LLM入门课#03-指令微调和模型评估
提示词工程可以在不使用额外训练的基础上优化模型,之后可以使用lora、PEFT等模型来完成微调。
动机:使用提示词来完成模型的推理将会让你的案例占用大量的提示词的空间,这样对于推理是不优化的,或者对于用户而言是不友好的,但是如果可以直接通过微调的方式从模型端增强模型的性能,将不会占用大量宝贵的提示词的空间。

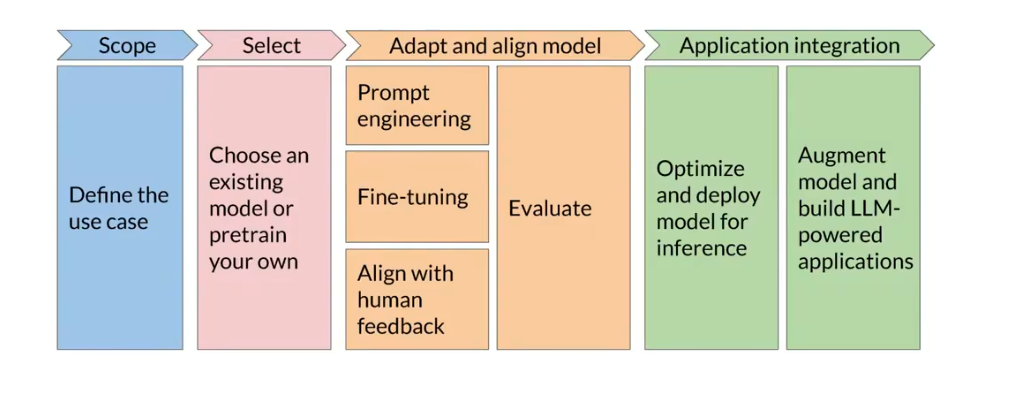
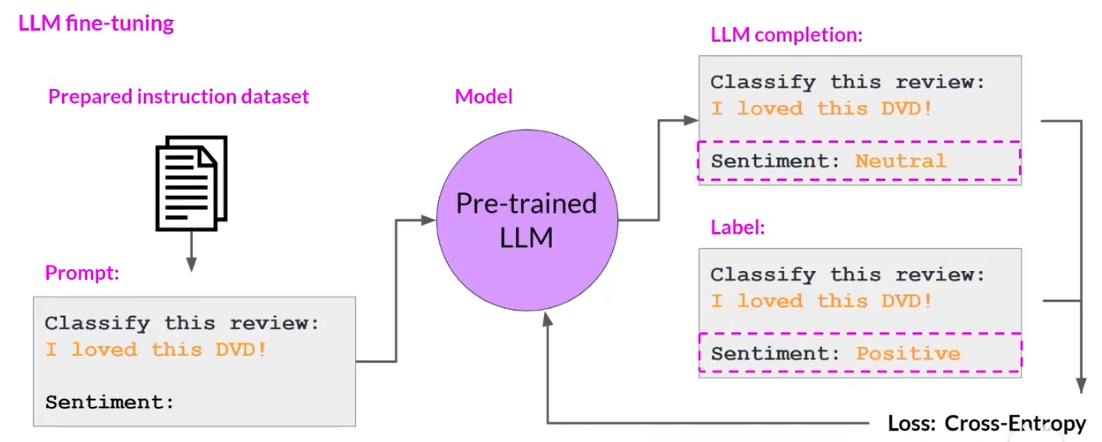
通过指令微调的方式来完成模型的微调,微调的形式是提供一个提示词,然后给定输入和输出的内容,如下所示。

如果让模型全部的权重参数来进行训练,需要对耗费很大的资源。
准备数据
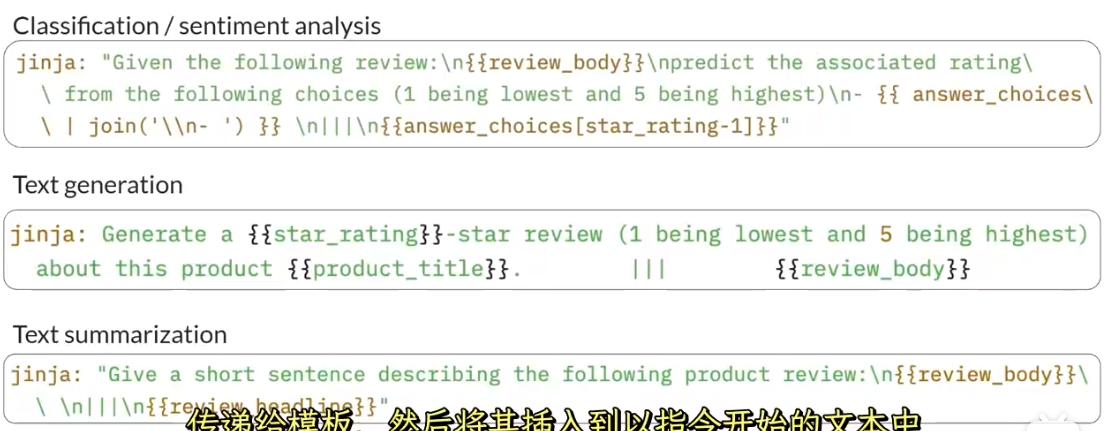
可以自己建立数据集或者是通过开发人员提供的数据集,比如amazon的大型产品评论数据集,使用类似的模版数据库可以帮助模型完成微调。在下面所示的案例中,其中review_body表示的就是原始的输入,后面的则是不同任务下的输出,包括分类任务、文本生成任务、以及文本总结的任务。
划分数据集进行训练
微调带来的问题-灾难性遗忘
通过微调可以在单一的微调的任务上带了不错的性能提升,但是由于使用了全面微调的方式,模型的权重参数发生了变化,所以导致模型在单一的任务上可以表现了优秀的性能,但是会降低模型在其他任务删的性能,少量微调。第一种是微调的过程中添加有其他的任务,好比练习投篮的时候你也得记得没事运球一下。另外一种是保持网路的主干不变,只是为其他的用于下游任务的参数上进行调试。

多任务指令微调
在训练的时候加入多个任务的数据来完成微调,缺点是需要的数据量比较大。
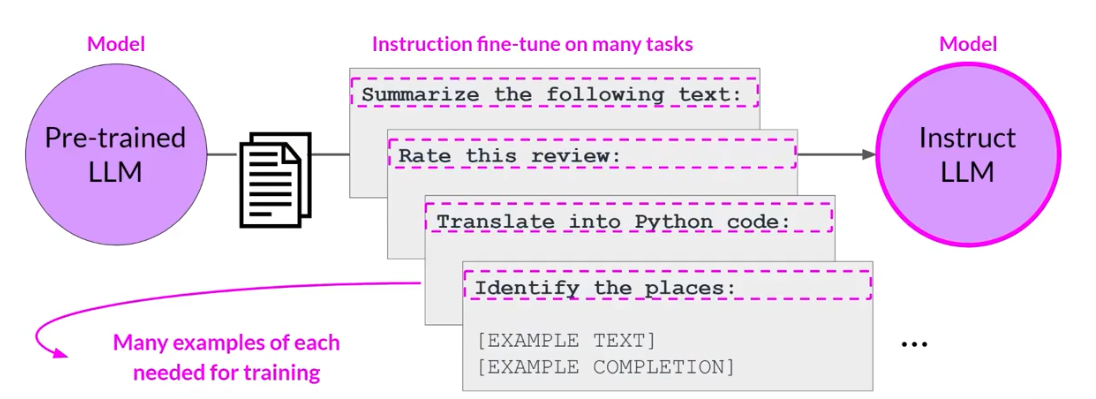
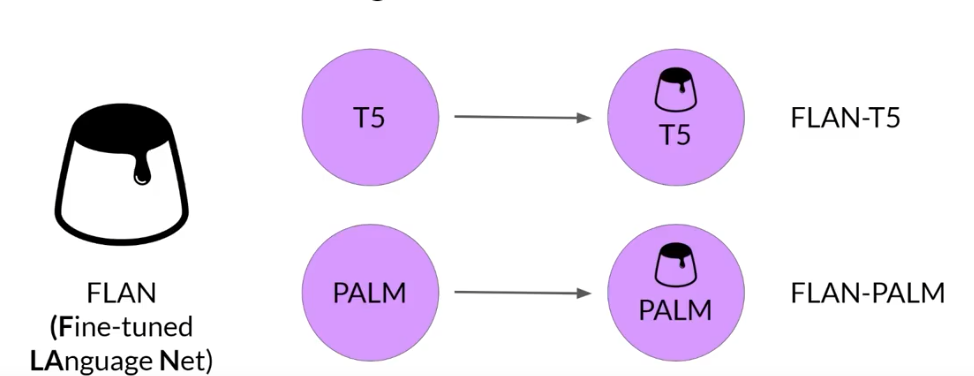
FLAN是一个指令微调的模型
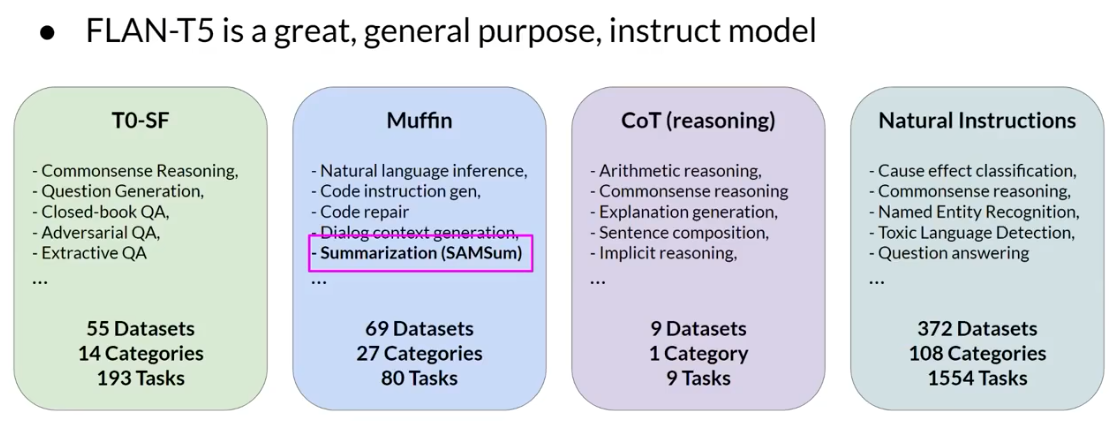
这里是模型所使用到的数据集。
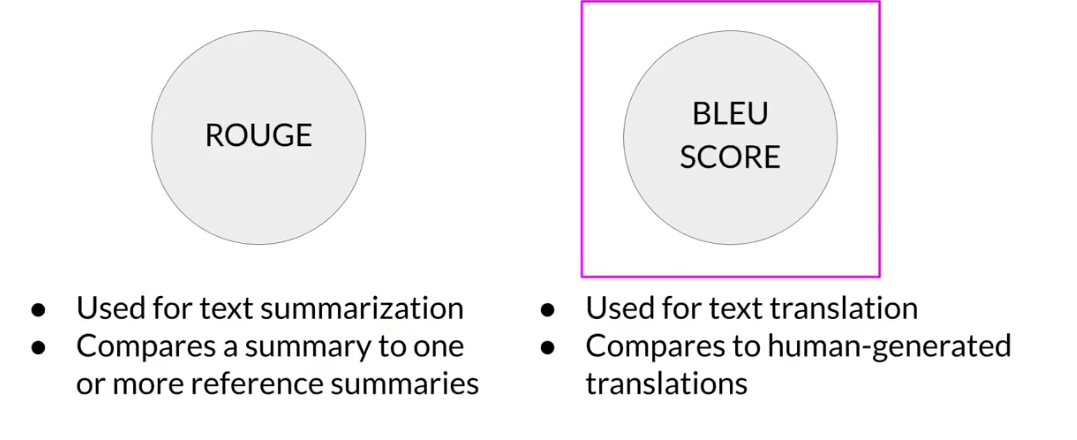
模型评估
对于计算机视觉的任务而言,比如分类任务,可以通过acc指标快速衡量模型是否准确,但是对于文本而言,可能因为一个词的差别整个句子的意义就发生了很大的变化,比如下面的案例。
这个时候有两个常用的指标来衡量文本生成的效果。
首先第一个是rouge分数,主要用来衡量两个句子之间的匹配程度,简单来理解,即使生成的里面有对应的文本里面的就行。其中1表示的就是1 gram.2 表示的就是bigram,如果是n则表示的是n gram。
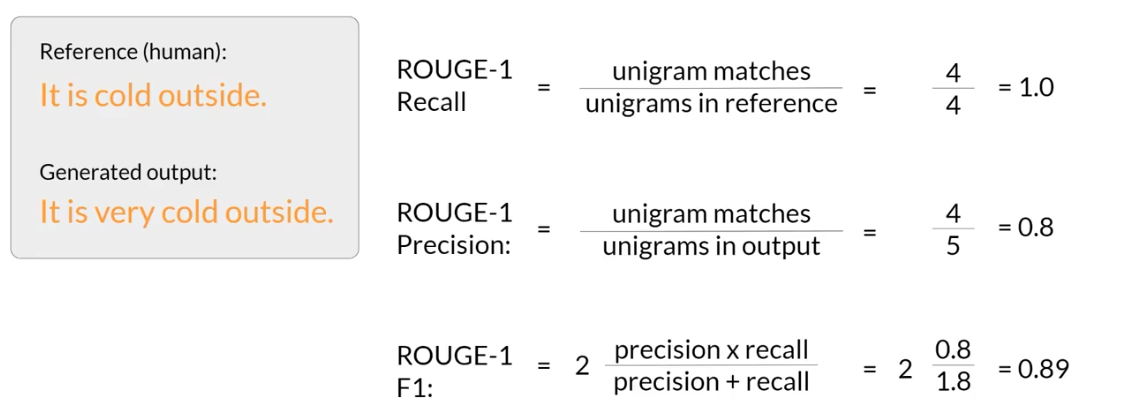
但是有的时候会产生比较拉的结果,比如里面出现了一个not,但是得分还是一致的。

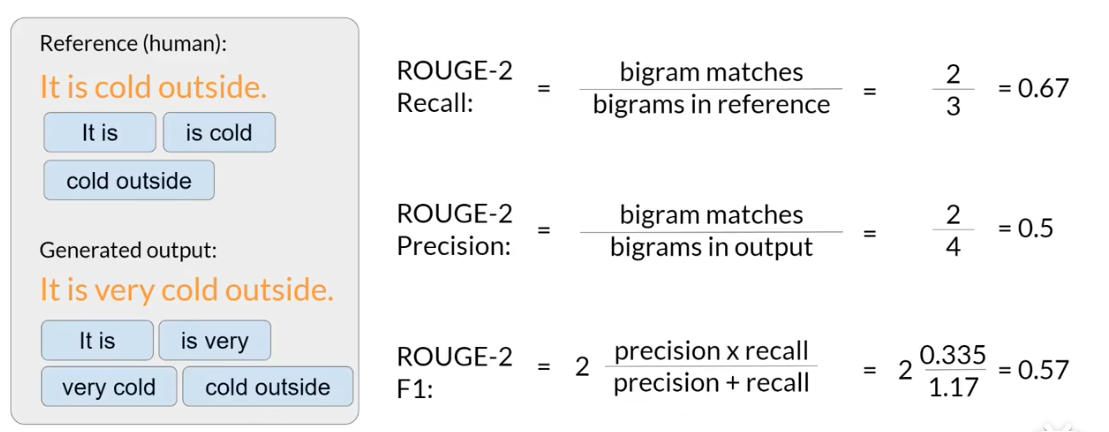
如果这个时候变成了l。则是用来寻找最长匹配的子序列。

但是这个评价是不公平的,比如下面的句子,他就是一个复读机,但是他也匹配了4次。
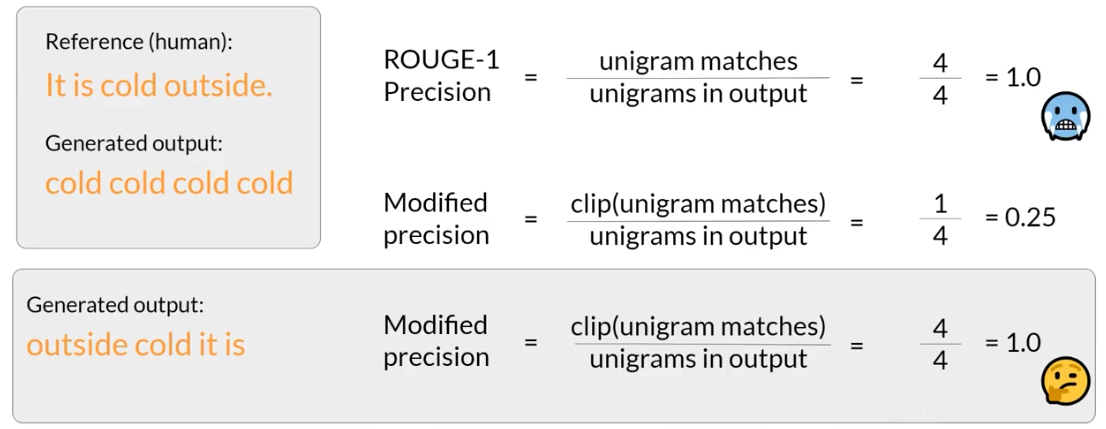
bleu分数如下,在huggingface的库中可以直接进行调用。

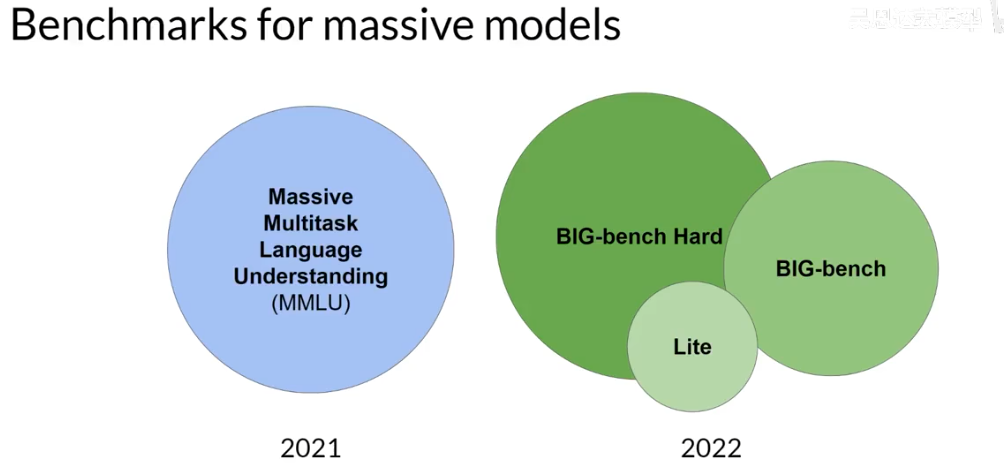
对于通用的大语言模型,大家设计了一系列的benchmark用来衡量模型的性能,如下所示。