
标题:《A Review of Generalized Zero-Shot Learning Methods》
出版日期为2022年7月18日;工作由国家自然科学基金资助6217616年6061732011和61976141,部分由广东基础和应用基础研究基金资助2022A1515010791,部分由深圳大学自然科学基金会稳定支持计划资助号20200804193857002,部分由SZU的跨学科创新团队
摘要
广义零样本学习 ,即 Generalized Zero-Shot Learning(GZSL)的目的是在监督学习过程中某些输出类未知的条件下,训练一个模型来对数据样本进行分类;GZSL利用已看到(源)和看不见(目标)类的语义信息来弥补已知类和未见过类之间的差距。自其引入以来,许多GZSL模型已经被制定出来。在这篇综述论文中,我们对GZSL进行了全面的综述。 首先,提供了一个GZSL的概述,包括问题和挑战。然后,我们引入了GZSL方法的分类,并讨论了每个类别中的代表性方法。此外,还讨论了GZSL可用的基准数据集和应用,并讨论了研究中的差距和未来研究的方向
一、前言
随着在图像处理和计算机视觉方面的最新进展,深度学习(DL)模型由于其提供从特征提取到分类的端到端解决方案的能力而获得了广泛的普及。尽管传统的 DL模型很成功,但它们需要对每个类的大量标记数据进行训练 ,以及大量的样本。在这方面,收集大规模的标记样本是一个具有挑战性的问题。例如,ImageNet [1]是一个大的数据集,它包含1400万张图像,包含21,814个类,其中许多类只包含少数图像。此外,标准的DL模型只能识别属于在训练阶段已经看到的类的样本,并且它们不能处理来自不可见的类[2]的样本。而在许多现实场景中,可能不是所有类都有大量的标记样本。一方面,对大量样本进行细粒度注释是费力的,需要专家领域知识。另一方面,许多类别是缺乏足够的标记样本,例如,濒危鸟类 COVID-19。
几种用于各种学习配置的技术已经开发:One-shot [7] 和 few-shot[8]可以从少数的样本中学习。这些技术利用从其他类的数据样本中获得的知识,并建立一个分类模型来处理样本很少的类。虽然开放集识别(OSR)[9]技术可以识别一个测试样本是否属于一个不可见的类,但它们不能预测一个准确的类标签。分布外的[10]技术试图识别不同于训练样本的测试样本。然而,上述任何一种技术都不能从未见过的类中对样本进行分类。相比之下,人类可以识别大约30,000个类别[11],其中我们不需要提前学习所有这些类别。例如,如果一个孩子可以很容易地识别斑马,如果他/她以前见过马,并且知道斑马看起来像一匹有黑白条纹的马。零样本学习(ZSL)[12],[13]技术为解决这一挑战提供了一个很好的解决方案。
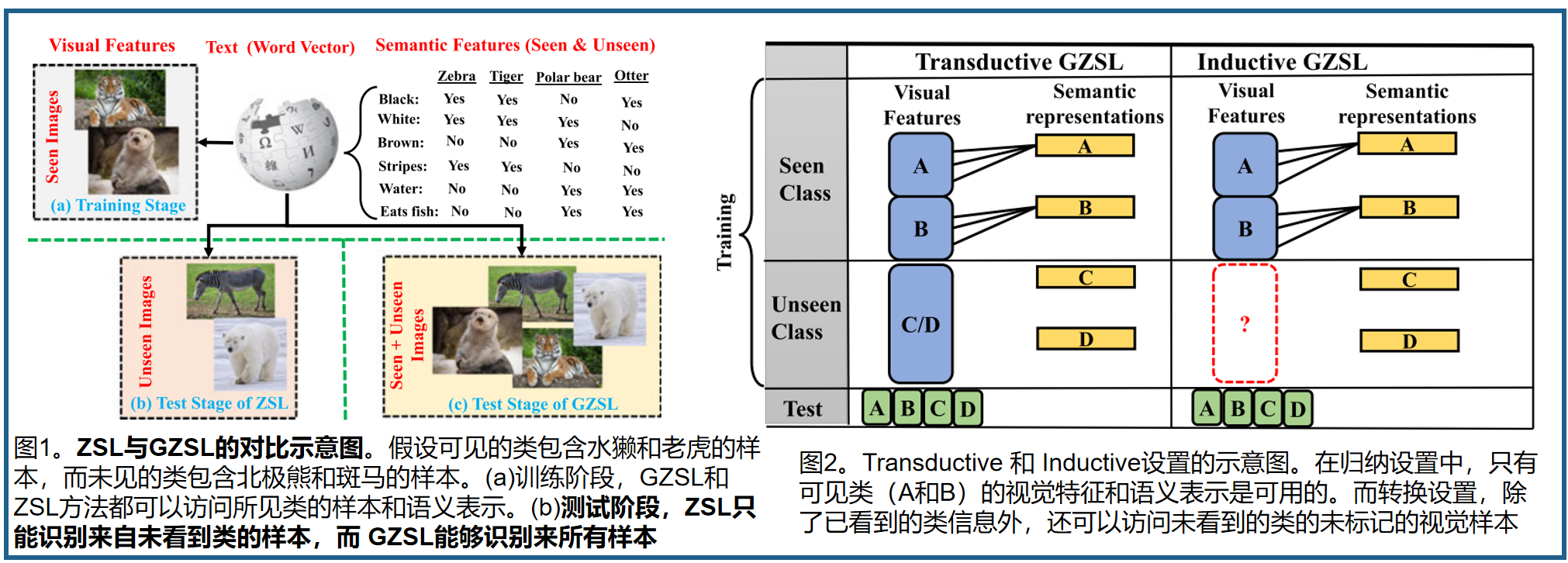
ZSL零样本学习的目标是训练一个模型,通过语义信息转移从其他可见类(源域)获得的知识,对不可见类(目标域)进行分类。语义信息在高维向量中嵌入可见类和看不见类的名称。语义信息可以手动定义属性向量[14]、自动提取词向量[15]、基于上下文的嵌入[16],或它们的组合[17]、[18]。换句话说,ZSL使用语义信息来弥合可见类和看不见类之间的差距。在识别一个新物体时,通过测量其描述和之前学习到的概念[19]之间的可能性,可以将这种学习范式与人类进行比较。在传统的ZSL技术中,测试集只包含来自看不见的类的样本,这是一个不现实的设置,它不能反映真实世界的识别条件。在实践中,可见类的数据样本比看不见类的数据样本更常见,因此需要同时识别来自这两个类的样本,而不是只对看不见类的数据样本进行分类。这种设置被称为广义零样本学习(GZSL)[20]。事实上,GZSL是ZSL的一个实用版本。GZSL的主要动机是模仿人类的识别能力,它可以识别来自可见和看不见类别的样本。图1为GZSL和ZSL的示意图
Socher等人[15]在2013年首次引入了GZSL的概念。将一种离群值检测方法集成到它们的模型中,以确定一个给定的测试样本是否属于可见类的流形。如果它来自一个可见的类,则使用一个标准的分类器;否则,通过计算成为一个不可见的类的可能性,将一个类分配给该图像。同年,Frome等人[21]试图利用文本数据学习标签之间的语义关系,然后将图像映射到语义嵌入空间的位置。Norouzi等人[22]使用类标签嵌入向量的凸组合将图像映射到语义嵌入空间,试图识别来自可见类和不可见类的样本。然而,GZSL直到2016年才获得牵引力,当时Chao等人[20]的经验表明,ZSL设置下的技术在GZSL设置下不能表现良好。这是因为ZSL很容易对可见的类进行过拟合,即,将来自不可见类的测试样本分类为来自可见类的类。后来,Xian等人[23]、[24][25]分别在ZSL的图像和网络视频数据上获得了类似的发现。这主要是因为现有的技术对可见类有强烈的偏见(bias),其中几乎所有属于不可见类的测试样本都被归类为可见类之一。为了缓解这一问题,Chao等人[20]引入了一种有效的校准技术,称为校准堆叠(calibrated stacking),以平衡识别来自可见类和不可见类的样本之间的权衡,这允许学习关于不可见类的知识。从那时起,在GZSL设置下提出的技术数量从根本上增加。
二、广义零样本学习概述
2.1 问题的公式化
让 S S S={ ( x i s , a i s , y i s ) (x^s_i,a^s_i,y^s_i) (xis,ais,yis) i = 1 N s _{i=1}^{Ns} i=1Ns | x i s ∈ X i s , a i s ∈ A i s , y i s ∈ Y i s x^s_i∈X^s_i,a^s_i∈A^s_i,y^s_i∈Y^s_i xis∈Xis,ais∈Ais,yis∈Yis} 和 U U U={ ( x j u , a j u , y j u ) (x^u_j,a^u_j,y^u_j) (xju,aju,yju) j = 1 N u _{j=1}^{Nu} j=1Nu | x j u ∈ X j u , a j u ∈ A j u , y j u ∈ Y j u x^u_j∈X^u_j,a^u_j∈A^u_j,y^u_j∈Y^u_j xju∈Xju,aju∈Aju,yju∈Yju} 分别表示可见和不可见的类数据集,其中 x i s , x j u ∈ R D x^s_i, x^u_j∈R^D xis,xju∈RD 表示特征空间 X X X中的d维图像(视觉特征),可以使用预训练的深度学习模型,如ResNet [28],VGG-19 [29],GoogLeNet [30]获得; a i s , a j u ∈ R K a^s_i,a^u_j∈R^K ais,aju∈RK表示语义空间A中的k维语义表示(即属性或词向量); Y s Y^s Ys ={ y 1 s , . . . , y C s s y^s_1, ..., y^s_{Cs} y1s,...,yCss}和 Y u Y^u Yu表示标签空间Y中可见和看不见类的标签集,其中 C s C_s Cs和 C u C_u Cu是可见和不可见的类的数量, Y Y Y= Y s Y^s Ys∪ Y u Y^u Yu表示可见和不可见类的并集; Y s Y^s Ys∩ Y u Y^u Yu为空。GZSL目标是学习一个模型 f G Z S L f_{GZSL} fGZSL: X → Y X\rightarrow Y X→Y,用于分类 N t N_t Nt个测试样本,即 D t s D_{ts} Dts = { x m , y m x_m,y_m xm,ym} m = 1 N t _{m=1}^{Nt} m=1Nt.
GZSL方法的训练阶段可分为两大设置:归纳学习(inductive learning)和转导学习(transductive learning)[24]。
1.归纳学习:
-
训练阶段:仅使用可见类的数据。
-
测试阶段:模型需要同时处理可见类和不可见类的数据。
-
目标:通过可见类的知识推断不可见类的属性或特征
2.转导学习:
-
训练阶段:使用可见类的数据,并结合测试数据的特征分布(无标签)。
-
测试阶段:模型需要同时处理可见类和不可见类的数据。
-
目标:通过利用测试数据的分布信息,提升模型对不可见类的分类性能。
图2显示了transductive GZSL和 inductive GZSL设置[32],[33]的主要差异。可以看到,可见类的先验对这两种设置都可用,但未可见类的先验的可用性取决于该设置,如下所示。在归纳学习设置中,没有关于看不见的类的先验知识。在可转换学习设置中,模型使用未见类的未标记样本,未见类的先验是可用的。虽然在转导学习[34][35][36][37][38][39][40][41]下已经开发了一些框架,但这种学习模式是不切实际的,且违反了看不见的假设。另一方面,假设所有不可见的类的未标记数据都是可用的,是不现实的。此外,一些研究[35]、[36][42][43]在训练过程中使用了不可见类的所有图像样本,而其他研究[44]、[45]将样本分成两个相等的部分,一个用于训练,另一个用于推理
最近,一些研究人员[33],[46],[47]认为,在第3.2节中回顾的大多数基于生成的方法都不是纯粹的归纳学习,因为看不见的类的语义信息被用于生成看不见的类的视觉特征。他们将这种基于生成的方法归类为语义转换学习(semantic transductive learning)。此外,他们还提出了归纳的基于生成式的方法[33]、[46]、[47],在测试前不访问未见类的语义信息。
2.2 语义信息
由于没有来自不可见类的标记样本,语义信息被用来建立可见类和未见类之间的关系,其必须包含所有未见类的识别属性,以保证为每个不可见的类提供足够的语义信息。它还应与特征空间中的样本相关联,以保证语义信息的可用性。语义信息构建了一个包含可见类和未见类的空间,可用于执行ZSL和GZSL。 例如,如果一个孩子以前见过马,可以很容易地识别斑马,因为斑马看起来像一匹有黑白条纹的马。GZSL中最广泛使用的语义信息可以分为手动定义的属性[13]、词向量[48]或它们的组合。
手动定义的属性:描述了一个类(类别)的高级特征,如形状(圆等)和颜色(蓝色),使GZSL模型能够识别世界上的类。属性是准确的,但需要人工努力的注释,这不适合大规模问题[49]。Wu等人[50]提出了一种全局语义一致性网络(GSC-Net)来利用可见类和不可见类的语义属性。Lou等人[51]根据属性标签树开发了一个数据特定的特征提取器。
词向量:是自动从大型文本语料库(如维基百科)中提取的,以表示不同单词之间的异同,并描述每个对象的属性。词向量需要更少的人力劳动,因此它们适用于大规模的数据集。然而,它们包含了影响模型性能的噪声。例如,Wang等人[52]应用Node2Vec生成概念化的词向量。[53]、[54]、[55]、[56]的研究试图从嘈杂的文本描述中提取语义表示,Akata等[57]提出从多个文本源中提取语义表示。
2.3 Embedding Spaces 嵌入空间
大多数GZSL方法学习一个Embedding 嵌入/mapping映射函数,将所见类的低级视觉特征与其相应的语义向量联系起来。该函数可以通过岭回归损失[59]、[60]或对两个空间[61]的兼容性分数的排名损失进行优化。然后,利用学习到的函数,通过测量嵌入空间中数据样本的原型表示和预测表示之间的相似性水平,来识别新的类。由于属性向量的每个条目都表示对类的描述,因此期望具有相似描述的类在语义空间中包含一个相似的属性向量。然而,在视觉空间中,具有相似属性的类可能会有很大的变化。因此,寻找这样的嵌入空间是一项具有挑战性的任务,会导致视觉语义歧义问题
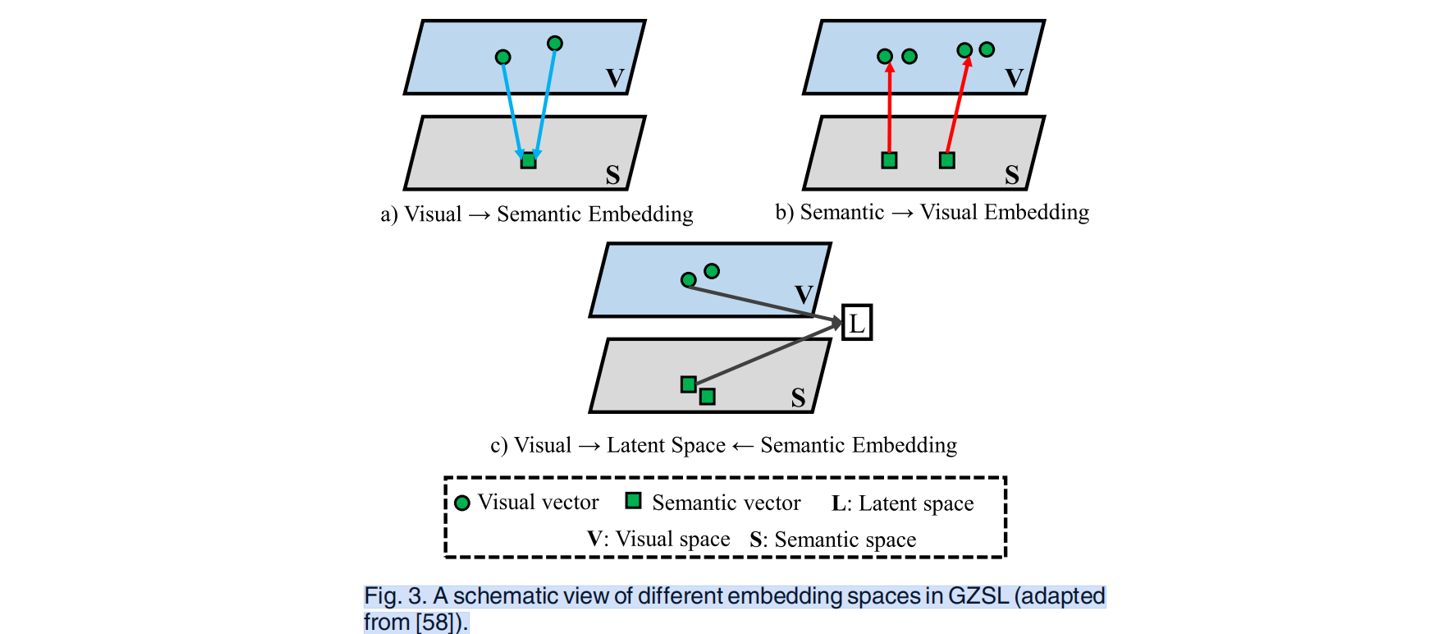
嵌入空间可以分为欧几里得空间和非欧几里得空间。欧几里得空间虽然比较简单,但也有信息丢失的问题。非欧几里得空间通常基于图网络、流形学习或聚类,通常利用空间之间的几何关系来保持数据样本[27]之间的关系。另一方面,嵌入空间可以分为:语义嵌入、视觉嵌入和潜在空间嵌入[58]
1.语义嵌入:(图3a) 使用不同的约束或损失函数学习从视觉空间到语义空间的(前向)投影函数,并在语义空间中进行分类。目的是强制属于一个类的所有图像的语义嵌入映射到真实的标签嵌入[61][62]。一旦得到最佳投影函数,就可以进行最近邻搜索来识别测试图像。
2.视觉嵌入:(图3b)学习(反向)投影函数,将语义表示(back)映射到视觉空间,并在视觉空间中进行分类。其目的是使语义表征接近其对应的视觉特征[59]。在得到最佳投影函数后,可以利用最近邻搜索来识别给定的测试图像
3.Latent Embedding: 语义和视觉嵌入模型都从一个模态的空间,到其他模态的空间学习投影/嵌入函数。然而,由于不同模态的独特特性,学习两个空间之间的显式投影函数是一个具有挑战性的问题。在这方面,潜在空间嵌入(图3c)将视觉特征和语义表示投射到一个公共空间L中,即一个潜在空间,以探索不同模式[40]、[63]、[64]之间的一些共同语义属性。其目的是将附近每个类的视觉和语义特征投射到潜在空间中。一个理想的潜在空间应该满足两个条件: (i)类内紧致性和(ii)类间可分性[40]
2.4 挑战
hubness问题是指在高维空间中,某些点(称为“枢纽点”)会成为大量其他点的最近邻,而其他点则很少或几乎不会成为任何点的最近邻。这种现象会导致模型在预测时过度依赖这些枢纽点,从而影响分类的准确性和公平性
Hubness问题成因:
-
高维空间的特性:在高维空间中,数据点之间的距离分布变得不均匀,导致某些点更容易成为枢纽点。
-
语义嵌入空间的构建方式:在零样本学习中,语义嵌入空间通常是通过属性、词向量或其他语义信息构建的。如果嵌入空间的构建不够合理,可能会导致某些类别的嵌入向量过于集中,从而加剧Hubness问题。
-
最近邻搜索的局限性:最近邻搜索方法(如K近邻算法)在高维空间中容易受到Hubness问题的影响,因为距离度量在高维空间中可能失去区分能力。
投影域移位(eprojection domain shift problem)问题 :ZSL和GZSL模型都首先利用所看到的类的数据样本来学习视觉空间和语义空间之间的映射函数。然后,利用学习到的映射函数将看不见的类图像从视觉空间投影到语义空间。一方面,视觉空间和语义空间都是两个不同的实体。另一方面,可见类和不可见类的数据样本是不相交的,对某些类不相关,它们的分布可能不同,导致很大的域差距。因此,使用可见类的数据样本学习嵌入空间,而不对不可见类进行任何适应,会导致投影域移位问题[42],[63],[66]。由于GZSL方法在推理过程中需要识别可见类和看不见类,它们通常偏向于可见类,因为在学习过程中看到类的视觉特征的可用性。因此,学习一个精确的映射函数来避免偏差,并确保所得到的GZSL模型的有效性是至关重要的
普通(传统)的领迁移问题,两个领域共享相同的类别,且只有输入和输出的联合分布在训练阶段和测试阶段之间有所不同;projection domain shift 可以直接观察到投影 shift,而不是特征分布 shift 。
图4a显示了一个理想的无偏映射函数,它迫使可见和不可见类的投影视觉样本在潜在空间中包围它们自己的语义特征。在实践中,训练和测试样本在GZSL任务中是不相交的,导致我们学习了一个针对已被看到的类的无偏映射函数,它可以将未被看到的类的视觉特征投射到远离其语义特征的地方(见图4b)。人们还开发了几种基于交叉活动的方法来缓解投影域的移位问题[35][36][37][38]。这些方法使用了看不见的类的多种信息来进行学习。
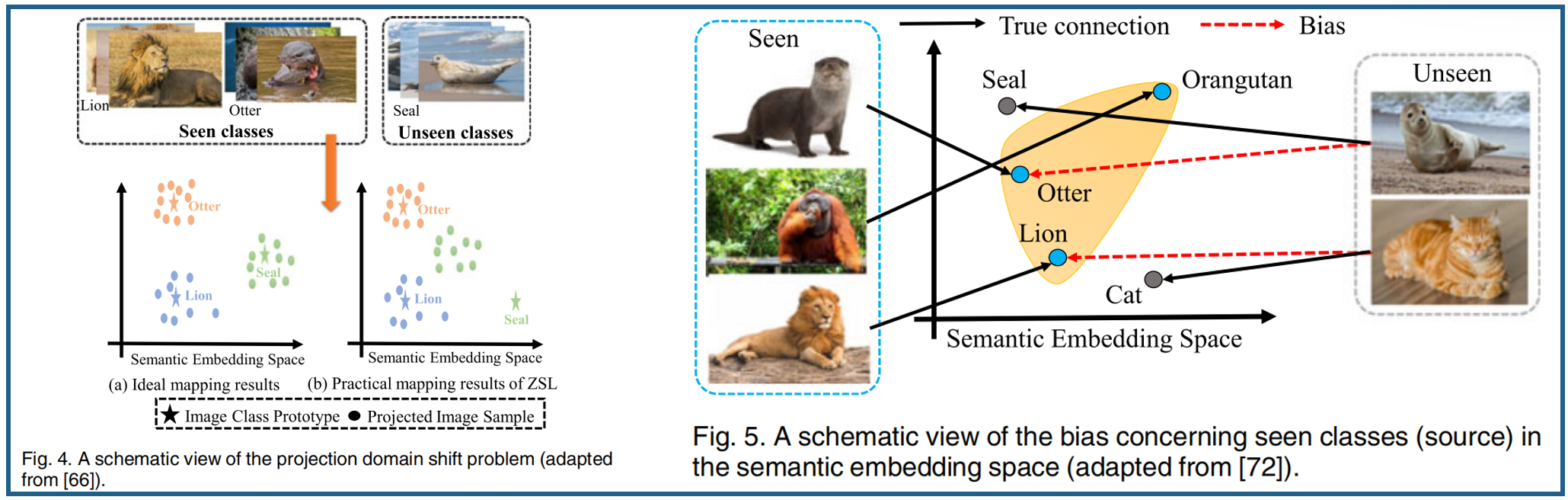
GZSL使用可见类样本来学习模型执行识别看到和看不见的类,他们通常偏向看到类,导致数据的错误分类看不见的类看到类(见图5),在大多数ZSL方法不能有效地解决这个问题[72]。为了缓解这一问题,人们提出了几种策略,如校准堆叠calibrated stacking[20][73]和新类检测器[15][74][75][76]。校准堆叠[20]方法使用以下公式平衡识别已见和未见类的数据样本之间的权衡:
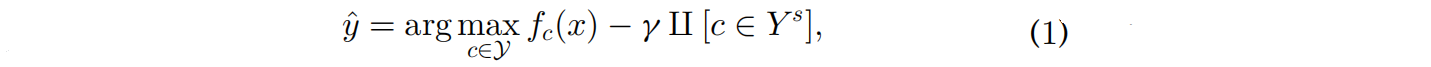 其中 γ γ γ是一个校准因子, Ⅱ [ ] ∈ Ⅱ[]∈ Ⅱ[]∈{
0 , 1 0,1 0,1}表示c是否来自可见类或其他类。 γ γ γ为一个来自不可见的类的样本的先验可能性。当 γ → − ∞ γ→-∞ γ→−∞,分类器将数据分类为一个可见类,反之亦然。Le等人[77]提出找到一个最优g来平衡可见类和看不见类的准确性之间的权衡。后来,一些研究使用校准的堆叠技术来解决GZSL问题[73][78][79][80][81]。
其中 γ γ γ是一个校准因子, Ⅱ [ ] ∈ Ⅱ[]∈ Ⅱ[]∈{
0 , 1 0,1 0,1}表示c是否来自可见类或其他类。 γ γ γ为一个来自不可见的类的样本的先验可能性。当 γ → − ∞ γ→-∞ γ→−∞,分类器将数据分类为一个可见类,反之亦然。Le等人[77]提出找到一个最优g来平衡可见类和看不见类的准确性之间的权衡。后来,一些研究使用校准的堆叠技术来解决GZSL问题[73][78][79][80][81]。

后来,基于熵[76]、基于概率[75][87]、基于距离[88]、基于聚类[89]和参数新类检测[50]方法被开发出来来检测OOD不可见的类。Felix等90]学习了一个使用潜在空间的鉴别模型,来识别一个测试样本是属于一个可见的类还是属于一个不可见的类。Geng等人[91]将GZSL分解为开放集识别(OSR)[9]和ZSL任务。
三、回顾GZSL方法
GZSL的主要思想是通过语义表示法,将知识从可见的类转移到看不见的类,从而对可见的类和看不见的类的对象进行分类。为了实现这一点,必须解决两个关键问题: (i)如何将知识从可见的类转移到看不见的类;(ii)如何学习一个模型来识别来自可见和不可见类的图像,而不需要访问不可见类的带标签样本[2]。方法可大致分为:
基于生成的方法:学习一个模型,基于可见类的样本和两种类的语义表示,生成看不见类的图像或视觉特征。生成不可见类样本,可以将GZSL问题转换为传统的监督学习问题(图6b)。基于单一同质过程,可以训练一个模型,对属于可见类和不可见类的测试样本进行分类,解决偏差问题。虽然这些方法在视觉空间中进行识别,并且可以归类为视觉嵌入模型
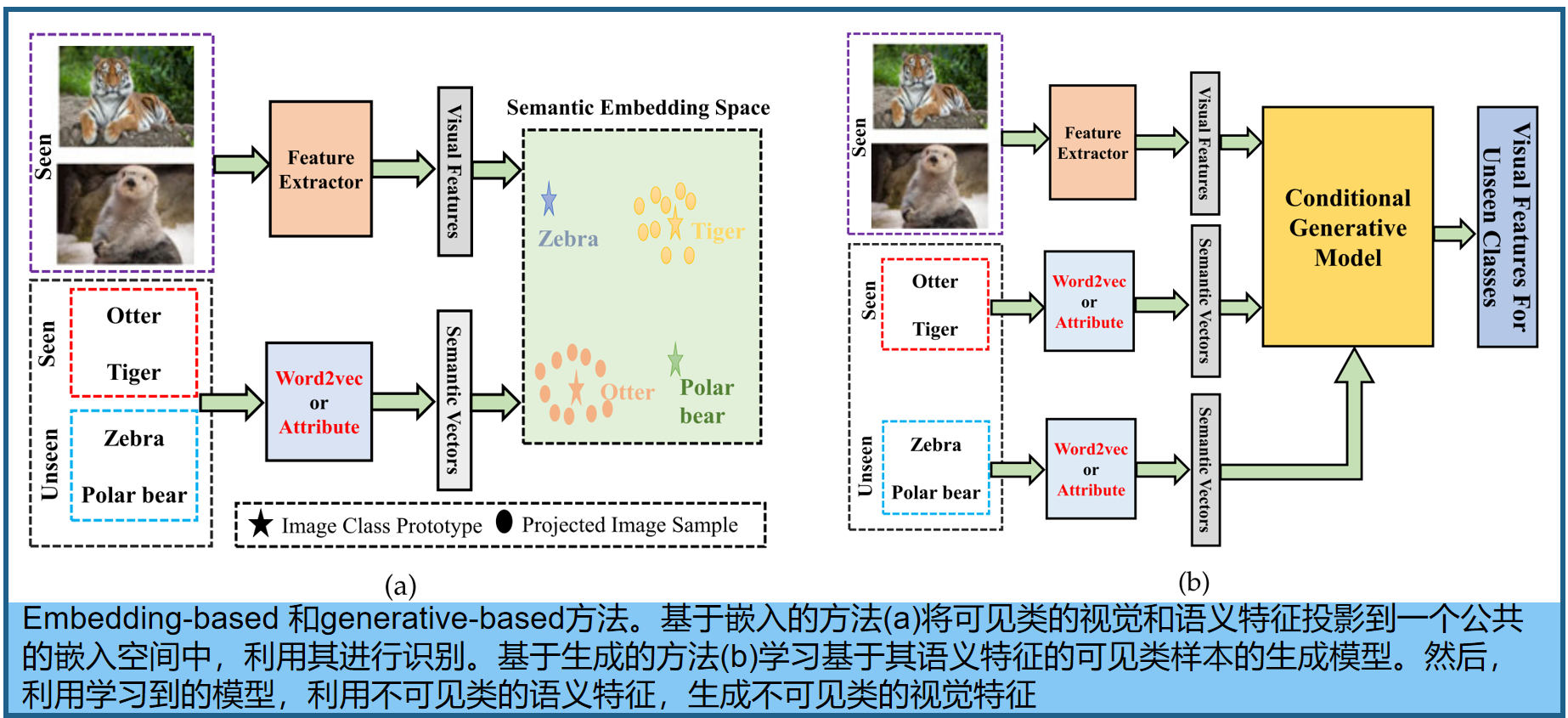
3.1 基于 Embedding方法
即:学习一个嵌入空间,将所看到的类的低级视觉特征与其对应的语义向量联系起来。学习投影函数通过 测量嵌入空间中数据样本的原型表示和预测表示之间的相似性水平来识别新的类(图6a)
基于嵌入的方法可分为基于图、基于注意、基于自动编码器、元学习、组合学习和双向学习等方法,如图7所示。补充的表4提供了这些方法的总结。

3.1.1 基于分布外检测的方法
分布外或异常值检测旨在识别与其他可用样本异常或显著不同的数据样本。一些研究应用离群值检测技术来解决GZSL任务[15][74][75][92]。首先,使用离群值检测技术将已看到的类实例与未看到的类实例分开。然后,采用领域专家分类器(可见/不可见),如可见类的标准分类器和不可见类的ZSL方法,分别对可见的和看不见的类数据样本进行分类。Lee等人[92]开发了一种基于基于语言信息的层次分类法的novelty检测器。他们的方法使用已知类之间的超对称关系构建了一个分类法,在某种程度上,看不见的类的对象应该被分类为最相关的可见类之一。Atzmon和Chechik [75]设计了一种基于概率的门控机制,并在门控机制中引入了一种类拉普拉斯的先验,以区分可见的类样本和看不见的类样本。然而,训练gate是一个具有挑战性的问题,因为训练期间无法使用不可见类的视觉特征。为了解决这一问题,提出了基于边界的OOD分类器[93]、语义编码分类器[94]和基于熵gate[74]的域检测器从可见类样本中分离可见类样本。此外,[95][96]的研究将OOD技术集成到生成方法中来处理GZSL任务。

3.1.2 Graph-Based 方法
Graph 对于建模一组具有由节点及其关系(边)[97]组成的数据结构的对象很有用。图学习利用机器学习技术提取相关特征,将Graph-Based属性映射到嵌入空间中具有相同维度的特征向量中,不需要投影信息到一个低维空间中[98]。通常,每个类在Graph-Based方法中都被表示为一个节点。每个节点通过编码它们的关系的边连接到其他节点(即类)。与其他技术[63]相比,潜在空间中特征的几何结构被保留在一个图中,从而得到了更丰富的信息的紧凑表示。尽管如此,学习一个使用结构化信息和复杂关系的分类器,而不需要可视化的类是一个具有挑战性的问题,而基于图的信息的使用增加了模型的复杂性。
最近,Graph learning技术在GZSL 的方法,如 shared reconstructed graph(SRG)[63](图8)使用每个类的聚类中心,表示图像特征空间中的 class prototype,并重构每个语义prototype如下:( b k ∈ R K × 1 b_k∈R^{K×1} bk∈RK×1为重建系数)
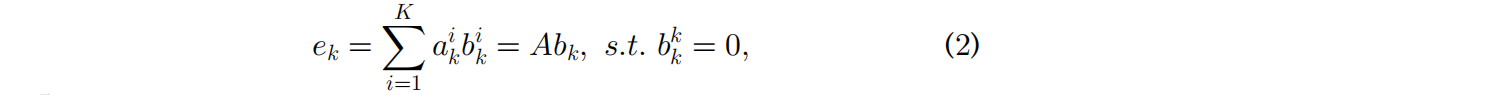
学习了类之间的关系后,再学习可见与不可见空间之间的共享重建系数,为不可见的类合成图像原型。SRG包含一个稀疏性约束,它使模型能够将类划分为许多不同子空间的簇。在重建过程中,采用正则化项来选择较少且相关的类。重构系数被共享,以便将知识从语义原型转移到图像原型。此外,采用不可见的语义嵌入方法来缓解 Projection Domain Shift Problem(投影域偏移问题:seen类和unseen类的投影不一致性,导致模型在训练时学习的视觉特征到语义空间的投影函数无法泛化到unseen类),采用可见图像原型的图来缓解 Space Shift Problem(空间偏移问题:语义空间的不对齐:seen类和unseen类的语义描述,如词向量,可能分布在语义空间的不同区域,导致unseen类的语义嵌入无法与视觉特征对齐)。
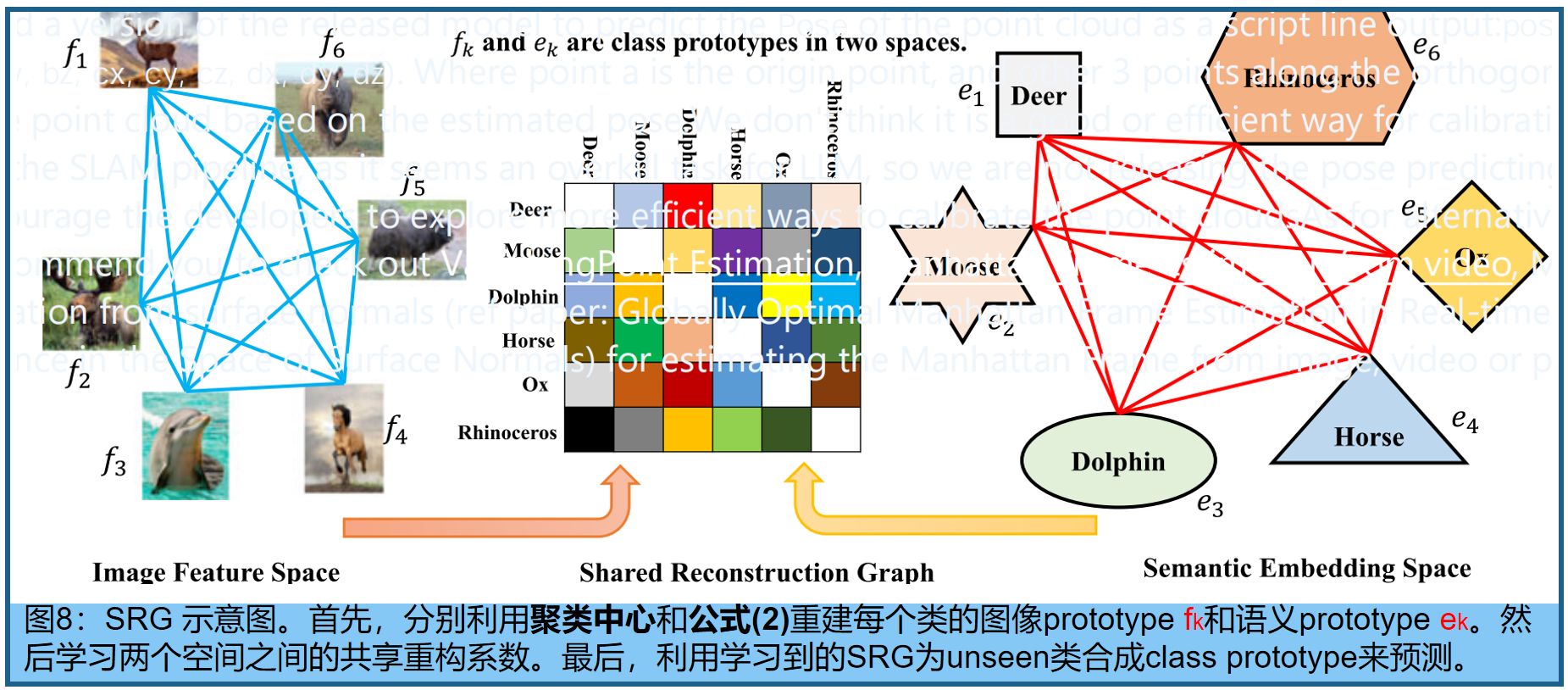
AGZSL [99],即基于非对称图的ZSL,通过构造一个非对称图,将class-level语义流形与instance-level视觉流形相结合。此外, 对不同类的视觉特征和属性特征的投影进行正交约束 (确保其无线性相关性)。[52][104][105][106]的研究利用图卷积网络(GCN)[107]在不同类别之间转移知识。在[52][104]中,应用GCN在语义空间中生成超类 (将多个细粒类别聚类形成的更高层次的语义类别)。利用余弦距离最小化可见类的视觉特征与相应语义表示之间的距离,并优化triplet margin loss来避免hub问题。Discriminative anchor generation and distribution alignment(DAGDA)[105]使用基于扩散的GCN为每个类别生成锚点。具体地说,导出了语义关系正则化来细化锚定空间中的分布。为了缓解hubness问题,采用了两个自动编码器,将这两个特征的原始信息保持在潜在空间中。除此之外,Xie等人[106]设计了一种注意技术来寻找图像中最重要的区域,然后将这些区域作为一个节点来表示图。
3.1.3 Meta Learning-Based 方法
元学习,即学会学习,是从其他学习算法中学学到一个学习范式,目的是从一组辅助任务中提取可转移的知识,以设计一个模型,同时避免过拟合问题。其基本原理有助于识别特定数据集的最佳学习算法。元学习通过根据实验结果改变某些方面,并通过优化实验数量,提高了学习算法的性能。[108][109][110][111][112][113]利用元学习策略来解决GZSL问题,该方法将训练类分为两类,即 support和 query,分别对应于可见类和不可见类。通过从支持集和查询集中随机选择类来训练不同的任务。这种机制有助于元学习方法将知识从看不见的类转移到看不见的类,从而减轻了偏差问题[112]
Sung等人[108]使用元学习方法训练了一个辅助参数化网络。目的是优化GZSL的前馈神经网络。 具体地说,设计了一个relation模块来计算cooperation模块的输出与数据样本的特征向量之间的相似性度量。然后,利用学习到的函数进行识别。在[109]中引入的元学习方法由一个提供初始预测的任务模块和一个更新初始预测的校正模块组成。设计了各种任务模块来学习训练样本的不同子集。然后,通过对校正模块的训练来更新来自任务模块的预测。针对GZSL的基于生成的元学习模块的其他例子也可用,例如[110][111][112][113]
3.1.4 Attention-Based 方法
基于注意力的方法专注于学习最重要的图像区域。换句话说,注意机制寻求在模型中添加权重,作为可训练的参数,以增加输入中最重要的部分,如句子和图像。一般来说,基于注意力的方法对于识别细粒度的类是有效的,因为这些类只在少数区域包含鉴别信息。根据基于注意力的方法的一般原理,将图像划分为多个区域,并应用注意技术[83][114]识别出最重要的区域。注意机制的主要优点之一是它能够识别与在输入中执行任务相关的重要信息,从而提高结果。另一方面,注意机制通常会增加计算负荷,影响基于注意的方法的实时实现
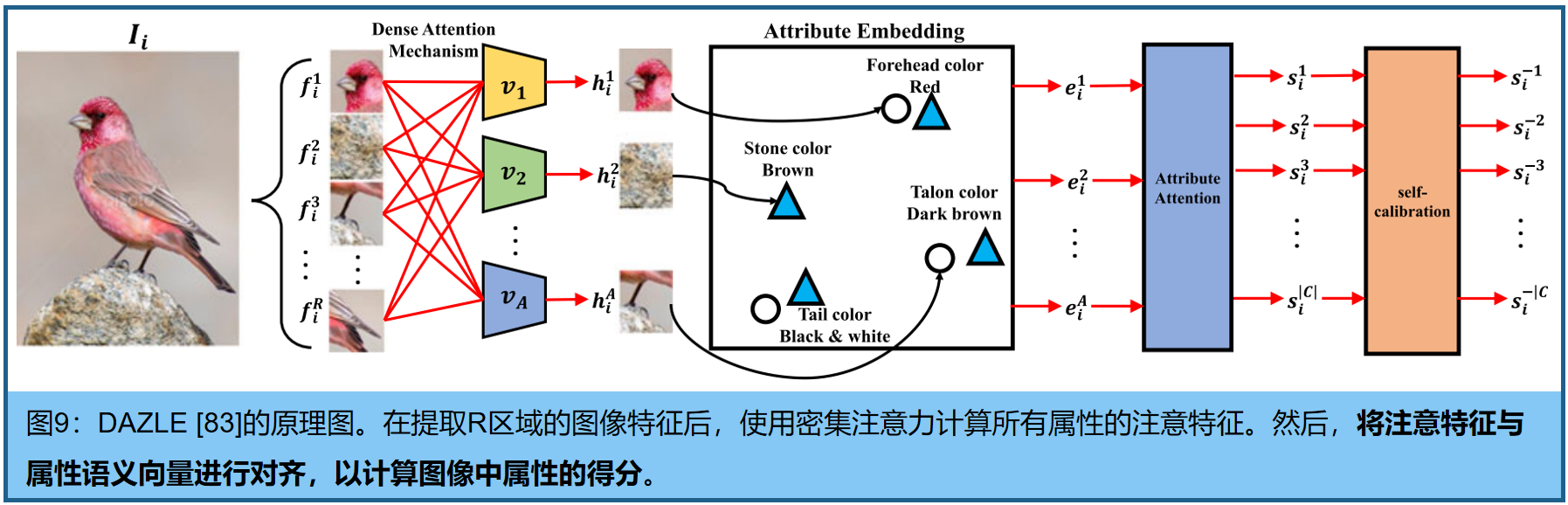
密集注意力零样本学习(DAZLE)[83](图9)通过关注与每个属性相关的最相关的区域来获得视觉特征。然后,设计了一种属性嵌入技术,将得到的每个属性特征与其相应的属性语义向量进行调整。采用类似的方法来解决[115]中的多标签GZSL问题。注意区域嵌入网络(AREN)[114]采用了注意压缩的二阶嵌入机制,自动发现识别区域并捕获二阶外观差异。[33]通过使用自聚焦机制测量每个维度的聚焦比向量来形成一个嵌入空间。Zhu等人[31]使用了一个多注意力模型来将视觉特征映射到一个有限的特征向量集中。每个特征向量被建模为一个具有各向同性分量的C维高斯混合模型。使用这些低维嵌入机制可以使模型关注图像中最重要的区域,并去除不相关的特征,从而减少语义-视觉差距。此外,还提出了一种视觉识别,以降低噪声,并提供关于类存在/不存在的信息
gaze estimation module(GEM) [117]受人类注视行为的启发,即关注具有辨别属性的物体的部分,旨在提高辨别属性的定位。在[118]中,局部属性用于将局部特征投影到语义空间中。它利用全局平均池方案作为聚合机制来进一步减少偏差(因为获得的看不见类的模式与已看到类的模式相似),并改进本地化。相比之下,语义引导的多注意(SGMA)定位模型[119]联合学习全局和局部特征,以提供更丰富的视觉表达。
3.1.5 Bidirectional Learning 方法
这类方法利用双向投影 来充分利用数据样本中的信息,并学习更一般化的投影,以区分可见的和不可见的类[58][80][125][126]。[125]将视觉空间和语义空间共同投影到一个共享的子空间中,然后通过双向投影学习重建每个空间。双三元网络(DTNet)[126]使用两个三元模块来构造一个更具区别性的度量空间,即通过学习从属性空间到视觉空间的映射来考虑类别之间的属性关系,另一个则考虑视觉特征
Guo等人[80]通过一个损失函数,联合最小化image view labels 和 label-view image rankings,来考虑双视图排名。这种双视图排序方案使模型能够训练出更好的图像标签匹配模型。此外,利用密度自适应边界,根据数据样本设置margin。这是因为:
- 1.图像的密度在不同的特征空间中有所不同,而且
- 2.不同的图像可能有不同的相似性得分。
解决方案是根据数据样本的分布特性动态调整边界,使得在密集区域设置较大边界以更好区分相似样本,在稀疏区域使用较小边界。此外,还在语义和标签之间添加了双向重构约束,以缓解投影移位问题。
Zhang等人[32]解释了一个类级过拟合问题。它与未知类训练中的参数拟合有关。为了解决这一问题,我们使用了一个三重验证网络(TVN)来解决GZSL作为一个验证任务。验证过程的目的是预测一对给定的样本是属于同一类还是属于其他类别。TVN模型将所看到的类投影到一个正交空间中,以获得更好的性能和更快的收敛速度。然后,提出了一种对偶回归(DR)方法,对视觉特征和语义表示进行回归,以与不可见的类兼容。
3.1.6 Autoencoder-Based 方法
自动编码器(AEs)是一种利用神经网络进行表示学习的无监督学习技术。他们首先学习如何压缩/编码数据。然后,他们学习如何将数据重构为尽可能接近原始数据的表示。换句话说, AEs利用编码器来学习嵌入空间,然后使用解码器来重构输入。AEs的主要优点是它们可以以无监督的方式进行训练
AEs已被广泛用于解决GZSL问题:通过附加约束来学习不同的映射[127]。Biswas和Annadani提出的框架[128]将相似度水平,例如余弦距离,整合到目标函数中以保持关系。潜在空间编码(LSE)[129]探索不同模态之间的某些共同语义特征并将它们连接起来。 对于每个模态,利用一个编码器-解码器框架,其中编码器用于将输入分解为潜在表示,而解码器则用于重建输入 。 乘积量化ZSL(PQZSL)[130]定义了一个正交的共同空间,通过中心损失函数[131]和自动编码器分别学习码本,将视觉特征和语义表示投影到共同空间中。正交的共同空间使类别更加区分,从而使模型能够获得更好的性能。此外,PQZSL使用量化器将视觉特征压缩为紧凑的代码,以近似最近邻。
正交约束:
-
1.正交损失函数:最小化 ∣ ∣ W T W − I ∣ ∣ ||W^T W - I|| ∣∣WTW−I∣∣,其中W是投影矩阵,I是单位矩阵
-
2.中心损失(Center Loss):为每个类维护一个中心点,迫使同类样本靠近其类中心
-
3.乘积量化(Product Quantization):将连续空间离散化为正交的子空间组合,建立一组正交基向量作为代码本: z = Σ ( c i ∗ b i ) z = Σ (c_i * b_i) z=Σ(ci∗bi), 其中 b i {b_i} bi是正交基, c i c_i ci是编码系数。 ∣ ∣ W T W − I ∣ ∣ ||W^T W - I|| ∣∣WTW−I∣∣等价于 W W W 的列向量是标准正交基。
此外,[132]采用了两个变分自编码器(VAE)模型,分别从视觉空间和语义空间中学习跨模态潜在特征。设计了交叉对齐和分布对齐策略,以匹配来自不同空间的特征。
3.2 生成式方法
即:学习一个模型,基于可见类的样本和两种类的语义表示,生成不可见类的图像或视觉特征。生成不可见类样本,可以将GZSL问题转换为传统的监督学习问题,来训练DL模型(图6b)。基于Single homogeneous process(单一同质过程),不同于传统方法的分阶段处理(如先学习可见类,再通过语义嵌入迁移到未见类)导致的偏差,用统一的建模流程(如GAN等从未见类的语义描述生成视觉特征或联合映射)将可见类和未见类的分类任务整合到同一视觉空间中,从而避免偏差。
生成的数据样本需要满足两个相互冲突的条件: (i)与真实样本的语义相关,以及(ii)具有鉴别性,以便分类算法易于对测试样本进行分类。 生成对抗网络 (GANs)[136]和 变分自编码器 (VAEs)[137]是生成模型中的两个重要成员,它们在GZSL中取得了良好的结果
3.2.1 生成对抗网络
GANs利用类条件密度 p ( x ∣ y ) p(x|y) p(x∣y) 和类先验概率 p ( y ) p (y) p(y),计算样本的联合分布 p ( y , x ) p(y,x) p(y,x)来生成新样本。例如MNIST数据集, 若 y y y 代表数字“7”,那么 p ( x ∣ y ) p(x∣y) p(x∣y)描述了所有可能的“7”的图像分布。GANs由一个使用语义属性 A A A和随机均匀或高斯噪声 z ∈ Z z∈Z z∈Z来生成视觉特征 x ~ ∈ X \tilde{x}∈X x~∈X的生成器 G S V : Z × A → X G_{SV}:Z×A→X GSV:Z×A→X,以及一个区分真实视觉特征的鉴别器 D V : X × A → [ 0 , 1 ] D_{V}:X×A→[0,1] DV:X×A→[0,1]组成。
生成器将语义表示 A s A_s As做为条件,为已知类合成数据样本;它也可以通过语义表示 A u A_u Au为未知类生成数据样本。然而,原始的GAN模型是难以训练的,并且在生成的样本中缺乏多样性。此外,模式崩溃是GANs中常见的问题,因为在学习目标中没有明确的约束。为了克服这一问题并稳定训练过程,已经开发了许多具有替代目标函数的GAN模型。Wasserstein GAN(WGAN)[139]使用Wasserstein 距离作为目标函数,减轻了模态崩溃的问题。它在鉴别器上应用了一种剪权的方法,以允许加入Lipschitz约束。 改进的WGAM模型[Improved training of wasserstein GANs]通过利用梯度惩罚而不是剪重来减少WGAN的负面影响。

Xian et al. [138]设计了一个具有分类损失的条件WGAN模型,以合成看不见的类的视觉特征,称为f-clswgan(图10)。为了合成相关特征,通过最小化以下损失函数,将语义特征集成到生成器和鉴别器中:

3.2.2 变分自编码器
3.2.3 GANs 和 VAEs的结合
四、转导式广义零样本学习(TRANSDUCTIVE GZSL METHODS)
转导式广义零样本学习,可以从没见过的类中考虑未标记的数据样本来缓解投影域的移位问题。访问未标记的数据,允许模型知道没见过类的分布,从而学习一个判别的投影函数。它还允许通过使用基于生成的方法来合成看不见的类的相关视觉特征。由于发表的数量有限,我们将基于转换的GZSL方法分为两类:
4.1 基于Embedding方法
4.2 基于生成式方法
五、应用
5.1 计算机视觉
图像分类: 是GZSL方法中最流行的应用之一。目的是从见过和没见过的类别的图像进行分类。在这方面,已经引入了一些标准的基准数据集(请见补充数据)。
目标检测: 不仅识别物体,还致力于定位物体。多年来,许多基于CNN的模型被开发出来以识别已知类别。然而,收集具有真实边界框标注的足够样本并不容易扩展,因此出现了新的方法。目前,零样本检测的进步使得传统物体检测模型能够检测到之前未学过的类别。文献中报道的方法包括从单标签[92][183][184][185][186][187]到多标签[188][189],多种视图(CT和X光)[190]以及舌部结构识别[191]的一般类别检测。此外,GZSL已被应用于分割已知和未知类别[192],[193],从大规模数据集[194],[195]检索图像以及执行图像标注[52]
视频处理: 从视频中识别人类动作和手势是计算机视觉中最具有挑战性的任务之一,因为存在许多未在已知动作类别中出现的动作。在这方面,基于GZSL的框架被用于识别单标签[25],[95],[166],[196]和多标签[197]的人类动作。例如,CLASTER [196]是一种使用强化学习的聚类方法。在[197]中,提出了一种使用JLRE(联合潜在排序嵌入)的多标签ZSL(MZSL)框架。该框架在语义嵌入和联合潜在视觉空间中测量测试视频片段的各种动作标签的关系得分。此外,[198],[199],[200].引入了一种使用音频、视频和文本的多模态框架。
5.2 自然语言处理
NLP [201][202]和文本分析[203]是机器学习和深度学习方法的两个重要应用领域。在这方面,基于GZSL的框架已经被开发用于不同的NLP应用程序,如单标签[104][158]、多标签[114][204]以及噪声文本描述[53][54]。Wang等人[104]提出了一种基于语义嵌入和分类关系的方法,利用知识图的优势,在语义嵌入机制的基础上,为学习有意义的分类器提供监督
GZSL在多标签文本分类中的应用,在生成文本数据的潜在特征方面发挥着关键作用。Song等人[204]在一项关于国际疾病分类(ICD)的研究中提出了一种新的GZSL模型,用于识别各种疾病的诊断分类代码。该模型提高了对未见过的ICD代码的预测能力,同时不损害其对已见过的ICD代码的性能。另一方面,对于多标签ZSL,Huy和Elhamifar [115]训练了所有应用模型以处理已见过的标签,然后在未见过的标签上进行测试;而对于多标签GZSL,他们则在已见过和未见过的标签上测试了所有模型。为此,设计了一种新的共享多注意力机制,并引入了一种新颖的损失函数,以预测包含多个未见过类别的图像的所有标签。
该处使用的url网络请求的数据。
总结
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ x ^ \hat{x} x^ x ~ \tilde{x} x~ ϵ \epsilon ϵ
ϕ \phi ϕ