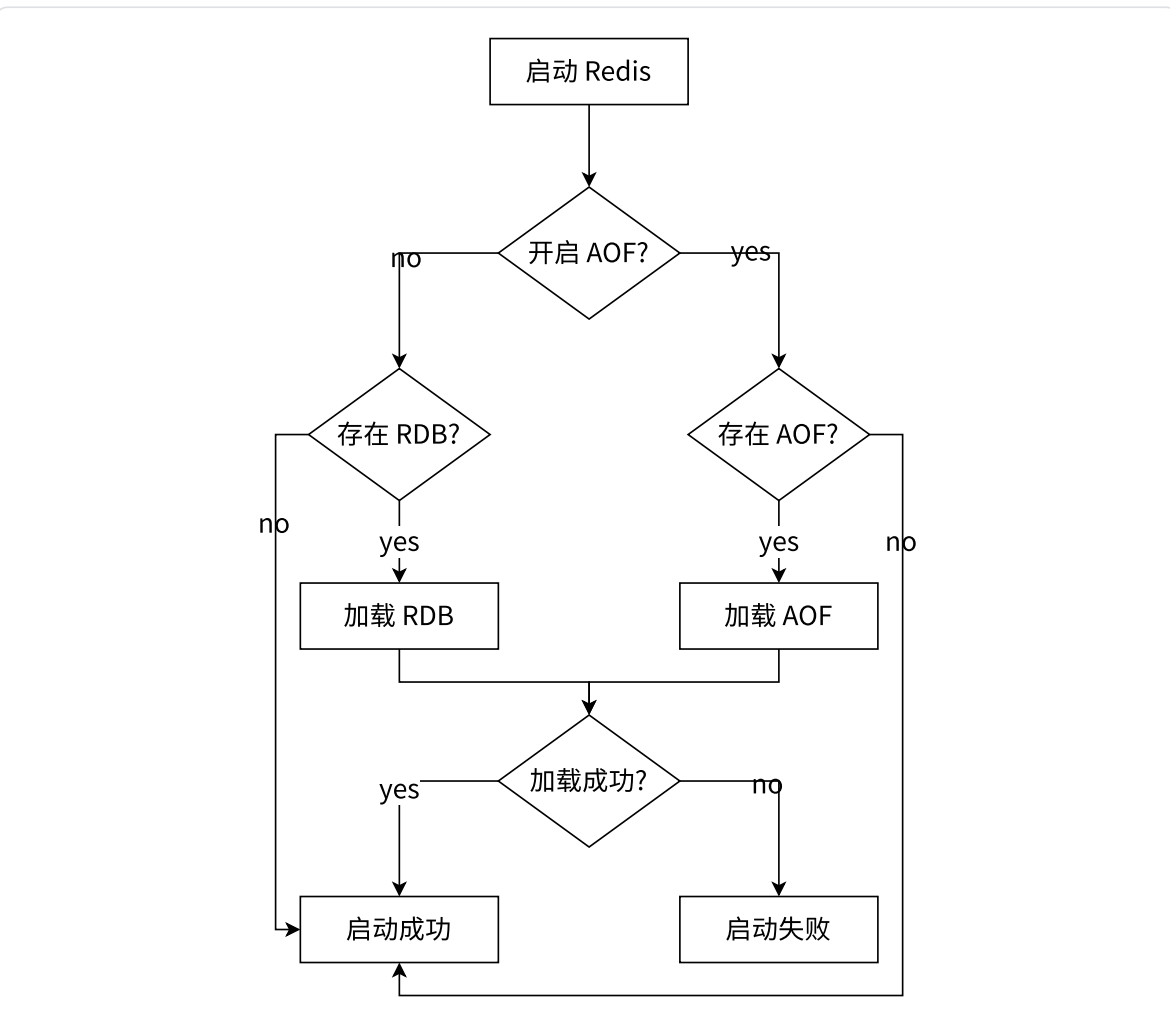
RDB 最大的问题,就是不能实时的持久化保存数据,在两次生成快照之间,实时的数据可能会随着重启而丢失
基本工作机制
AOF:append only file,类似于 MySQL 的 binlog,会把每个用户的每个操作,都记录到文件中。当 redis 重新启动的时候,就会读取 AOF 文件中的内容,用来恢复数据
- 当开启
AOF的时候,RDB就不生效了。(启动的时候就不再读取RDB)
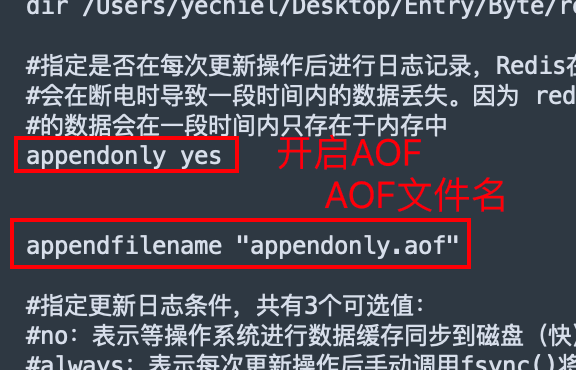
AOF文件和RDB文件的位置一样
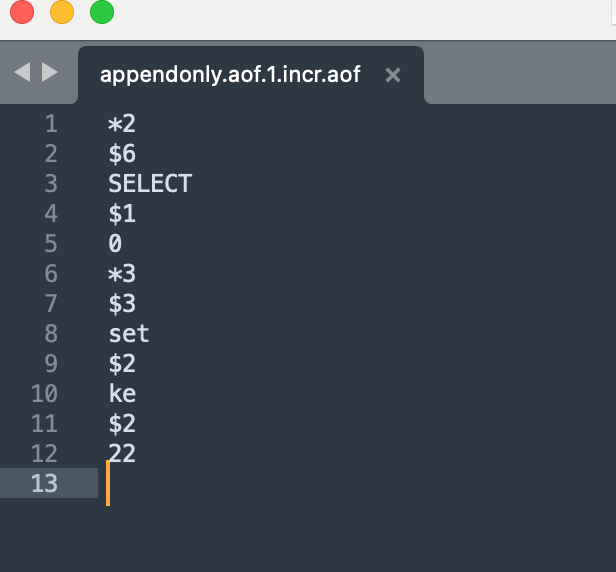
AOF是一个文本文件,每次进行的操作,都会被记录到文本文件中- 通过一些特殊的符号作为分隔符,来对命令的细节做出区分
- 可以看到,重启服务器之后,还有先前的数据

AOF 工作流程
Redis 虽然是一个单线程的服务器,但是速度很快。为什么速度快?重要原因是其只操作内存。引入 AOF 之后,又要写内存,又要写硬盘,现在还能和之前一样快吗?
顺序写入
实际上是没有影响到 Redis 处理请求的速度:
- 硬盘上读写数据,顺序读写的速度是比较快的(还是比内存要慢很多),随机访问则速度是比较慢的
AOF 是每次把新的操作写入到原有文件的末尾,属于顺序写入
内存缓冲区
AOF机制并非是直接让工作线程把数据写入硬盘,而是先写入一个内存中的缓冲区(大大降低了写硬盘的次数),积累一波之后,再统一写入硬盘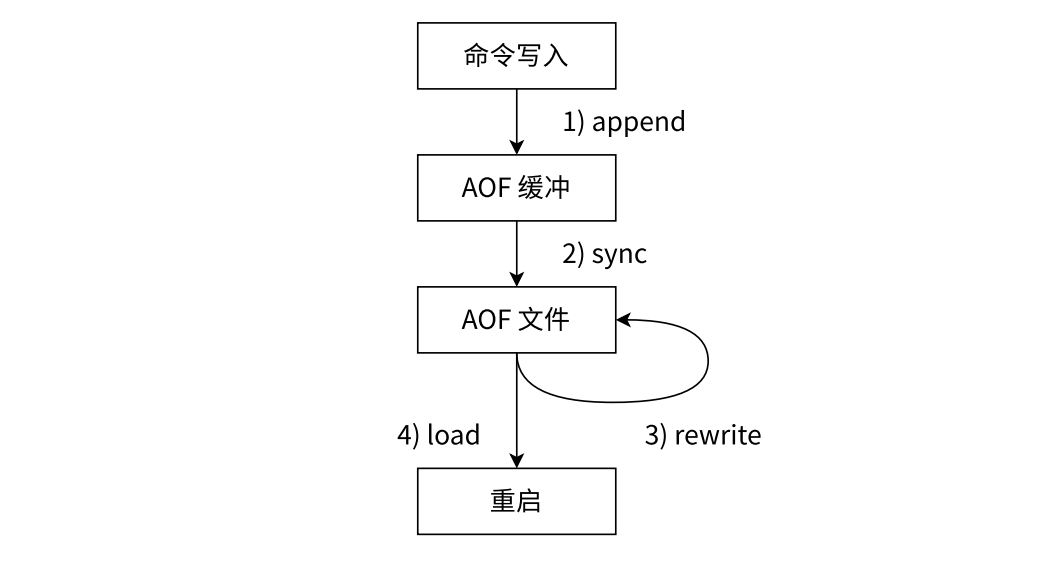
写硬盘的时候,写入硬盘数据的多少,对于性能影响没有很大,但是写入硬盘的次数则影响很大
文件同步
如果把数据写入到缓冲区里,本质还是在内存中呀,万一这个时候,突然进程挂了,或者主机掉电了,怎么办?是不是缓冲区中的数据就丢了?
- 对的,缓冲区中没来得及写入硬盘的数据是会丢的(又想… 又想…,是不行的,鱼和熊掌不可兼得)
Redis 给出了一些选项,让程序猿根据实际情况来决定怎么取舍——缓冲区的刷新策略
- 刷新频率越高,性能影响就越大,但数据可靠性就越高
- 刷新频率越低,性能影响就越小,但数据可靠性就越低
Redis 提供了多种 AOF 缓冲区同步⽂件策略,由参数 appendfsync 控制,不同值的含义如下图:
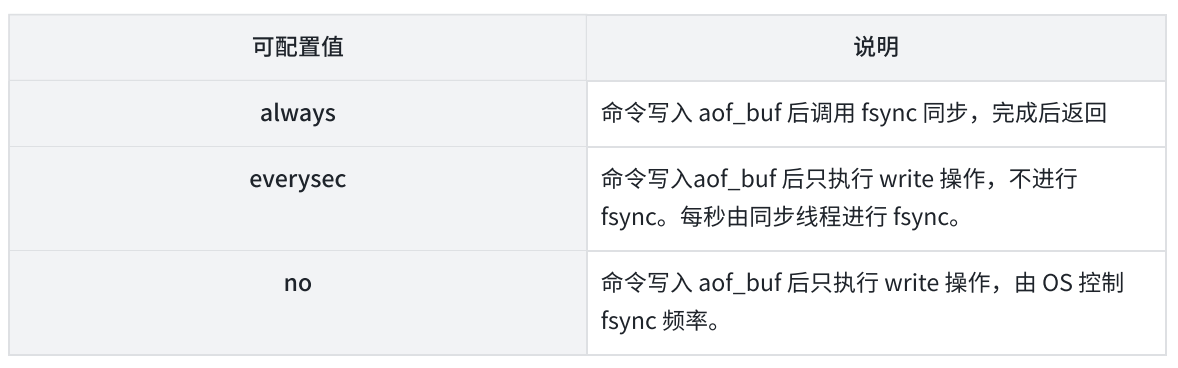
always:频率最高,数据可靠性最高,性能最低everysec:频率较低,数据可靠性也会降低,性能会提高。每秒刷新一次(极端掉电情况,也只会损失1s的数据)(默认策略)no:频率最低,数据可靠性也是最低,性能最高
重写机制
AOF 文件持续增长,体积越来越大,会影响到下次 Redis 启动的时间,Redis 启动的时候要读取 AOF 文件的内容
上述 AOF 中的文件,有一些是冗余的
- 有一个客户端,对
Redis进行操作lpush key 111lpush key 222lpush key 333- 这些操作其实就是一个操作:
lpush key 333 set key 111del keyset key 222del key- 这四个操作,什么都不做就可以了
Redis 启动时读取 AOF 内容的时候,AOF 记录了中间的过程,但 Redis 在重启的时候只关注最终结果。因此 Redis 就存在一个机制,能够针对 AOF 文件进行整理操作,这个整理就是能够剔除其中的冗余操作,并且合并一些操作,达到给 AOF 瘦身这样的效果——重写机制
比如,你每天给自己打分,买了个小本子记录
- 早起:+2 分
- 贪睡:-2 分
- 晨跑:+5 分
- 高效 1h:+2 分
- 浪费时间:-3 分
- …
记录满一页后,记录一个总分,然后翻到下一页,继续记录。哪怕前面的内容都没了也没事,只要你记得每一页的最终总分是多少就行了
触发时机
- 手动触发:调用
bgrewriteaof命令 - 自动触发:根据
auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定⾃动触发时机。auto-aof-rewrite-min-size:表⽰触发重写时AOF的最⼩⽂件⼤⼩,默认为64MB。auto-aof-rewrite-percentage:代表当前AOF占⽤⼤⼩相⽐较上次重写时增加的⽐例。
重写流程
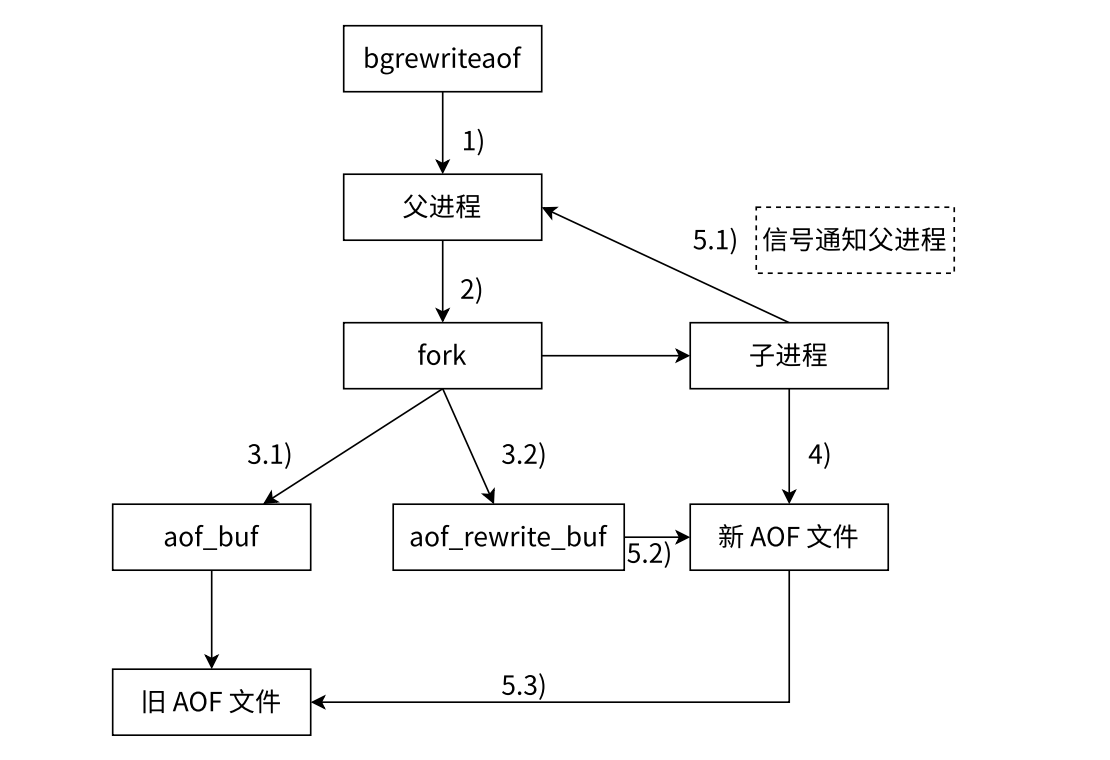
父进程通过 fork 创建子进程,父进程仍然负责接收请求,子进程负责针对 AOF 文件进行重写
-
注意!重写的时候,不关心
AOF文件中原来都有什么,只关心内存中最终的数据状态 -
子进程只需要把内存中当前的数据获取出来,以
AOF的格式写入到一个新的AOF文件中即可- 内存中的数据状态,已经相当于是把
AOF文件结果整理后的模样了 - 此处子进程写数据的过程,非常类似于
RDB生成一个镜像快照。只不过RDB这里是按照二进制的方式来生成的,AOF重写则是按照AOF这里要求的文本格式来生成的(和RDB都是为了把当前内存中的所有数据状态记录到文件中)
- 内存中的数据状态,已经相当于是把
-
子进程写新
AOF文件的同时,父进程仍然在不停的接收客户端的新的请求,父进程还是会把这些请求产生的AOF数据先写入到缓冲区,再刷新到原有的AOF文件里 -
在创建子进程的一瞬间,子进程就继承了当前父进程的内存状态。因此,子进程里的内存数据是父进程
fork之前的状态。fork之后新来的请求,对内存造成的修改,子进程是不知道的- 此时,父进程这里又准备了一个
aof_rewrite_buf缓冲区,专门放fork之后收到的数据 - 子进程这边,把
AOF数据写完之后,会通过信号通知一下父进程,父进程再把aof_rewrite_buf缓存区中的内容也写到新AOF文件里 - 最后就可以用新的
AOF文件代替旧的AOF文件了
- 此时,父进程这里又准备了一个
整个重写过程分为两个部分:
fork之前的数据,子进程直接写入新的AOF文件fork之后的数据,由父进程暂存到aof_rewrite_buf中,子进程完成新AOF文件写入之后在,再把aof_rewrite_buf写入到新AOF文件中去
相关问题
如果在执行 bgrewriteaof 的时候,当前 redis 已经正在进行 AOF 重写了,会怎么样呢?
- 此时,不会再次执行
AOF重写,直接返回
如果在执行 bgrewriteaof 的时候,发现当前 Redis 在生成 RDB 快照,会怎么样呢?
- 此时,
AOF重写操作就会等待,等待RDB快照生成完毕之后,再执行AOF重写
RDB 对于 fork 之后的新数据,就直接置之不理了。AOF 则对于 fork 之后的新数据,采取了 aof_rewriteaof_buf 缓冲区的方式来处理,为什么 RDB 不像 AOF 的机制来呢?
RDB本身的设计理论,就是用来“定期备份”,就很难和最新的数据保持一致- 而
AOF的理念是“实时备份” - 没有谁更好,主要看实际场景
父进程 fork 完毕之后,就已经让子进程写新的 AOF 文件了,并且随着时间的推移,子进程很快就写完了新的文件,要让新的 AOF 文件代替旧的。父进程此时还在继续写这个即将消亡的旧的 AOF 文件是否还有意义?
- 考虑极端情况
- 假设在重写过程中,重写了一般,服务器挂了,子进程内存的数据就会丢失,新的
AOF文件内容还不完整。所以如果父进程不坚持写旧AOF文件,重启就没法保证数据的完整性了
比如跳槽
小帅在 A 公司,干了一段时间之后,想跳槽去 B 公司。面试完了,offer 也发了,A 公司这里有一个交接时期
- 小帅在 A 公司的最后一段时间里,就不好好干活了。
- 眼看要到了入职的时间,B 公司吧 offer 给毁了,此时在 A 公司也待不下去了
混合持久化
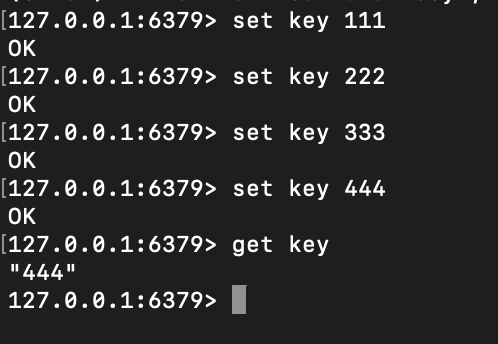
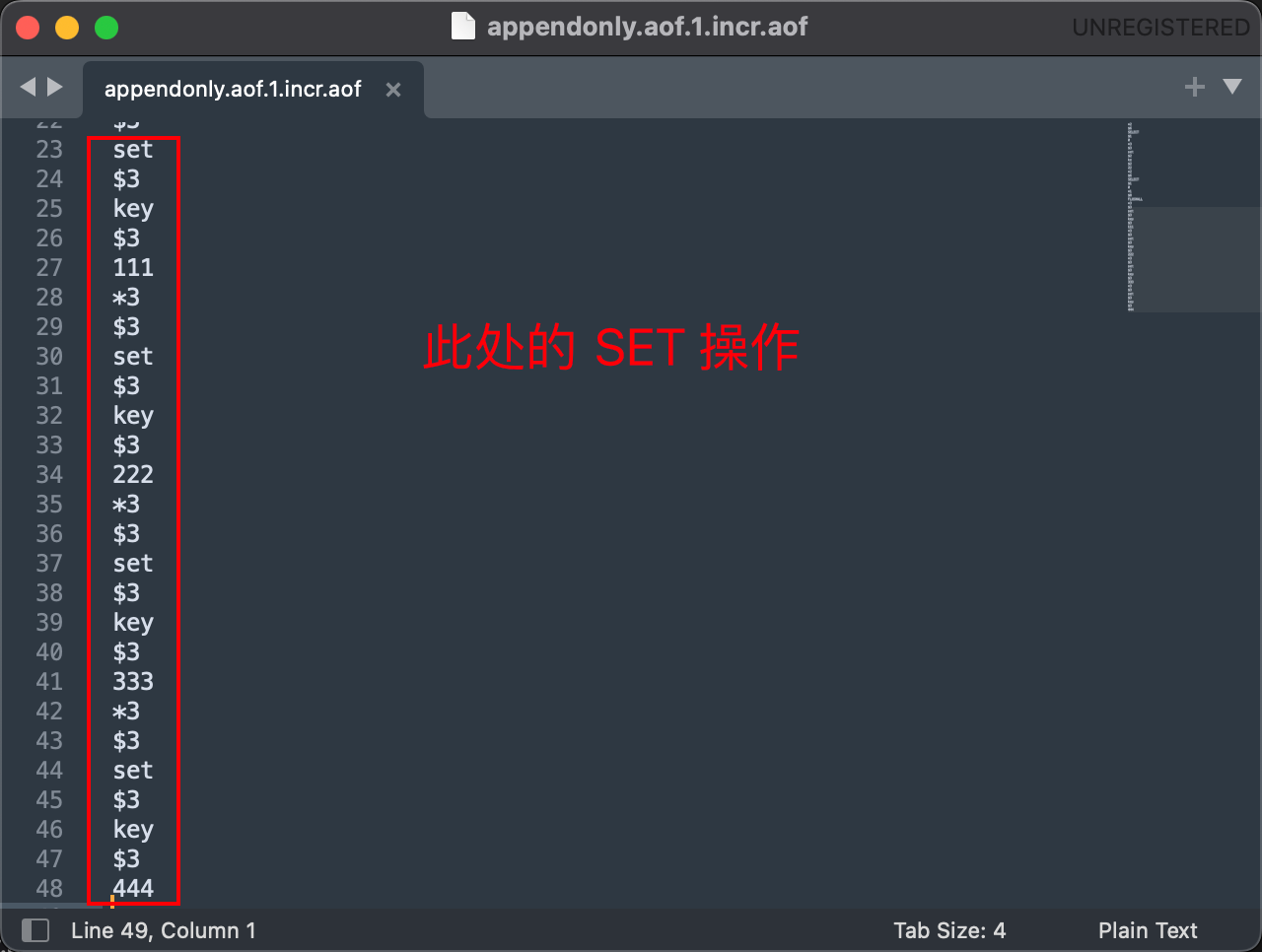
我们再使用 bgrewriteaof 命令手动触发重写
这是重写之前的文件内容,重写之后,AOF 文件被清空了,这个文件变成了:
AOF 本来是按照文本的方式来写入文件的,但是文本的方式写文件,后续加载的成本是比较高的。Redis 就引入了“混合持久化”的方式(结合了 AOF 和 RDB 的特点)
在 Redis 的混合持久化模式下,当执行 BGREWRITEAOF 命令时,Redis 会将当前数据库的状态进行快照,并将其保存为一个 RDB 文件(即 appendonly.aof.base.rdb)。同时,它会清理 AOF 文件,将新的数据增量写入到新的 AOF 文件(即 appendonly.aof.incr.aof)。
当 Redis 上同时存在 AOF 文件和 RDB 快照的时候,此时以谁为主?
- 以
AOF为主,RDB就直接被忽略了 AOF里面包含的数据比RDB更全