目录

前言
在多次爬取豆瓣网站的过程中,发现豆瓣的反爬虫机制在不同情况下的表现。当请求没有携带 Cookie 时,如果某个 IP 地址在短时间内进行高并发的请求,该 IP 很快就会被封禁。然而,豆瓣对于 IP 封禁的处理方式是,当 IP 被封禁后,通过登录豆瓣网站重新验证账户即可解封该 IP,恢复正常访问。
在携带 Cookie 的情况下,当某个 IP 请求频繁时,豆瓣的反爬虫机制会选择封禁 Cookie,而不是封禁 IP。意味着只要更换账号或退出当前登录状态,新的 Cookie 就可以用来继续访问网站,而 IP 地址不会受到影响。因此,通过这种方式,爬虫仍然可以继续访问网站,避免了因为频繁请求而被永久封禁的问题。
但是这种问题始终对于我们爬数据造成了困扰,程序比较繁琐,如果使用代理ip来解决,那么就迎刃而解了。
一、动态住宅代理
动态住宅代理是从分布在全球各地的真实用户网络中获取的 IP 地址,通过这些代理,用户可以模仿真实用户的行为进行互联网访问。与静态住宅代理相比,动态住宅代理的 IP 地址是周期性变化的,这意味着每次请求的 IP 地址都会有所不同,因此更加隐蔽并有效防止被网站封禁。主要有以下特点:
-
IP 地址动态变化
-
使用的是普通家庭用户的 IP 地址,这些 IP 地址通常难以被检测为代理流量。
-
爬虫进行高频率的数据抓取。
-
适合绕过 CAPTCHA 和机器人检测
-
动态住宅代理池中的 IP 地址来自世界各地
二、爬取豆瓣电影排行榜
目标网站:https://movie.douban.com/top250
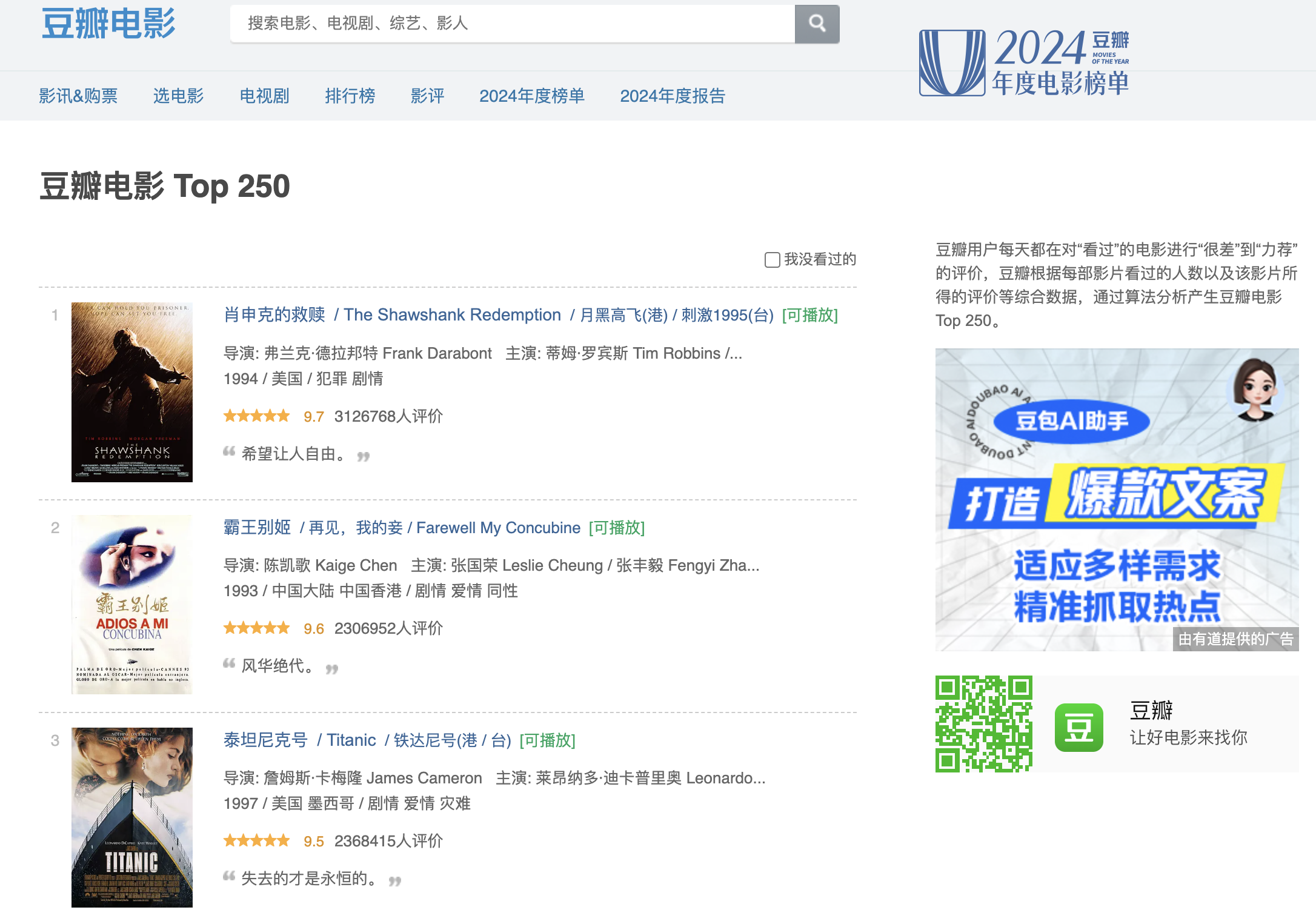
目标数据主要包含title、star、pic,示例如下:
{
"title": "隐藏人物 / Hidden Figures",
"star": "8.9",
"pic": "https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2374067318.jpg"
}
1、选择爬取工具
动态住宅代理的独特性在于其底层网络控制能力,如动态IP隐匿轮换、地理级精准定位和真人行为模拟,依托真实住宅IP网络及智能路由技术实现。我通过搜索引擎询问AI,比较了市场上的住宅代理工具,发现Bright Data住宅代理可穿透复杂反爬机制,保障高频请求下的持续匿名访问与数据可靠性,按流量进行计费,并且性价比非常高!因此选择了Bright Data住宅代理作为本文爬取数据的工具。
2、注册账号
首先打开 官网,点击开始免费试用,链接直达
填写工作邮箱、微信(可选)、手机号,然后点击创建账号
随后打开填写的邮箱,填写邮箱验证码就注册成功啦!如下所示:

3、使用住宅代理
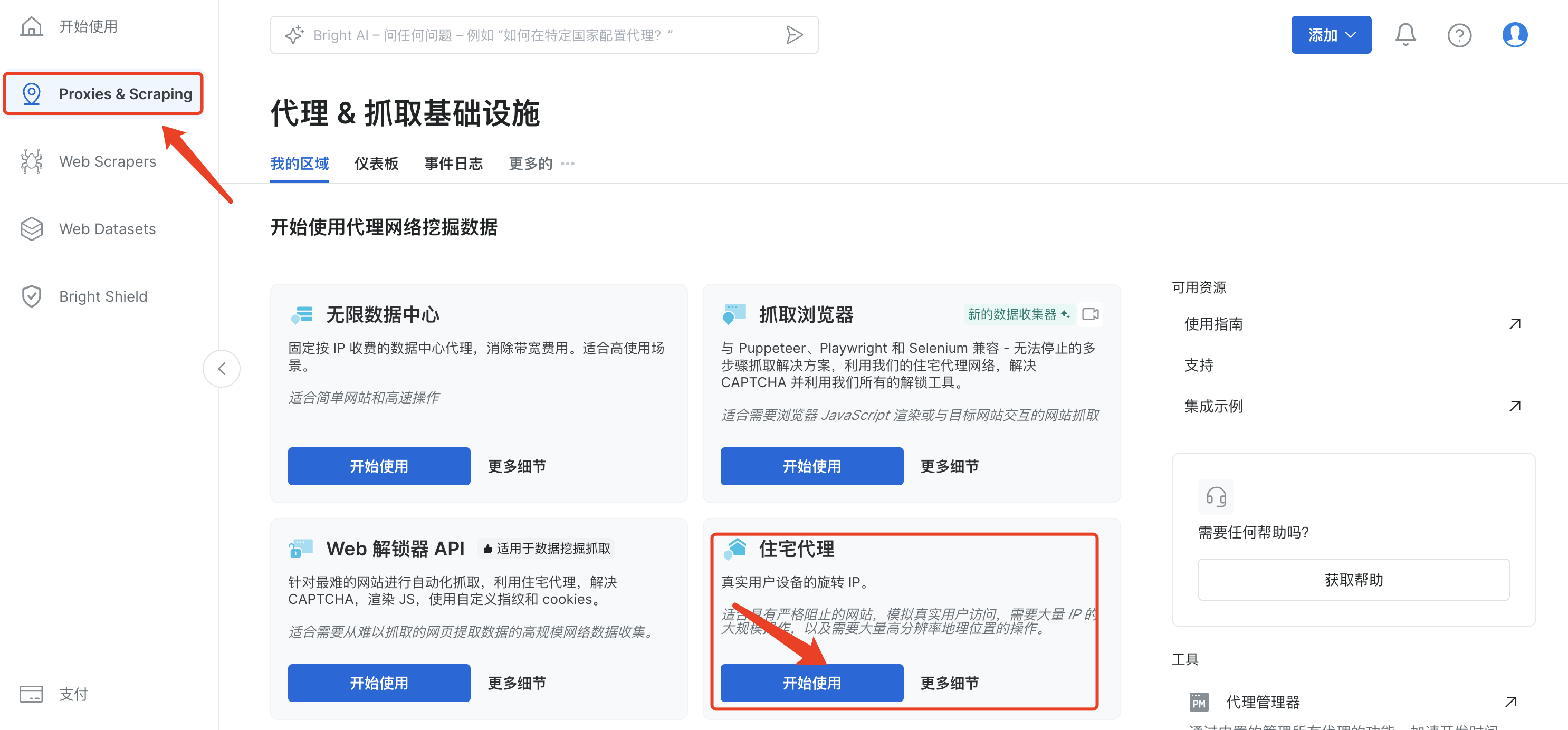
点击左侧菜单中Proxies & Scraping,选择右侧的住宅代理,点击开始使用
(1)基础设置
接下来设置代理,填写区域名称、描述,选择代理描述,还可以添加国家(这里我选择China)
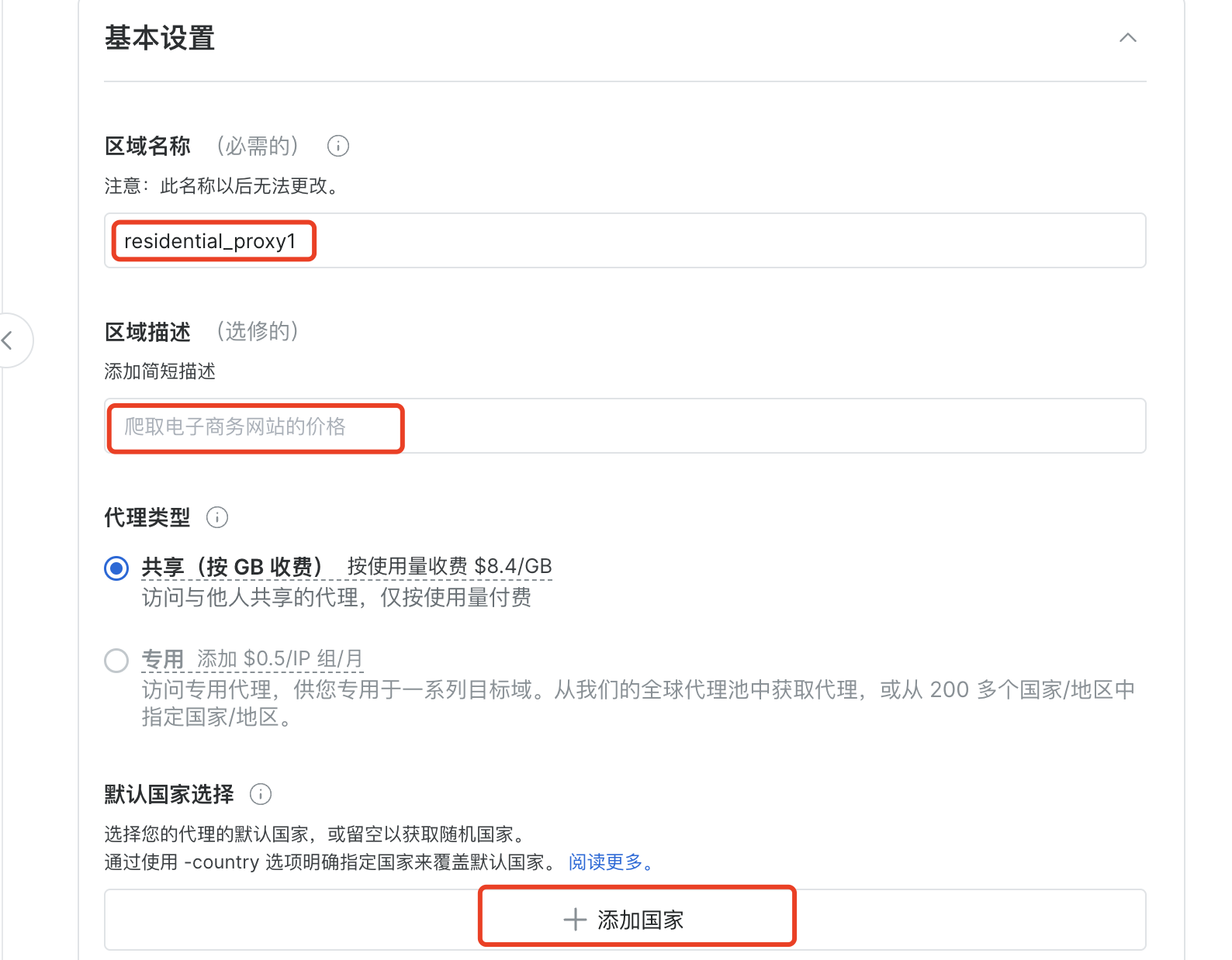
(2)高级设置
选择地理位置目标,离数据源位置越近,爬取越高效

(3)添加住宅代理
设置完成之后,点击添加按钮,
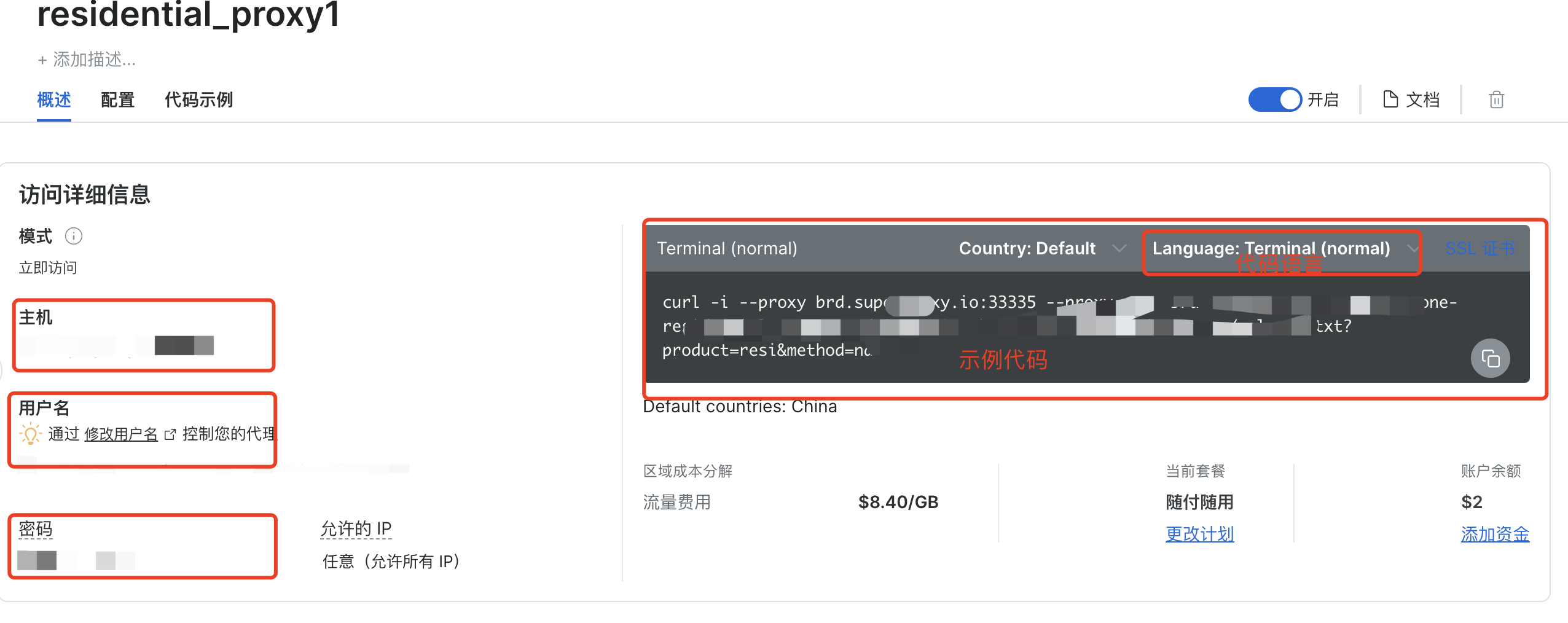
(4)查看住宅代理信息
成功添加之后,可以看到住宅代理的详细信息,包括主机、用户名、密码,
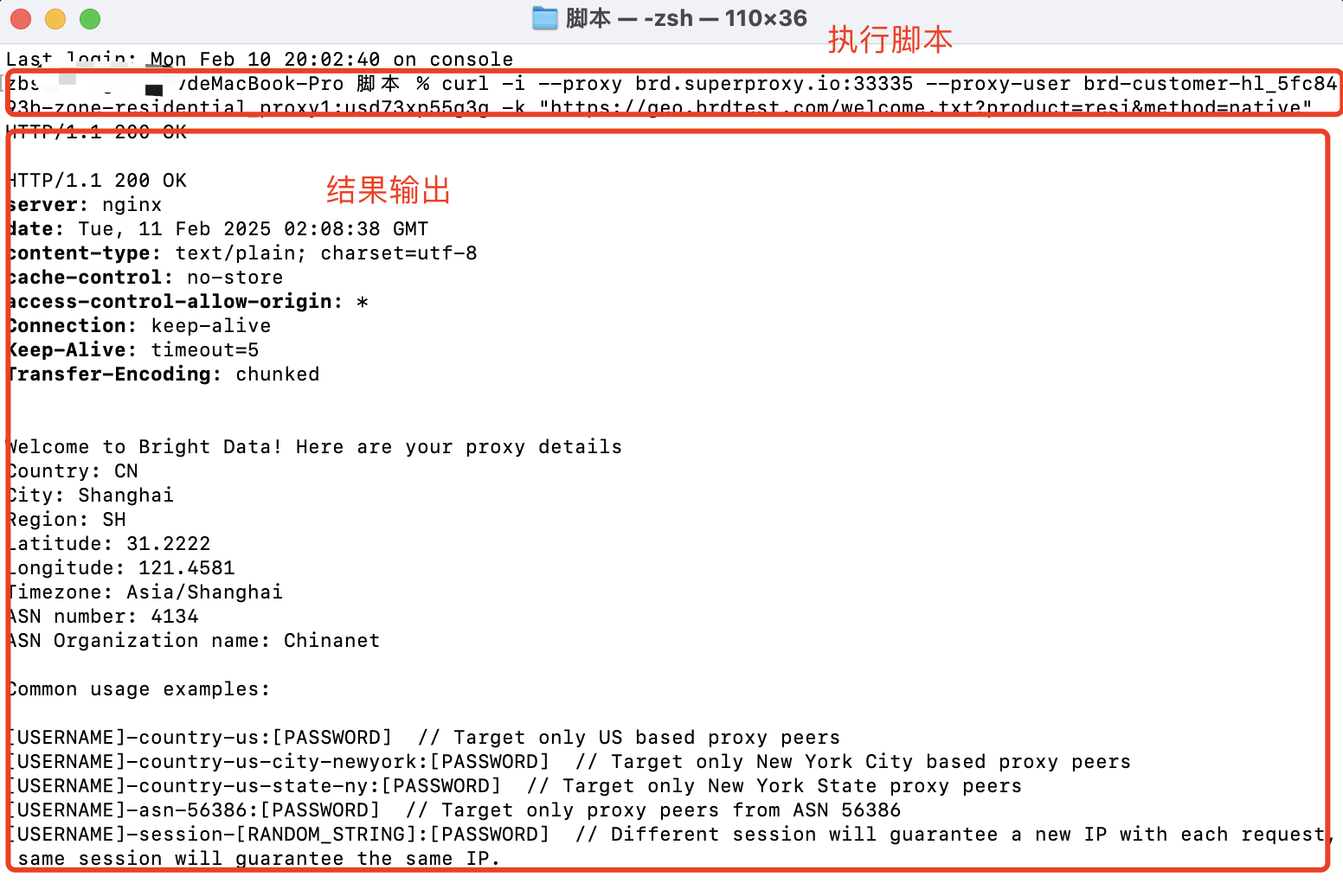
(5)执行脚本示例
curl -i --proxy brd.superproxy.io:33335 --proxy-user brd-customer-hl_5fc8493b-zone-residential_proxy1:usd73xp55g3g -k "https://geo.brdtest.com/welcome.txt?product=resi&method=native"
输出结果如下,说明住宅代理可正常使用!
(6)获取动态ip
点击代码示例,这里我选择Shell脚本先进行测试,可以修改目标网站、国家等等。
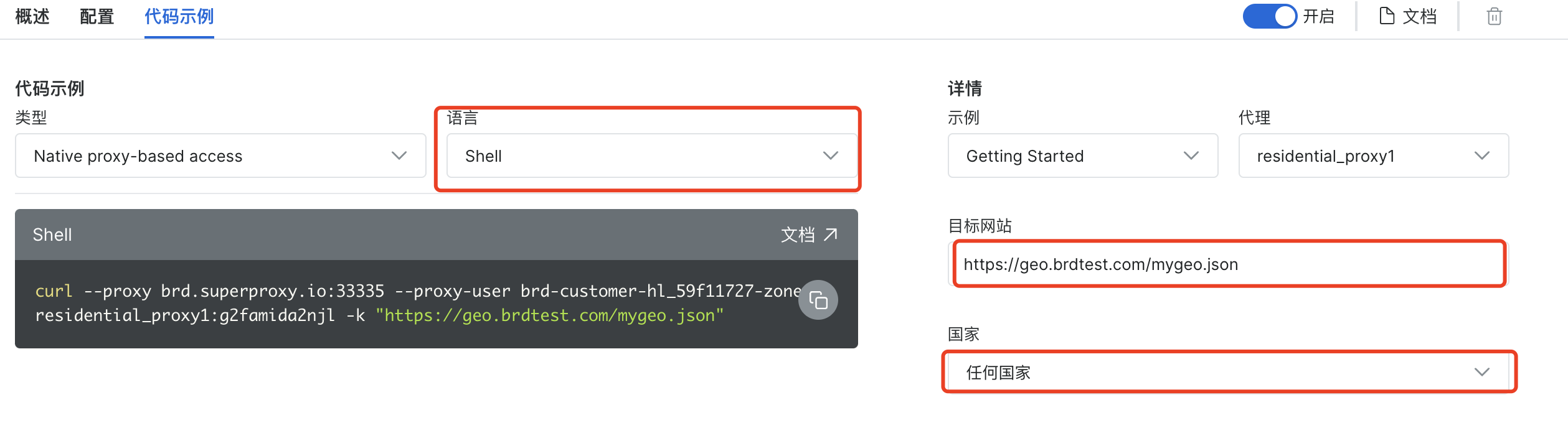
执行上面左侧的脚本,具体如下:
curl --proxy brd.superproxy.io:33335 --proxy-user brd-customer-hl_59f11727-zone-residential_proxy1:g2famida2njl -k "https://geo.brdtest.com/mygeo.json"
最终输出以下结果:
{
"country": "US",
"asn": {
"asnum": 6128,
"org_name": "CABLE-NET-1"
},
"geo": {
"city": "Brooklyn",
"region": "NY",
"region_name": "New York",
"postal_code": "11230",
"latitude": 40.6214,
"longitude": -73.9705,
"tz": "America/New_York",
"lum_city": "brooklyn",
"lum_region": "ny"
}
}
多次请求,你会发现他的返回值是不一样的,也就是进行了动态代理IP切换,比如我再次请求:
{
"country": "PH",
"asn": {
"asnum": 135345,
"org_name": "NewMountainView Satellite Corporation"
},
"geo": {
"city": "San Fernando",
"region": "01",
"region_name": "Ilocos",
"postal_code": "2500",
"latitude": 16.6204,
"longitude": 120.3131,
"tz": "Asia/Manila",
"lum_city": "sanfernando",
"lum_region": "01"
}
}
(7)数据爬取
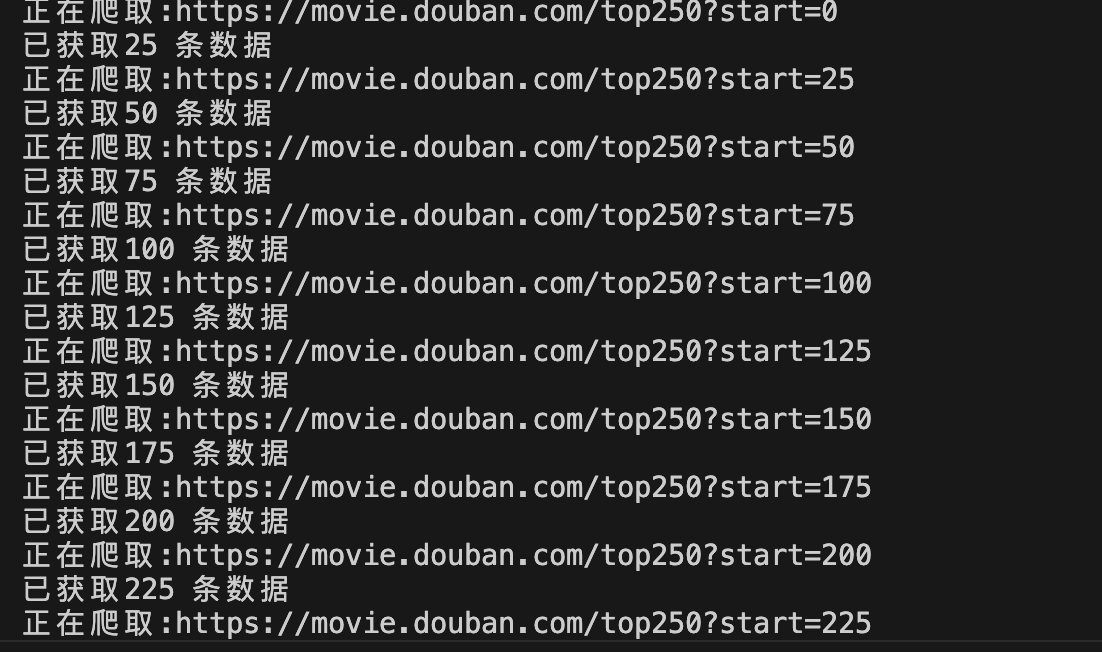
注意:这里数据有分页,一次性拿不到所有数据,所以进行循环请求爬取数据,最终将爬取的数据放置当前的页面中。
const axios = require('axios');
const cheerio = require('cheerio');
const https = require('https');
const fs = require('fs');
// 代理配置(直接使用固定域名)
const proxyConfig = {
host: 'brd.superproxy.io', // 代理服务器固定地址
port: 33335, // 固定端口
auth: {
username: 'brd-customer-hl_5fc8493b-zone-residential_proxy3', // 替换你的用户名
password: 'kgetm1lzyu48' // 替换你的密码
}
};
// 创建带代理的axios实例
const proxyClient = axios.create({
httpsAgent: new https.Agent({
rejectUnauthorized: false, // 跳过SSL验证
proxy: proxyConfig // 应用代理配置
}),
timeout: 15000, // 设置超时时间
headers: {
// 添加常用请求头
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9'
}
});
// 带延迟的爬取函数
async function fetchWithDelay(url, delay = 2000) {
return new Promise(resolve => {
setTimeout(async () => {
try {
const response = await proxyClient.get(url);
resolve(response.data);
} catch (err) {
console.error(`请求失败:${
err.message}`);
resolve(null);
}
}, delay);
});
}
// 主爬虫函数
async function crawlDoubanTop250() {
const results = []; for (let start = 0; start < 250; start += 25) {
const url = `https://movie.douban.com/top250?start=${
start}`;
console.log(`正在爬取:${
url}`); const html = await fetchWithDelay(url); if (!html) continue;
const $ = cheerio.load(html);
$('li .item').each(function () {
const title = $('.title', this).text();
const star = $('.info .bd .rating_num', this).text();
const pic = $('.pic img', this).attr('src');
results.push({
title: title,
star: star,
pic: pic,
});
});
console.log(`已获取${
results.length} 条数据`);
}
return results;
}
// 执行爬虫
crawlDoubanTop250()
.then(data => {
console.log(`总共爬取 ${
data.length} 条数据`);
fs.writeFile('./files.json', JSON.stringify(data), function (err) {
if (err) {
console.error('文件保存失败:', err);
} else {
console.log('文件保存成功');
}
});
// 这里可以添加存储逻辑
})
.catch(err => console.error('全局错误:', err));
(8)数据结果
可以看到在控制台中的输出
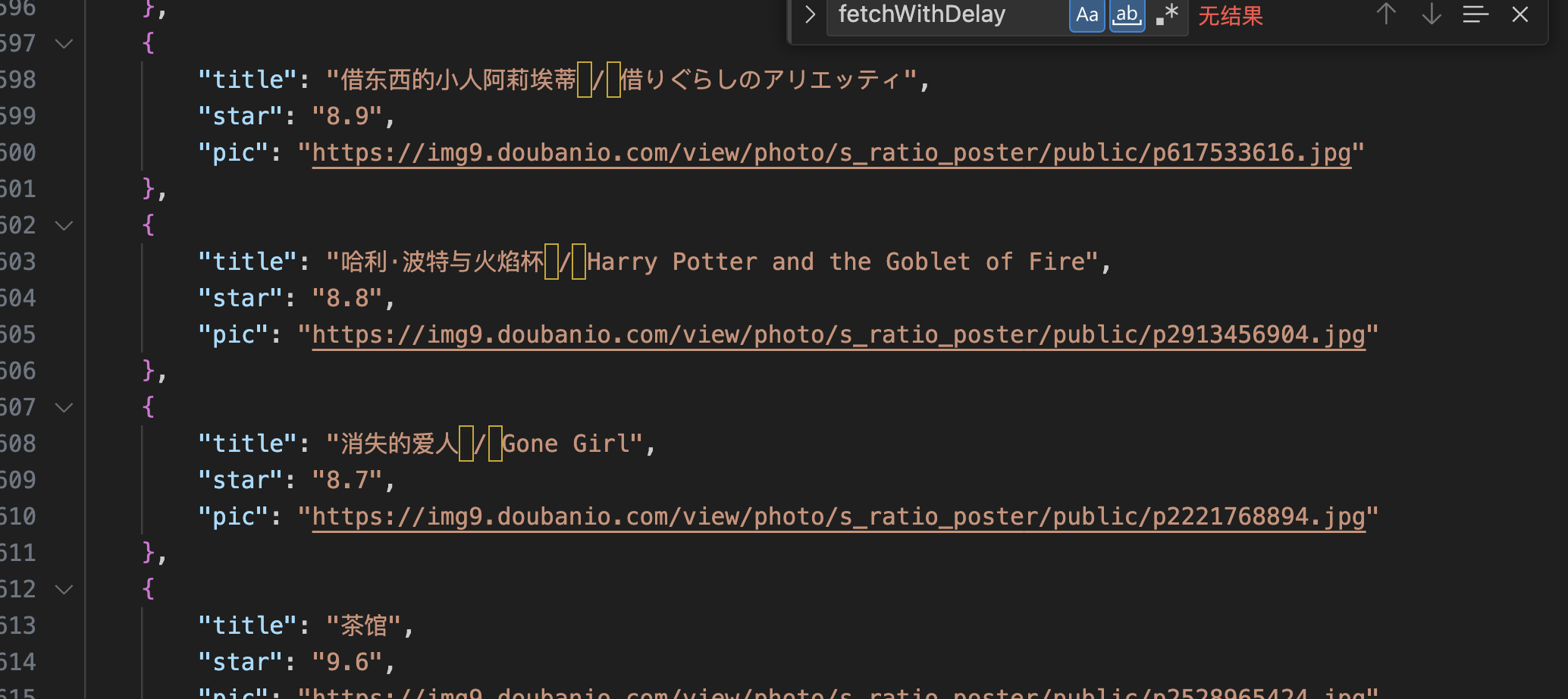
随后在当前目录下,生成了files.json文件。
最终完成了数据爬取。
如果不使用住宅代理的话,刚开始爬取是么问题的,但是随着多次爬取之后,就会发现一直爬取失败,所以使用住宅代理是非常靠谱的

三、使用住宅代理发现的一些亮点
在爬取数据过程中,我们使用 Bright Data住宅代理 发现以下特点:
- ip不仅仅是动态的,并且是真实的,有明确的地理位置的经纬度。相当于真实的ip去请求网页,网页的反爬虫机制阻碍就大大降低了
- 操作非常方便,选择自己的代码语言,可以直接套用,代码零修改的体验非常好
- 响应非常迅速,几乎在零点几秒就返回数据结果
- 安全性非常高,调用过程中没有出现任何的安全问题,因为Bright Data住宅代理来自明确同意参与的用户群,从而确保遵循至高道德标准,追求卓越质量
所以我在爬取过程没有遇到任何爬虫障碍,快速获取到数据,非常高效~,并且目前注册限时5折优惠,且注册送2$,还有限时五折优惠!
最后
在本文案例中,使用 Bright Data住宅代理真的是非常的高效!它支持自定义配置,可以根据需求设置代码语言、地区、网址,提供了基础以及复杂版本的代码示例,非常适合应对不同的数据需求。对开发人员来说几乎零代码修改即可调用和处理数据,动态轮换机制天然对抗反爬虫机制,接近真人访问的网络指纹特征。在抓取数据过程中,效率真的很高,么有出现任何个人信息泄露的状况,并且成本也不是很高,非常推荐使用!