更多的负样本,所以精度就会大幅下降,所以PR曲线对正负样本分布比较敏感。对于不同正负样本比例的测试集,PR曲线的变化就会非常大。
(3)当数据集类别分布非常不均衡的时候采用PR曲线。
六、AP、MAP(比较重要的)
AP:平均准确率,是对不同召回率点上的准确率进行平均,PR曲线图上表现为PR曲线下面的面积。AP的值越大,则说明模型的平均准确率越高。
MAP:
对所有类别的AP值求平均值。AP可以反映每个类别预测的准确率,mAP就是对所有类的AP求平均值,用于反映整个模型的准确率。
2、如果是多类别目标检测任务,就要使用mAP,mAP是多个类别AP的平均值。这个mean的意思是对每个类的AP再求平均,得到的就是mAP的值,mAP的大小一定在[0,1]区间,越大越好。该指标是目标检测算法中最重要的一个。
[email protected],这种形式表示在IOU阈值为0.5的情况下,mAP的值为多少。当预测框与标注框的IOU大于0.5时,就认为这个对象预测正确,在这个前提下再去计算AP的均值mAP。
4、mAP@[0.5:0.95]
还存在mAP@[0.5:0.95]这样一种表现形式,这形式是多个IOU阈值下的mAP,会在区间[0.5,0.95]内,以0.05为步长,取10个IOU阈值,分别计算这10个IOU阈值下的mAP,再取平均值。
大概总结了一下,可能有些说的也不太好,但是只能先这样了,有机会再补充一下给大家。写的有问题的,请大家评论。