一、背景意义
随着教育技术的快速发展,课堂教学的效果越来越受到重视,学生的注意力是影响学习效果的重要因素。传统的课堂管理方法往往依赖教师的直观观察,难以准确评估每位学生的注意力状态。因此,开发一种能够实时监测学生课堂行为并评估其注意力的系统具有重要的理论与实践意义。通过实现对学生行为的自动检测与分析,可以帮助教师及时了解学生的学习状态,进而采取适当的教学策略,提高课堂教学质量。
二、数据集
2.1数据采集
数据采集是构建学生课堂行为数据集的第一步,主要目标是收集能够反映学生在课堂上不同姿态的图像。具体流程包括:
- 设备选择:选择高清摄像头或高质量手机进行图像采集,以确保图像的清晰度和细节丰富性。这是保证后续分析和模型训练效果的基础。
- 采集环境:选择多种不同的课堂环境进行拍摄,以获取在不同背景和光照条件下的图像数据。自然光和人造光源的结合使用,有助于模拟课堂中的真实情境。
- 样本多样性:在采集时,考虑到不同性别、年龄和行为特征的学生,以确保数据的多样性和代表性。目标是收集到表现出低头、抬头、四周看和使用手机等多种行为的图像。
- 图像数量:确保每个行为类别收集到足够数量的图像以进行有效的训练,通常建议每个类别至少收集300-500张图像,以提高模型的泛化能力。
数据清洗的目的是提升数据集的质量,剔除不符合标准的样本。该过程包括以下步骤:
- 去重处理:检查数据集中是否存在重复的图像,利用图像相似度检测工具进行去重,确保数据集的唯一性和完整性。
- 质量审核:对所有图像进行质量检查,剔除模糊、低分辨率或与目标检测无关的图像。这一环节确保所用数据具有良好的可用性。
- 一致性检查:确保所有图像的格式(如JPEG、PNG)和尺寸一致,建议统一调整图像至640x480像素,以便于后续处理和模型训练。
- 类别数量检查:检查每个类别的图像数量是否均衡,确保模型不会因某一类别的样本过多而导致训练偏倚,影响检测效果。
2.2数据标注
数据标注是制作“学生课堂行为”数据集的重要环节,其主要目标是为每张图像中的行为添加标签。标注过程的主要步骤包括:
- 选择标注工具:使用LabelImg等标注工具进行标注,确保该工具支持导出所需格式的标注文件,适用于目标检测模型的训练。
- 绘制边界框:逐一打开每张图像,使用矩形工具围绕每个目标(低头、抬头、四周看、使用手机)绘制边界框,并为每个框输入相应的类别名称。
- 确保标注一致性:在标注过程中,确保每个绘制的边界框准确包围目标,避免漏标或误标,以提高数据集的准确性。
- 保存标注结果:完成标注后,将每张图像的标注结果保存为指定格式,以便后续模型训练时使用。
- 标注质量审查:对标注结果进行复审,确保每个目标均被准确标注,必要时进行二次标注,以提高标注质量。
使用LabelImg进行“学生课堂行为-抬头、低头-四周看”数据集的标注是一项复杂且耗时的工作。标注人员首先需要启动LabelImg软件,并选择待标注的图像文件夹。接下来,他们逐一打开每张图像,使用矩形工具围绕每个行为进行标注,并为每个框输入相应的类别名称(如低头、抬头、四周看、手机)。这一过程要求标注人员具备细致的观察力和高度的专注力,以确保每个边界框准确覆盖目标,避免漏标或误标。同时,标注人员还需在不同的图像中保持标注风格的一致性,以提高数据集的质量。完成所有标注后,标注结果需进行复审,以确保数据的准确性和可靠性。
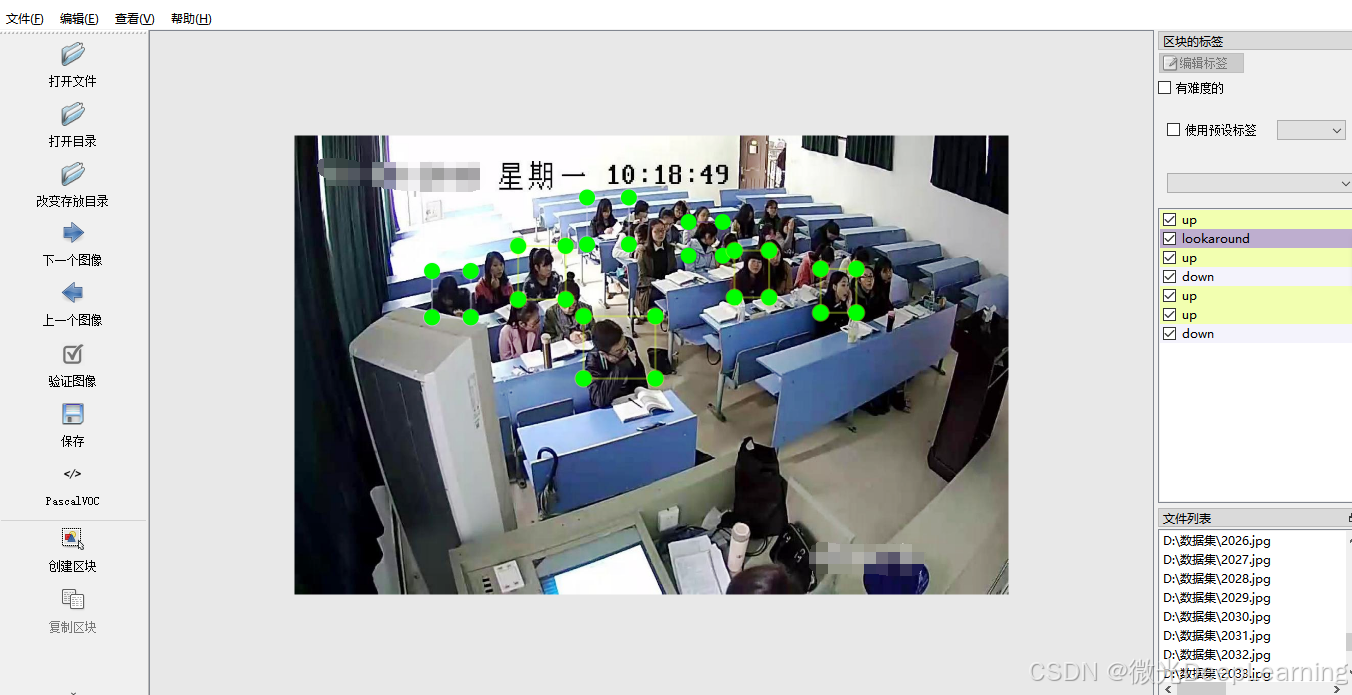
学生课堂行为图片数据集中包含以下几种类别:
- 低头:学生将头部向下的姿态,通常表示专注于课本或手机。
- 四周看:学生环顾四周的行为,可能表示对周围环境的关注。
- 手机:用于检测学生在课堂上使用手机的行为,可能影响学习专注度。
- 抬头:学生将头部抬起的姿态,通常表示注意力集中或对讲课内容的关注。
2.3数据预处理
数据预处理是为模型训练做准备的重要步骤,主要包括以下几个方面:
- 数据增强:通过图像翻转、旋转、缩放和裁剪等方法对原始图像进行增强,以增加数据集的多样性,防止模型过拟合。
- 归一化处理:对图像的像素值进行归一化,将其缩放到[0, 1]或[-1, 1]的范围,以加速模型训练的收敛速度,优化模型的学习效果。
- 划分数据集:将处理后的数据集划分为训练集、验证集和测试集,通常按照70%训练、20%验证、10%测试的比例进行分配,确保每个子集中的样本分布一致。
- 格式转换:将图像和标注数据转换为适合所用深度学习框架的格式,例如YOLO模型需要生成对应的TXT文件,记录每张图像中的目标信息。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
卷积神经网络(CNN)是一种专门设计用于处理图像数据的深度学习模型。其基本结构由多个卷积层、激活层、池化层和全连接层构成。卷积层使用多个可学习的卷积核对输入图像进行卷积操作,从而提取局部特征,生成特征图。激活层通常采用ReLU(线性整流单元)函数,以引入非线性特征,使网络能够学习复杂的函数。池化层则通过降低特征图的尺寸,减少计算复杂度,同时保留主要特征,防止过拟合。最终,全连接层将提取到的特征整合,输出各个类别的预测结果。

CNN在学生课堂行为检测中的优势体现在其强大的特征提取能力和自适应学习能力。由于课堂环境中,学生的姿态变化多端,CNN能够通过层次化的特征学习,自主识别出低头、抬头、四周看和使用手机等多种行为特征。此外,CNN的参数共享机制和局部连接特性使得其在处理复杂背景图像时,能够高效提取特征,并且在训练大规模数据集时表现良好,从而提高模型的准确性和鲁棒性。

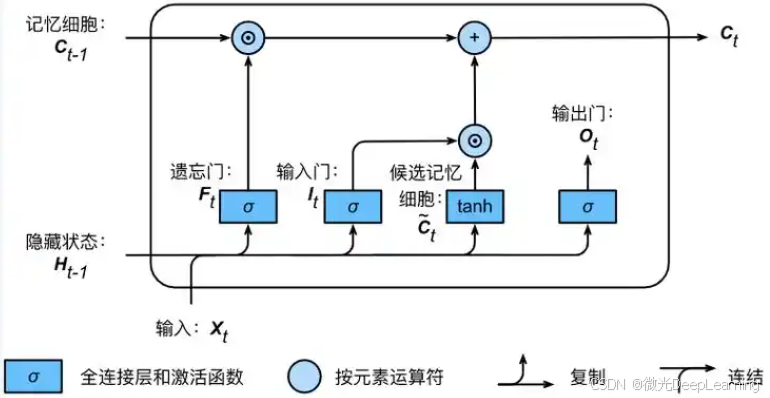
长短期记忆网络(LSTM)是一种特殊的递归神经网络(RNN),设计用于处理和预测时间序列数据。LSTM的核心在于其记忆单元和门控机制,包括输入门、遗忘门和输出门。这些门控制信息的流入、遗忘和输出,能够有效避免传统RNN在长序列数据处理中的梯度消失问题。通过结合时间步长的上下文信息,LSTM能够更好地捕捉学生行为的时间依赖性,识别出学生在课堂上不同时间段的行为变化,从而提升识别的精度。
YOLO是一种基于深度学习的实时目标检测算法,其核心思想是将目标检测问题转化为回归问题,通过单一的神经网络直接预测边界框及其类别概率。这种方法的显著特点在于,它能够在一次前向传播中同时完成目标的定位和分类,因此在处理速度上具有明显优势。YOLO算法首先将输入图像划分为一个网格,然后为每个网格预测多个边界框及其对应的置信度和类别,最终通过非极大值抑制(NMS)来消除多余的框,实现高效的目标检测。
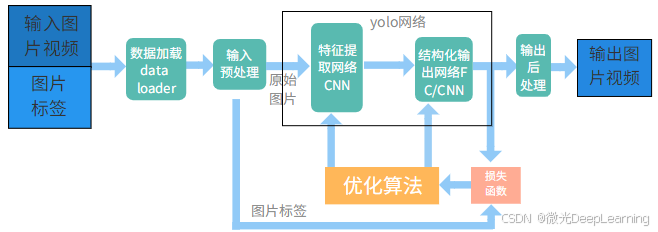
YOLO算法相较于传统的目标检测方法具有多个显著优势。首先,其高效的检测速度使得YOLO能够实现实时目标检测,适用于视频监控、自动驾驶等场景。其次,由于YOLO将目标检测视作一个单一的回归问题,相较于基于区域提议的算法,其计算复杂度大幅降低,显著提高了模型的推理速度。此外,YOLO在全局上下文信息的处理上表现良好,能够在复杂背景中实现较为准确的目标识别,这使得其在实际应用中具有更强的鲁棒性和实用性。
3.2模型训练
1. 数据集预处理
在实施YOLO项目之前,首先需要准备和划分数据集。数据集应包括学生在课堂上不同姿态(低头、抬头、四周看、使用手机)的图像,以确保样本的多样性和代表性。可以通过拍摄或从网络下载获取样本。将数据集随机划分为训练集、验证集和测试集,通常推荐的比例为70%训练、20%验证、10%测试。以下是数据集划分的示例代码:
import os
import random
import shutil
# 定义数据集路径
dataset_path = 'path/to/classroom_behavior_dataset'
images = os.listdir(dataset_path)
# 随机划分数据集
random.shuffle(images)
train_split = int(len(images) * 0.7)
val_split = int(len(images) * 0.9)
train_images = images[:train_split]
val_images = images[train_split:val_split]
test_images = images[val_split:]
# 创建新的目录以存放划分后的数据集
os.makedirs('train', exist_ok=True)
os.makedirs('val', exist_ok=True)
os.makedirs('test', exist_ok=True)
for image in train_images:
shutil.copy(os.path.join(dataset_path, image), 'train/')
for image in val_images:
shutil.copy(os.path.join(dataset_path, image), 'val/')
for image in test_images:
shutil.copy(os.path.join(dataset_path, image), 'test/')
在数据准备完成后,需要对图像进行标注。使用LabelImg等标注工具为每张图像中不同的行为进行标注,通常采用矩形框的方式。标注过程的步骤如下:
- 启动LabelImg,选择需要标注的图像文件夹。
- 逐一打开图像,使用矩形工具绘制边界框,围绕低头、抬头、四周看和使用手机行为进行标注,并为每个框输入相应的类别名称。
- 确保每个行为均被准确标注,避免遗漏。
- 保存标注结果。
2. 模型训练
配置YOLO模型。首先,准备模型的配置文件(如yolov5.cfg),设置网络参数、学习率和批量大小等。创建数据描述文件(如data.yaml),指定训练和验证数据集路径及类别数。例如,data.yaml文件内容如下:
train: train
val: val
nc: 4 # 目标类别数量(低头、抬头、四周看、手机)
names: ['低头', '抬头', '四周看', '手机']
模型配置完成后,可以开始训练YOLO模型。使用命令行运行YOLO训练命令,模型将开始处理训练数据。以下是训练的示例命令:
python train.py --img 640 --batch 16 --epochs 50 --data data.yaml --weights yolov5.weights
在训练过程中,可以根据需要调整学习率和其他超参数。通过命令行参数设置学习率:
python train.py --img 640 --batch 16 --epochs 50 --data data.yaml --weights yolov5.weights --hyp hyp.scratch.yaml
在hyp.scratch.yaml文件中,可以自定义学习率、动量、权重衰减等超参数:
# hyperparameters
lr0: 0.01 # 初始学习率
lrf: 0.1 # 最终学习率
momentum: 0.937 # 动量
weight_decay: 0.0005 # 权重衰减
3. 模型评估
完成训练后,对模型进行测试和评估是检验其性能的关键步骤。使用测试集中的图像,利用训练好的YOLO模型进行行为检测,并生成检测结果进行可视化。以下是测试和可视化的示例代码:
import cv2
import torch
# 加载训练好的模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='runs/train/exp/weights/best.pt')
# 进行检测
img = 'test/test_image.jpg'
results = model(img)
# 可视化检测结果
results.show() # 显示结果
results.save('output/') # 保存结果到指定目录
四、总结
通过自制数据集和深度学习算法构建了一个高效的学生课堂行为检测系统。首先,通过精细的图像采集和标注,为模型训练提供丰富的样本支持。结合卷积神经网络(CNN)与YOLO算法,以提升对学生行为的检测能力。在各个阶段的实施中,通过合理的数据预处理和模型评估,验证了所构建模型的有效性,为教育领域的智能管理提供了可靠的技术保障。