文章目录

引言
在日活500万的业务场景下,用户行为埋点数据的实时采集与处理成为极具挑战性的技术难题。本文将以某互联网公司的真实案例为背景,深入探讨如何构建一个兼顾高性能、高可靠性和准实时查询能力的数据处理架构。我们将从业务需求出发,逐步拆解技术选型思路,揭示架构设计背后的深层考量。
一、业务场景与核心需求
1.1 业务背景
- 日活用户500万级别
- 用户行为埋点数据需实时采集
- 准实时查询需求(原始数据查询+多维统计)
- 基于埋点数据的第三方费用结算
1.2 数据结构特征
| 字段类型 | 说明 |
|---|---|
| 设备标识 | 唯一设备ID |
| 事件时间 | 精确到毫秒 |
| 目标类型 | 页面/按钮/广告位等 |
| 地理位置 | 经纬度信息 |
| 行为动作 | 点击/滑动/停留等 |
1.3 核心需求矩阵
| 需求维度 | 具体要求 |
|---|---|
| 数据写入 | 每日亿级数据写入,峰值QPS超10万 |
| 查询响应 | 原始数据查询<3s,统计报表<5s |
| 数据可靠性 | 数据丢失率<0.001% |
| 扩展性 | 支持动态增加查询维度 |
| 计算复杂度 | 实时聚合、关联业务数据、多维度统计 |
二、架构设计演进之路
2.1 初版架构的局限性
技术选型对比分析
| 方案 | 吞吐量 | 数据可靠性 | 实施复杂度 | 适用场景 |
|---|---|---|---|---|
| Redis | 10万QPS | 低 | 低 | 临时缓存 |
| Kafka | 百万QPS | 高 | 中 | 消息队列 |
| 本地日志 | 50万QPS | 极高 | 高 | 原始数据存储 |
淘汰原因:
- Redis AOF持久化策略难以平衡性能与可靠性(always模式性能差,everysec可能丢数据)
- Kafka在ack=all时延迟增加,无法满足毫秒级响应要求
2.2 最终架构方案
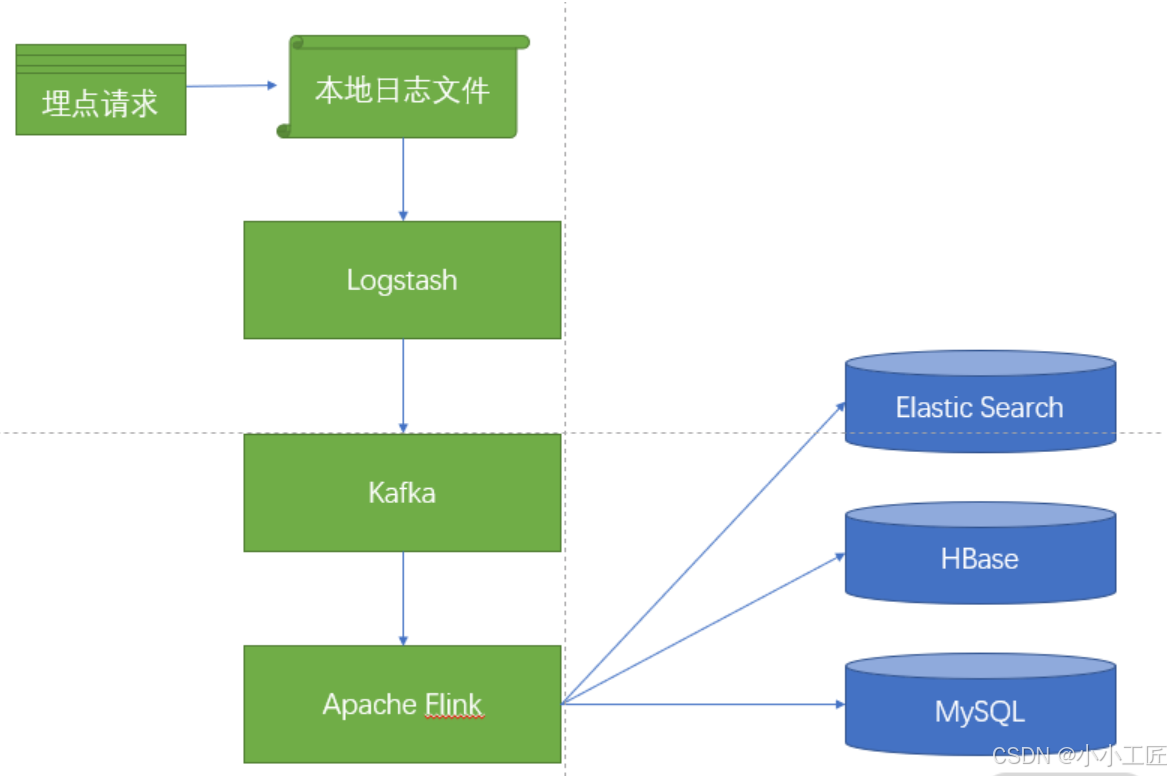
核心组件说明
-
本地日志存储
- 采用追加写入模式,单机写入性能可达50万QPS
- 使用滚动日志策略(每小时生成新文件)
- 文件命名规范:applog_KaTeX parse error: Expected group after '_' at position 7: {date}_̲{hour}.log
-
Kafka消息队列
- 分区策略:按设备ID哈希分片
- 配置参数:
acks=1 linger.ms=20 batch.size=16384 compression.type=lz4 - 吞吐量优化:单分区可达10万QPS
-
Flink实时处理
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(1000); // 1秒检查点间隔 DataStream<RawEvent> stream = env .addSource(new FlinkKafkaConsumer<>("topic", schema, props)) .keyBy(event -> event.getDeviceId()) .process(new EnrichmentProcessFunction()); // 数据补全 stream.addSink(new ESSink()); // ES写入 stream.addSink(new HBaseSink()); // HBase写入 stream.addSink(new MySQLSink()); // 统计计算
三、关键技术深度解析
3.1 数据可靠性保障
三级可靠性机制:
- 本地日志:采用双副本存储(不同磁盘)
- Kafka:ISR副本机制(min.insync.replicas=2)
- Flink:Checkpoint机制(精确一次语义)
# 日志文件同步脚本
rsync -avz /data/logs/applog*.log backup_server:/backup/logs/
3.2 数据补全策略
业务字段关联流程:
- 从原始日志中提取用户ID
- 查询用户中心服务获取完整画像
- 数据关联窗口机制:
- 最大等待时间:5秒
- 关联失败处理:写入死信队列
3.3 实时统计计算
Flink时间窗口设计:
stream.keyBy(event -> event.getPageId())
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.aggregate(new CountAggregate(), new WindowResultFunction());
窗口策略对比:
| 窗口类型 | 特点 | 适用场景 |
|---|---|---|
| 滚动窗口 | 固定大小,无重叠 | 准实时统计 |
| 滑动窗口 | 窗口可重叠 | 趋势分析 |
| 会话窗口 | 基于数据活跃度 | 用户行为分析 |
四、性能优化实践
4.1 写入优化
日志写入优化:
- 批量提交:积累1000条或200ms触发写入
- 零拷贝技术:使用sendfile系统调用
- 文件预分配:提前创建固定大小日志文件
4.2 计算层优化
Flink资源配置:
taskmanager.memory.process.size: 4096m
taskmanager.numberOfTaskSlots: 4
parallelism.default: 32
ES写入优化:
- 批量提交:每1000条或1秒提交一次
- 索引设计:
{ "settings": { "number_of_shards": 10, "refresh_interval": "30s" } }
五、架构收益与未来演进
5.1 实施效果
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 数据延迟 | 5-10分钟 | <30秒 |
| 写入吞吐量 | 5万QPS | 50万QPS |
| 查询响应时间 | 10-30秒 | 1-3秒 |
5.2 未来演进方向
- 流批一体架构:引入Flink Batch模式处理历史数据
- 智能压缩策略:根据数据类型自动选择压缩算法
- 边缘计算:在客户端预聚合基础指标
结语
在面对海量实时数据处理挑战时,架构设计需要像搭积木一样精心选择每个组件。本方案通过本地日志+Kafka+Flink的三级架构,在数据可靠性、处理实时性和系统扩展性之间找到了最佳平衡点。随着业务发展,我们仍需持续优化窗口机制、完善监控体系,让数据真正成为驱动业务增长的核心引擎。
