目录
1.Pytorch--安装
配置环境经常是让各位同学头痛不已又不得不经历的过程,那么本小节就给大家提供一篇手把手安装PyTorch的教程。
首先,进入pytorch官网,点上方get started进入下载
根据你的操作系统选择对应的版本,安装方式,CUDA版本等等。

这里作者的设备是window10,python3.8的运行环境,由于设备是AMD显卡不支持CUDA因此选择了CPU版本,后面关于CUDA是什么、有什么用我们会单独出一期教程讲解。
如果已经下载了anaconda 可以使用conda安装,没有下载就使用Pip安装,然后打开cmd将生成的命令语句复制到cmd上。
这里直接用 pip install 下载会比较慢,这边我们可以将源换掉,个人比较推荐阿里源和清华源
1pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/假如喜欢其他源的也可以换成其他源,将指令的网址换一下就好了
阿里云 Simple Index
中国科技大学 Verifying - USTC Mirrors
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 Simple Index
中国科学技术大学 Verifying - USTC Mirrors
这里用了 -i 临时换源的方法,只对这次安装有效,如果你想一劳永逸的话请使用上面提到的换源方法。
![]()
出现这样的字段说明安装成功了
测试一下:
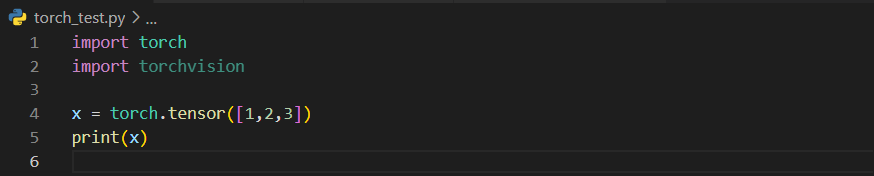
没有报错可以正常输出。
当时我们上面的操作是直接安装到真实环境中,我们更推荐你使用anaconda创建一个独立的环境
虚拟环境的创建,使用命令行:
1conda create -n pytorch(虚拟环境名) python=3.6激活环境:
1activate pytorch也可以使用pycharm创建:
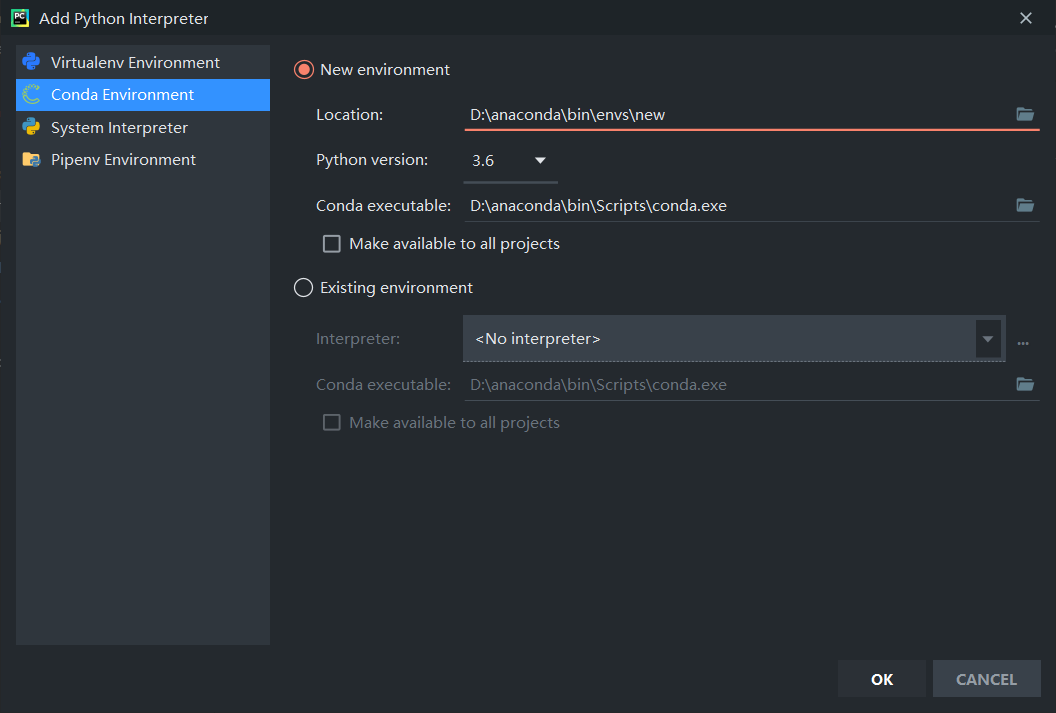
在这里选择环境名称和python版本。虽然虚拟环境很方便,但是对于有多个版本python的用户来说安装包的时候一定要在相应的python版本下的script的目录下进行pip,尽量使用pycharm安装,除非找不到或者安装很慢。因为一不小心容易把环境搞崩。
使用对应命令完成安装


2.Pytorch--张量
无论是 Tensorflow 还是我们接下来要介绍的 PyTorch 都是以**张量(tensor)**为基本单位进行计算的学习框架,第一次听说张量这个词的同学可能都或多或少困惑这究竟是个什么东西,那么在正式开始学习 PyTorch 之前我们还是花些时间简单介绍一下张量的概念。
学过线性代数的童鞋都知道,矩阵可以进行各种运算,比如:
- 矩阵的加法:

- 矩阵的转置:
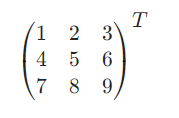
- 矩阵的点乘:

为了方便存储矩阵及进行矩阵之间的运算,大神们抽象出了 PyTorch 库,PyTorch 库中有一个类叫torch.Tensor,这个类存储了一个矩阵变量,并且有一系列方法用于对这个矩阵进行各种运算。上面的这些矩阵运算都可以通过 torch.Tensor 类的相应方法实现。
比如上面的矩阵加法:
import torch # 引入torch类
x = torch.rand(5, 3) # 生成一个5*3的矩阵x,矩阵的每个元素都是0到1之间的随机数,x的类型就是torch.Tensor,x里面存了一个5*3的矩阵
y = torch.zeros(5, 3, dtype=torch.float) # 生成一个5*3的矩阵y,矩阵的每个元素都是0,每个元素的类型是long型,y的类型就是torch.Tensor,y里面存了一个5*3的矩阵
y.add_(x) # 使用y的add_方法对y和x进行运算,运算结果保存到y上面的x、y的类型都是 torch.Tensor,Tensor 这个单词一般可译作“张量”。但是上面我们进行的都是矩阵运算,为什么要给这个类型起名字叫张量呢,直接叫矩阵不就行了吗?张量又是什么意思呢?
这是因为:通常我们不但要对矩阵进行运算,我们还会对数组进行运算(当然数组也是特殊的矩阵),比如两个数组的加法:
但是在机器学习中我们更多的是会对下面这种形状进行运算:
大家可以把这种数看作几个矩阵叠在一起,这种我们暂且给它取一个名字叫“空间矩阵”或者“三维矩阵”。 因此用**“矩阵”不能表达所有我们想要进行运算的变量**,所以,我们使用张量把矩阵的概念进行扩展。这样普通的矩阵就是二维张量,数组就是一维张量,上面这种空间矩阵就是三维张量,类似的,还有四维、五维、六维张量

那么上面这种三维张量怎么表达呢?
一维张量[1,2,3],:
torch.tensor([1,2,3]) 二维张量: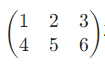 :
:
torch.tensor([[1,2,3],[4,5,6]])聪明的同学可能发现了,多一个维度,我们就多加一个 []。
所以为什么叫张量而不是矩阵呢?就是因为我们通常需要处理的数据有零维的(单纯的一个数字)、一维的(数组)、二维的(矩阵)、三维的(空间矩阵)、还有很多维的。PyTorch 为了把这些各种维统一起来,所以起名叫张量。
张量可以看作是一个多维数组。标量可以看作是0维张量,向量可以看作1维张量,矩阵可以看作是二维张量。比如我们之前学过的 NumPy,你会发现 tensor 和 NumPy 的多维数组非常类似。
创建 tensor:
x = torch.empty(5, 3)
x = torch.rand(5, 3)
x = torch.zeros(5, 3, dtype=torch.long)
x = torch.tensor([5.5, 3])
x = x.new_ones(5, 3, dtype=torch.float64)
y = torch.randn_like(x, dtype=torch.float)获取 tensor 的形状:
print(x.size())
print(x.shape)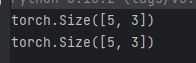
tensor 的各种操作:
y = torch.rand(5, 3)
print(x + y) # 加法形式一
print(torch.add(x, y)) # 加法形式二
# adds x to y
y.add_(x) # 加法形式三
print(y)PyTorch 中的 tensor 支持超过一百种操作,包括转置、索引、切片、数学运算、线性代数、随机数等等,总之,凡是你能想到的操作,在 PyTorch 里都有对应的方法去完成。
3.Pytorch--定义
PyTorch 是一个基于 python 的科学计算包,主要针对两类人群:
- 作为 NumPy 的替代品,可以利用 GPU 的性能进行计算
- 作为一个高灵活性,速度快的深度学习平台
张量 Tensors
Tensor(张量),类似于 NumPy 的 ndarray ,但不同的是 Numpy 不能利用GPU加速数值计算,对于现代的深层神经网络,GPU通常提供更高的加速,而 Numpy 不足以进行现代深层学习。
而 Tensor 可以利用gpu加速数值计算,要在gpu上运行pytorch张量,在构造张量时使用device参数将张量放置在gpu上。
4.Pytorch--运算
4.1.Tensor数据类型
Tensor张量是Pytorch里最基本的数据结构。直观上来讲,它是一个多维矩阵,支持GPU加速,其基本数据类型如下
| 数据类型 | CPU Tensor | GPU Tensor |
|---|---|---|
| 8位无符号整型 | torch.ByteTensor |
torch.cuda.ByteTensor |
| 8位有符号整型 | torch.CharTensor |
torch.cuda.CharTensor |
| 16位有符号整型 | torch.ShortTensor |
torch.cuda.ShortTensor |
| 32位有符号整型 | torch.IntTensor |
torch.cuda.IntTensor |
| 64位有符号整型 | torch.LongTensor |
torch.cuda.LongTensor |
| 32位浮点型 | torch.FloatTensor |
torch.cuda.FloatTensor |
| 64位浮点型 | torch.DoubleTensor |
torch.cuda.DoubleTensor |
| 布尔类型 | torch.BoolTensor |
torch.cuda.BoolTensor |
4.2.Tensor创建
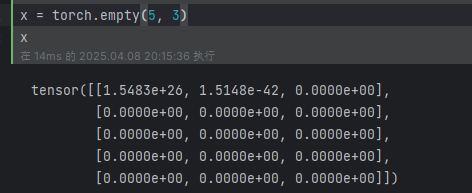
torch.empty():创建一个没有初始化的 5 * 3 矩阵:
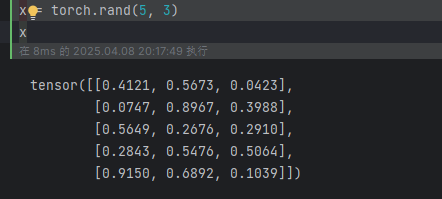
torch.rand(5, 3):创建一个随机初始化矩阵:
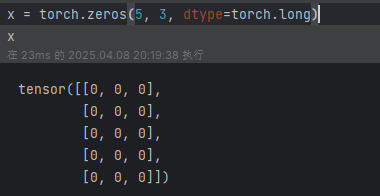
torch.zeros(5, 3, dtype=torch.long):构造一个填满 0 且数据类型为 long 的矩阵:
4.3.Tensor运算
| 函数 | 作用 | 注意事项 |
|---|---|---|
torch.abs(A) |
计算张量 A 的绝对值 |
输入输出张量形状相同。 |
torch.add(A, B) |
张量相加(A + B),支持标量或张量 |
支持广播机制(如 A.shape=(3,1), B.shape=(1,3))。 |
torch.clamp(A, min, max) |
裁剪 A 的值到 [min, max] 范围内 |
常用于梯度裁剪(如 grad.clamp(min=-0.1, max=0.1))。 |
torch.div(A, B) |
相除(A / B),支持标量或张量 |
整数除法需用 // 或 torch.floor_divide。 |
torch.mul(A, B) |
逐元素乘法(A * B),支持标量或张量 |
与 torch.mm(矩阵乘)区分。 |
torch.pow(A, n) |
计算 A 的 n 次幂 |
n 可为标量或同形状张量。 |
torch.mm(A, B) |
矩阵乘法(A @ B),要求 A.shape=(m,n), B.shape=(n,p) |
不广播,需手动转置(如 B.T)。 |
torch.mv(A, B) |
矩阵与向量乘(A @ B),A.shape=(m,n), B.shape=(n,) |
无需转置 B,结果形状为 (m,)。 |
A.item() |
将单元素张量转为 Python 标量(如 int/float) |
仅限单元素张量(如 loss.item())。 |
A.numpy() |
将张量转为 NumPy 数组 | 需在 CPU 上(A.cpu().numpy())。 |
A.size() / A.shape |
查看张量形状(同义) | 返回 torch.Size 对象(类似元组)。 |
A.view(*shape) |
重构张量形状(不复制数据) | 总元素数需一致(如 A.view(-1, 2))。 |
A.transpose(0, 1) |
交换维度(如矩阵转置) | 高维张量可用 permute(如 A.permute(2,0,1))。 |
A[1:] |
切片操作(同 NumPy) | 支持高级索引(如 A[A > 0])。 |
A[-1, -1] = 100 |
修改指定位置的值 | 避免连续赋值(可能触发复制)。 |
A.zero_() |
将张量所有元素置零(原地操作) | 带下划线的函数(如 add_())表示原地修改。 |
torch.stack((A,B), dim=-1) |
沿新维度拼接张量(升维) | A 和 B 形状需相同(如 stack([A,B], dim=0) 结果形状 (2,...))。 |
torch.diag(A) |
提取对角线元素(输入矩阵→输出向量) | 若 A 为向量,则输出对角矩阵。 |
torch.diag_embed(A) |
将向量嵌入对角线生成矩阵(非对角线置零) | 输入向量形状 (n,),输出矩阵形状 (n, n)。 |
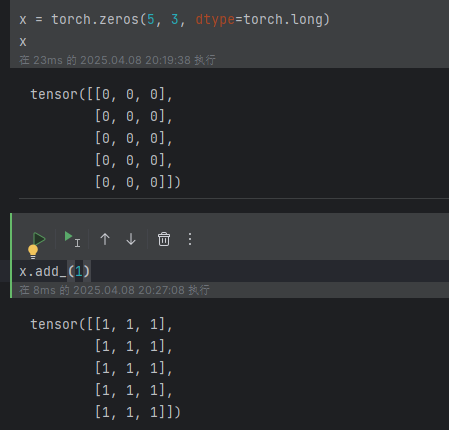
⭐ ⭐ ⭐ :所有的带_符号的函数都会对原数据进行修改,可以叫做原地操作
例如:X.add_()
事实上 PyTorch 中对于张量的计算、操作和 Numpy 是高度类似的。
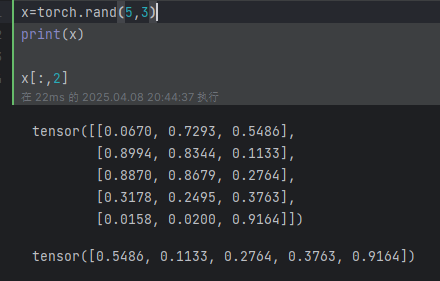
例如:通过索引访问数据:(第二列)
对 Tensor 的尺寸修改,可以采用 torch.view() ,如下所示:
x = torch.randn(4, 4)
y = x.view(16)
# -1 表示给定列维度8之后,用16/8=2计算的另一维度数
z = x.view(-1, 8)
print("x = ",x)
print("y = ",y)
print("z = ",z)
print(x.size(), y.size(), z.size())
x = tensor([[-0.3114, 0.2321, 0.1309, -0.1945],
[ 0.6532, -0.8361, -2.0412, 1.3622],
[ 0.7440, -0.2242, 0.6189, -1.0640],
[-0.1256, 0.6199, -1.5032, -1.0438]])
y = tensor([-0.3114, 0.2321, 0.1309, -0.1945, 0.6532, -0.8361, -2.0412, 1.3622,
0.7440, -0.2242, 0.6189, -1.0640, -0.1256, 0.6199, -1.5032, -1.0438])
z = tensor([[-0.3114, 0.2321, 0.1309, -0.1945, 0.6532, -0.8361, -2.0412, 1.3622],
[ 0.7440, -0.2242, 0.6189, -1.0640, -0.1256, 0.6199, -1.5032, -1.0438]])
torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
如果 tensor 仅有一个元素,可以采用 .item() 来获取类似 Python 中整数类型的数值:
x = torch.randn(1)
print(x)
print(x.item())tensor([-0.7328])
-0.7328450083732605
4.4.Tensor--Numpy转换
Tensor-->Numpy:
a = torch.ones(5)
print(a)
b = a.numpy()
print(b)

两者是共享同个内存空间的,例子如下所示,修改 tensor 变量 a,看看从 a 转换得到的 Numpy 数组变量 b 是否发生变化。
a.add_(1)
print(a)
print(b)
![]()
Numpy-->Tensor:
转换的操作是调用 torch.from_numpy(numpy_array) 方法。例子如下所示:
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a)
np.add(a, 1, out=a)
print(a)
print(b)

4.5.Tensor--CUDA(GPU)
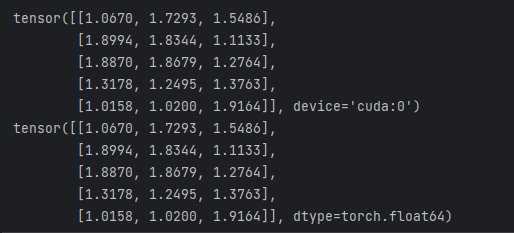
Tensors 可以通过 .to 方法转换到不同的设备上,即 CPU 或者 GPU 上。例子如下所示:
# 当 CUDA 可用的时候,可用运行下方这段代码,采用 torch.device() 方法来改变 tensors 是否在 GPU 上进行计算操作
if torch.cuda.is_available():
device = torch.device("cuda") # 定义一个 CUDA 设备对象
y = torch.ones_like(x, device=device) # 显示创建在 GPU 上的一个 tensor
x = x.to(device) # 也可以采用 .to("cuda")
z = x + y
print(z)
print(z.to("cpu", torch.double)) # .to() 方法也可以改变数值类型
5.Pytorch--自动微分 (autograd)
对于 Pytorch 的神经网络来说,非常关键的一个库就是 autograd ,它主要是提供了对 Tensors 上所有运算操作的自动微分功能,也就是计算梯度的功能。它属于 define-by-run 类型框架,即反向传播操作的定义是根据代码的运行方式,因此每次迭代都可以是不同的。
| 概念/方法 | 作用 | 典型应用场景 |
|---|---|---|
requires_grad=True |
启用张量的梯度追踪,记录所有操作历史 | 训练参数(如模型权重 nn.Parameter) |
.backward() |
自动计算梯度,结果存储在 .grad 属性中 |
损失函数反向传播 |
.grad |
存储梯度值的属性(与张量同形状) | 查看或手动更新梯度(如优化器步骤) |
.detach() |
返回一个新张量,从计算图中分离(requires_grad=False) |
冻结部分网络或避免梯度计算(如特征提取) |
torch.no_grad() |
上下文管理器,禁用梯度计算和追踪 | 模型评估、推理阶段 |
Function 类 |
定义自动微分规则,每个操作对应一个 Function 节点 |
自定义反向传播逻辑(继承 torch.autograd.Function) |
.grad_fn |
指向创建该张量的 Function 节点(用户创建的张量为 None) |
调试计算图结构 |
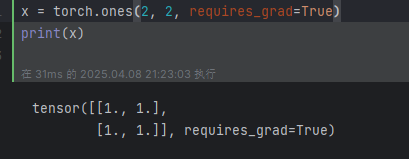
开始创建一个 tensor, 并让 requires_grad=True 来追踪该变量相关的计算操作:
5.1.backward求导
5.1.1.标量Tensor求导
import numpy as np
import torch
# 标量Tensor求导
# 求 f(x) = a*x**2 + b*x + c 的导数
x = torch.tensor(-2.0, requires_grad=True)#定义x是自变量,requires_grad=True表示需要求导
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
y = a*torch.pow(x,2)+b*x+c
y.backward() # backward求得的梯度会存储在自变量x的grad属性中
dy_dx =x.grad
dy_dx
![]()
5.1.2.非标量Tensor求导
# 非标量Tensor求导
# 求 f(x) = a*x**2 + b*x + c 的导数
x = torch.tensor([[-2.0,-1.0],[0.0,1.0]], requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
gradient=torch.tensor([[1.0,1.0],[1.0,1.0]])
y = a*torch.pow(x,2)+b*x+c
y.backward(gradient=gradient)
dy_dx =x.grad
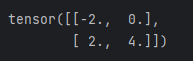
dy_dx
# 使用标量求导方式解决非标量求导
# 求 f(x) = a*x**2 + b*x + c 的导数
x = torch.tensor([[-2.0,-1.0],[0.0,1.0]], requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
gradient=torch.tensor([[1.0,1.0],[1.0,1.0]])
y = a*torch.pow(x,2)+b*x+c
z=torch.sum(y*gradient)
z.backward()
dy_dx=x.grad
dy_dx
5.2.autograd.grad求导
import torch
#单个自变量求导
# 求 f(x) = a*x**4 + b*x + c 的导数
x = torch.tensor(1.0, requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(2.0)
c = torch.tensor(3.0)
y = a * torch.pow(x, 4) + b * x + c
#create_graph设置为True,允许创建更高阶级的导数
#求一阶导
dy_dx = torch.autograd.grad(y, x, create_graph=True)[0]
#求二阶导
dy2_dx2 = torch.autograd.grad(dy_dx, x, create_graph=True)[0]
#求三阶导
dy3_dx3 = torch.autograd.grad(dy2_dx2, x)[0]
print(dy_dx.data, dy2_dx2.data, dy3_dx3)
# 多个自变量求偏导
x1 = torch.tensor(1.0, requires_grad=True)
x2 = torch.tensor(2.0, requires_grad=True)
y1 = x1 * x2
y2 = x1 + x2
#只有一个因变量,正常求偏导
dy1_dx1, dy1_dx2 = torch.autograd.grad(outputs=y1, inputs=[x1, x2], retain_graph=True)
print(dy1_dx1, dy1_dx2)
# 若有多个因变量,则对于每个因变量,会将求偏导的结果加起来
dy1_dx, dy2_dx = torch.autograd.grad(outputs=[y1, y2], inputs=[x1, x2])
dy1_dx, dy2_dx
print(dy1_dx, dy2_dx)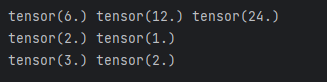
5.3.求最小值
#例2-1-3 利用自动微分和优化器求最小值
import numpy as np
import torch
# f(x) = a*x**2 + b*x + c的最小值
x = torch.tensor(0.0, requires_grad=True) # x需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
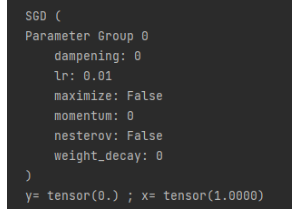
optimizer = torch.optim.SGD(params=[x], lr=0.01) #SGD为随机梯度下降
print(optimizer)
def f(x):
result = a * torch.pow(x, 2) + b * x + c
return (result)
for i in range(500):
optimizer.zero_grad() #将模型的参数初始化为0
y = f(x)
y.backward() #反向传播计算梯度
optimizer.step() #更新所有的参数
print("y=", y.data, ";", "x=", x.data)