lora微调
引入低秩矩阵
LoRA 微调整体原理
在传统的模型微调中,尤其是大型预训练模型,对所有参数进行更新需要巨大的计算资源和时间成本。而 LoRA 的思路是冻结预训练模型的原始权重,不直接对其进行更新,而是在模型的某些层(常见于 Transformer 模型的自注意力层和前馈网络层 )中引入低秩矩阵来实现微调。
低秩矩阵的引入及作用矩阵分解
假设原始模型中有一个权重矩阵W(维度为d×k ),在 LoRA 中,对权重矩阵的更新量Delta W进行分解,将其表示为两个低秩矩阵A(维度为d×r)和B(维度为r×k )的乘积,即Delta W = AB ,其中r << min(d,k)(r为低秩矩阵的秩,远小于原始矩阵维度)。比如在微调一个大型语言模型时,原本需要更新的权重矩阵维度可能非常大,通过这种分解,将更新操作转换到两个较小的低秩矩阵上。
减少参数量
原本更新权重矩阵W需要更新d×k个参数,而现在只需要更新A和B两个矩阵,参数总量变为r×(d + k) ,参数量大幅减少。举例来说,如果d = 1000 ,k = 1000 ,r = 10 ,原来要更新1000×1000 = 1000000个参数,现在只需更新10×(1000 + 1000)=20000个参数,大大降低了计算量。
捕捉关键特征
大语言模型的权重矩阵通常是满秩的,但在特定任务的微调中,对模型的调整(即权重更新量 )可能具有低秩特性。也就是说,通过低秩矩阵A和B,可以用少量参数捕捉与当前任务相关的核心特征,避免对整个模型的参数进行更新,从而在保留预训练模型知识的基础上,快速适应新的任务。
提升计算效率
在计算过程中,小矩阵乘法更容易利用 GPU 的并行计算能力,进一步提升计算效率。同时,在反向传播时,只需计算A和B的梯度,使得显存占用和计算量大幅降低。例如在微调 LLaMA - 7B 模型时,LoRA 可能仅需训练约 0.1% 的参数。
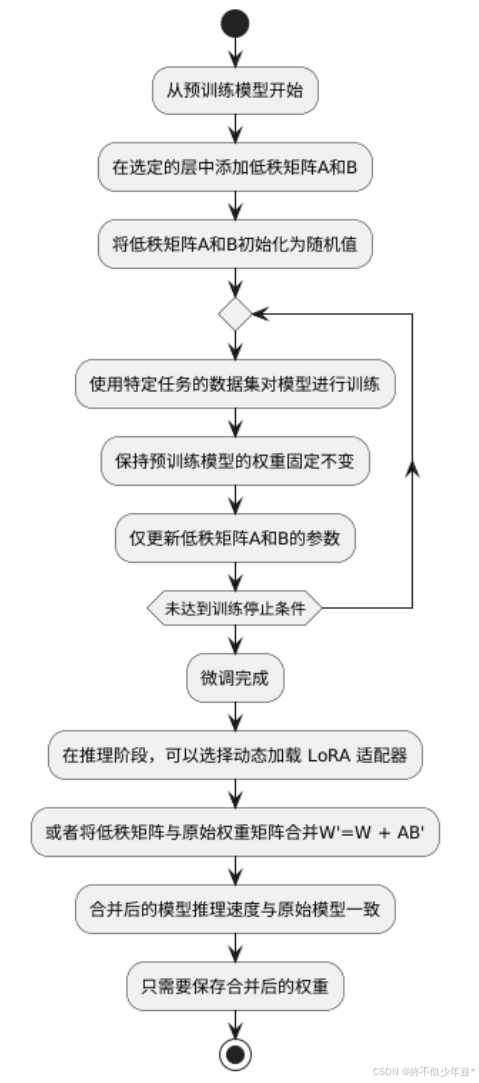
LoRA 微调的过程初始化
从预训练模型开始,在选定的层中添加低秩矩阵A和B,并将它们初始化为随机值。
微调
使用特定任务的数据集对模型进行训练,在这个过程中,保持预训练模型的权重固定不变,仅更新低秩矩阵A和B的参数。
预测
微调完成后,在推理阶段,可以选择动态加载 LoRA 适配器(即使用原始权重矩阵W加上更新后的Delta W = AB进行计算 ),或者将低秩矩阵与原始权重矩阵合并W'=W + AB',合并后的模型推理速度与原始模型一致,且只需要保存合并后的权重。
动态加载 LoRA 适配器和将低秩矩阵与原始权重矩阵合并两种做法的区别
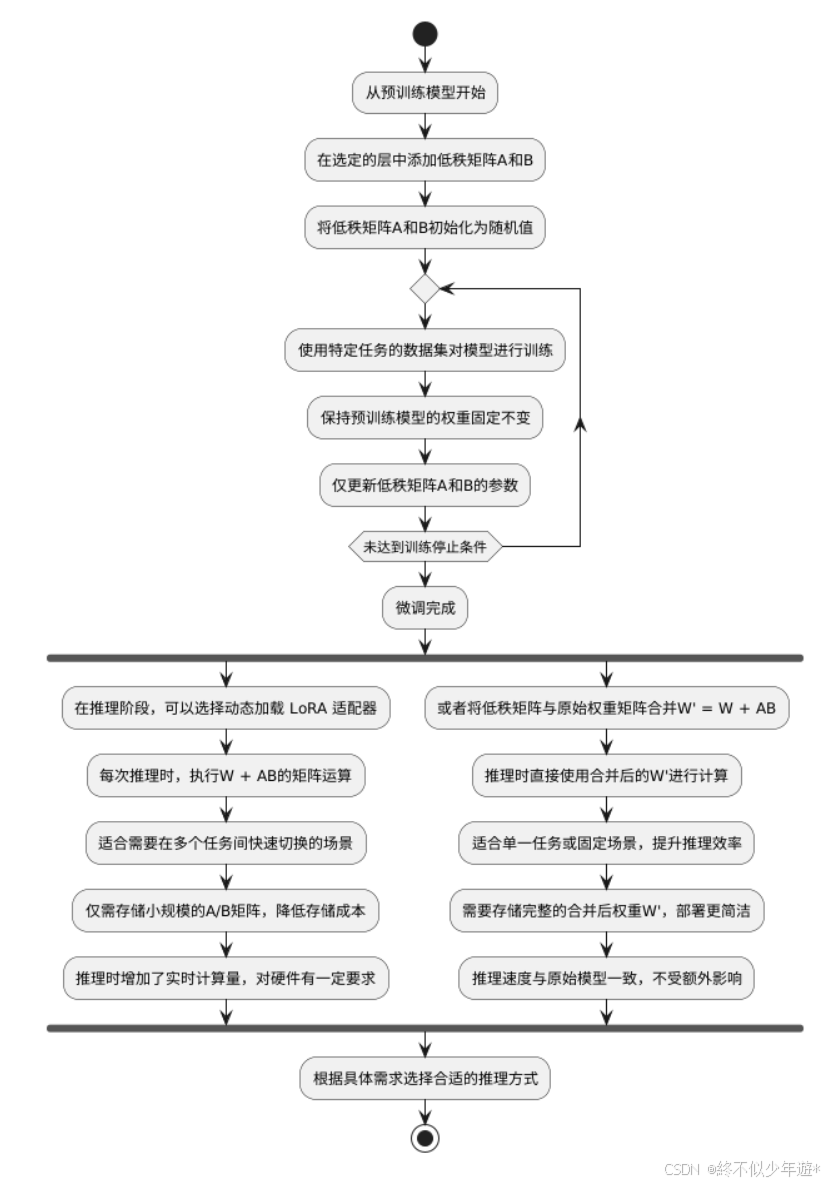
使用场景:灵活性 vs 专用性
动态加载 LoRA 适配器(W + AB计算)
灵活性高:适合需要在 多个任务间快速切换 的场景。例如,模型同时适配翻译、问答、文本生成等多个任务时,每个任务对应一套 A/B矩阵。推理时,根据当前任务动态加载对应的 A/B,与固定的预训练权重 W 组合计算,无需重复存储完整模型。
场景举例:开发一个多功能 AI 助手,用户输入不同类型的查询(如学术问题、生活建议、代码调试),系统动态加载对应任务的 LoRA 适配器,复用同一套预训练权重 W 完成推理。
合并权重(W' = W + AB)
专用性强:适用于 单一任务或固定场景。将 A/B与 W 合并后,模型成为针对特定任务的专用版本,推理时无需额外加载适配器,直接使用合并后的 W' 计算,更适合追求推理效率的落地场景(如固定业务的智能客服、特定领域的文档分析)。
存储方式:轻量化 vs 一体化
动态加载 LoRA 适配器
仅需存储小规模的 A/B矩阵,预训练权重 W 无需重复存储。例如,预训练模型权重可能达数 GB,而 A/B 矩阵可能仅几十 MB,大幅降低存储成本,适合资源受限的环境(如边缘设备)。
合并权重
需要存储完整的合并后权重 W',本质上是一个针对特定任务的独立模型。虽然存储量略高于动态加载模式(需保存 W'整体),但推理时无需依赖外部适配器文件,部署更简洁。
计算流程:实时计算 vs 直接推理
动态加载 LoRA 适配器
推理时,每次都要执行 W + AB 的矩阵运算,增加了实时计算量。例如,输入一批数据时,每一步推理都需临时计算 AB 并与 W 叠加,对硬件计算资源(如 GPU 算力)有一定要求。
合并权重
提前完成 W + AB 的合并,推理流程与原始预训练模型完全一致,直接使用 W' 进行计算。例如,原始模型推理一次耗时 T,合并后的模型推理耗时仍为 T,计算效率不受额外影响,适合对推理速度要求极高的场景。