众所周知,做量化的第一步是什么,当然是获取数据拉。可以无论是国内的wind还是国外的路透等金融数据库动辄6位数一年。对于我们这种平民玩家,在赚钱之前还是免费的更香,于是乎笔者凭着自己不多的python技能尝试开发了一个基于python的免费数据源Baostock的自动数据下载程序,没事时候挂在家里的主机上自动下载。话不多说,上代码
开发环境
python3.13
mysql8.4.0
Window11
主要用到的python库
baostock
mysql-connector-python
paramiko
tqdm
SQLAlchemy
开发进度
2024-12-25: 已基本实现沪深两市所有2024年挂牌(包括退市)的股票历史5m级别K线数据下载(单只股票最早数据为2000-01-01)(稳定性尚待测试)
2025-01-06:已基本实现数据自动下载及保存功能(可以选择保存至csv或者mysql中)和简化版本的GUI的界面,自此开始源码将不再文章中更新,有需要的可以自行从文章末尾提供地址自行下载
程序架构
AutoBaoStock.py
主要负责对baostock股票数据下载接口的二次封装,数据初步清洗以及mysql存储功能的实现。文件主要有以下内容:
class AutoBaoStock:
def __init__(self):
bs.login()
self.constring = (f"mysql+pymysql://{
sql_user}:{
sql_pw}@{
sql_host}:"
f"{"3306"}/{"autofinancedata"}")
self.sql = SQL_Connector.MysqlConnector(host=sql_host, user=sql_user, passwd=sql_pw,
auth_plugin="mysql_native_password")
self.myCursor = self.sql.createCursor()
self.myCursor.execute("CREATE DATABASE IF NOT EXISTS autofinancedata ")
AutoBaoStock 类,其构造函数内置了调用MYSQL并创建本程序所需mysql数据库的功能,类中包含四个方法:
get_all_stock_info()
get_all_stock_info()方法是对于baostock查询当日挂牌股票信息方法的二次封装,返回一个包含当日挂牌股票信息的dafaframe
@staticmethod
def get_all_stock_info(date_query):
"""
查询并返回指定日期的所有股票信息。
参数:
date_query (str): 查询的日期,格式为YYYY-MM-DD。
返回:
pandas.DataFrame: 包含股票信息的DataFrame,如果查询失败则抛出异常。
"""
try:
# 调用bs对象的query_all_stock方法查询指定日期的所有股票信息
# 假设bs是一个已经定义好的对象,具有query_all_stock方法,且该方法接受一个名为day的参数
rs = bs.query_all_stock(day=date_query)
# 检查查询是否成功
# 这里假设error_code为'0'表示查询成功,但具体取决于bs对象的query_all_stock方法的实现
if rs.error_code != '0':
# 如果查询失败,则抛出一个自定义异常,该异常包含错误代码和错误信息
# Error_Class.baostock_query_all_stock是一个自定义异常类,它应该已经在其他地方被定义
raise Error_Class.baostock_query_all_stock(f"Query error: code={
rs.error_code}, msg={
rs.error_msg}")
# 初始化一个空列表来存储查询结果
data_list = []
# 循环遍历结果集,直到没有更多数据
while rs.next():
# 获取当前行的数据,并添加到列表中
data_list.append(rs.get_row_data())
# 使用查询到的数据创建一个DataFrame,并指定列名
# 这里假设每行数据包含"code"(股票代码)、"tradeStatus"(交易状态)、"code_name"(股票名称)等字段
result = pd.DataFrame(data_list, columns=["code", "tradeStatus", "code_name"])
# (可选)打印DataFrame以查看结果(在实际应用中,通常不会在这里打印,而是在调用此函数的外部处理结果)
# print(result)
# 返回包含股票信息的DataFrame
return result
get_stock_history()
get_stock_history()方法是对baostock获取指定股票指定时间段内历史K线数据的方法的二次封装,返回一个保存某只股票指定时间段内历史K线数据的dataframe
@staticmethod
def get_stock_history(code, start_date, end_date, frequency, adjustflag):
"""
获取指定股票的历史K线数据。
参数:
code (str): 股票代码。
start_date (str): 开始日期,格式为YYYY-MM-DD。
end_date (str): 结束日期,格式为YYYY-MM-DD。
frequency (str): 数据频率
adjustflag (str): 复权标志
返回:
pd.DataFrame: 包含历史K线数据的DataFrame。
"""
# 调用bs库的query_history_k_data_plus函数获取股票历史K线数据
rs = bs.query_history_k_data_plus(code,
"date,time,code,open,high,low,close,volume,amount,adjustflag",
start_date=start_date, end_date=end_date,
frequency=frequency, adjustflag=adjustflag)
# 检查返回结果是否有错误
if rs.error_code != '0' and rs.error_msg != 'success':
# 如果有错误,打印错误代码和错误信息,并返回空列表
print('query_history_k_data_plus respond error_code:' + rs.error_code)
print('query_history_k_data_plus respond error_msg:' + rs.error_msg)
return []
else:
# 如果没有错误,初始化一个空列表来存储数据
data_list = []
# 循环遍历结果集,直到没有更多数据
while (rs.error_code == '0') & rs.next():
# 获取当前行的数据,并添加到列表中
data_list.append(rs.get_row_data())
# 将数据列表转换为DataFrame,并指定列名
result = pd.DataFrame(data_list,
columns=["date", "time", "code", "open", "high", "low", "close", "volume", "amount",
"adjustflag"])
# 返回包含历史K线数据的DataFrame
return result
def fetch_listed_stock()
def fetch_listed_stock()方法主要实现获取指定时间段内沪深两市所有挂牌(包括退市)股票列表,去重后保存至mysql数据库的功能
def fetch_listed_stock(self, start_date, end_date, store_in_sql=False):
try:
# 获取开始日期和结束日期之间的所有日期列表
date_period = Utility.get_dates_between(start_date, end_date)
# 打印开始获取数据的消息,包括日期范围和是否存储到SQL的指示
print(
"\n开始获取数据从 {} 到 {} 的当日挂牌股票数据,储存开关为:{}".format(start_date, end_date, store_in_sql))
# 初始化一个空的DataFrame来存储整个日期范围内的股票数据
# 这里使用date_period[0]即第一个日期来获取初始的股票信息(可能是为了获取表结构或初始化DataFrame)
# 但注意,如果第一个日期的数据有特殊性或不完整,这种方式可能不合适
stock_list = self.get_all_stock_info(date_period[0])
# 遍历日期范围内的每一个日期
for date in tqdm(date_period, desc="正在下载挂牌股票数据", unit="日期"):
try:
# 获取指定日期的股票信息
daily_stock_info = self.get_all_stock_info(date)
# 检查获取到的股票信息是否为空(即DataFrame是否为空)
# 如果不为空,则将其与已有的stock_list合并,并删除重复的行(基于code_name和code字段)
if not daily_stock_info.empty:
stock_list = pd.concat([stock_list, daily_stock_info]).drop_duplicates(
subset=["code_name", "code"], ignore_index=True)
else:
# 如果为空,则打印警告消息
print(f"警告:日期 {
date} 没有获取到股票数据。")
except Exception as e:
# 如果在获取股票信息时发生异常,则打印错误消息
# 并可以选择在这里继续循环(如当前所做)或根据需要退出循环
# 如果要退出循环,可以使用 break 语句
print(f"在日期 {
date} 获取股票数据时发生错误:{
e}")
break # 当前代码在遇到错误时会退出循环,可以根据需要移除这行来继续循环
time.sleep(0.5)
# 模拟处理时间或网络延迟(可能是为了避免过快地发送请求)
finally:
pass
# 注意:这里没有显示地处理异常结束的情况(例如使用finally块来确保资源的释放)
# 在实际应用中,可能需要添加finally块来处理必要的清理工作
def fetch_stock_history()
def fetch_stock_history()方法主要实现通过读取fetch_listed_stock()生成的table获取沪深两市所有股票(共5000多只)的历史k线数据(目前只实现下载5m频率的K线)
def fetch_stock_history(self, start_date, end_date, interval="5", adjustflag="3", store_in_sql=False):
try:
unique_stock_list = pd.read_sql_query("SELECT * FROM listedstock", self.constring)
except Exception as e:
print(f"读取 listedstock 表时发生错误, 出错方法为:{
inspect.stack()[0].function}")
exit()
stock_list = pd.DataFrame(unique_stock_list[~unique_stock_list["code"].str.startswith("sh.000", "sz.399")])
try:
for i, row in tqdm(stock_list.iterrows(), total=len(stock_list), desc=f"正在获取股票历史数据({
interval}m)",
unit="股票",maxinterval=0.1):
code = row['code']
print(f"当前正在获取 {
code}")
data = self.get_stock_history(code, start_date, end_date, interval, adjustflag)
if store_in_sql:
if len(data) == 0:
print(f"{
code}{
interval}为空")
pass
else:
data.to_sql(name=f"{
code}_{
interval}m", con=self.constring, if_exists='replace', index=False)
time.sleep(0.5)
except Exception as e:
print(f"获取股票历史K线数据时出错: {
e} 出错方法为:{
inspect.stack()[0].function}")
Config.py
用来保存程序中所用到的参数(目前只需要mysql的参数)
sql_host = "你的mysql主机地址"
sql_user = "你的mysql用户名"
sql_pw = "你的mysql账户密码"
ERROR_CLASS.py
用来创建程序中需要用到的自定义Error类 (目前暂时用不到)
SQL_Connector.py
用来创建和保存程序中需要用到的以mysql-connector-python实现的mySQL 交互功能 (SQLAlchemy虽然集成性好 使用方便 但是在直接对mysql的操作上比较笨拙)
class MysqlConnector()
这个类主要是用于在python创建对mysql数据库的链接以供AutoBaoStock.py调用
class MysqlConnector():
def __init__(self, host, user, passwd, auth_plugin):
self.host = host
self.user = user
self.passwd = passwd
self.auth_plugin = auth_plugin
self.connection = mysql.connector.connect(
host=self.host, # 数据库主机地址
user=self.user, # 数据库用户名
passwd=self.passwd, # 数据库密码
auth_plugin=self.auth_plugin # 解决MYSQL 8.0默认加密模式不匹配问题
)
def createCursor(self):
myCursor = self.connection.cursor()
return myCursor
def get_connection(self):
return self.connection
Utility.py
这个文件主要用来创建程序中公用的各种方法
def get_today_timestamp()
用于获取当天的时间字符串 格式为yyyy-mm-dd
def get_today_timestamp():
"""
获取今天的日期字符串。
:return: 今天的日期字符串
"""
return datetime.fromtimestamp(int(time.mktime(datetime.now().timetuple()))).strftime('%Y-%m-%d')
def get_dates_betwee()
用于获取某段时间内以天为单位的字符串列表, 格式为yyyy-mm-dd
def get_dates_between(start_date_str, end_date_str):
"""
获取两个日期之间的所有日期(包括起始日和终止日)。
参数:
start_date_str (str): 起始日期字符串,格式为'YYYY-MM-DD'。
end_date_str (str): 终止日期字符串,格式为'YYYY-MM-DD'。
返回:
list: 包含所有日期的字符串列表。
"""
# 将字符串转换为datetime对象
start_date = datetime.strptime(start_date_str, '%Y-%m-%d')
end_date = datetime.strptime(end_date_str, '%Y-%m-%d')
# 初始化一个空列表来存储日期
date_list = []
# 使用一个循环来获取每一天的日期
current_date = start_date
while current_date <= end_date:
date_list.append(current_date.strftime('%Y-%m-%d')) # 将日期添加到列表中,并格式化为字符串
current_date += timedelta(days=1) # 增加一天
return date_list
下载地址
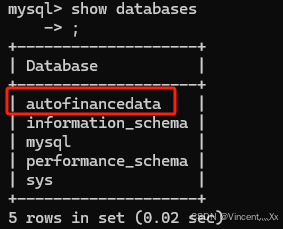
目前的数据库结构
所有数据保存在名为autofinancedata的数据里
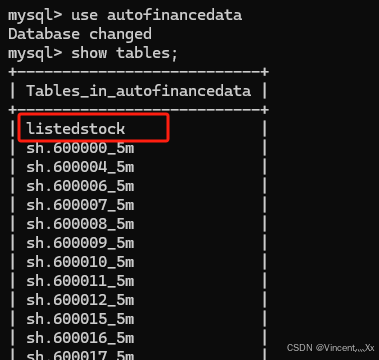
listedstock里保存的是所有挂牌股票的代码和名称,K线数据则保存在下面以股票代码的时间频率命名的表里.
有任何问题欢迎评论区留言.
(顺便说一下问什么不用csv保存, 我试过把数据直接保存在项目文件里,结果解释IDE的索引量爆增导致内存爆炸,最后程序直接崩了)
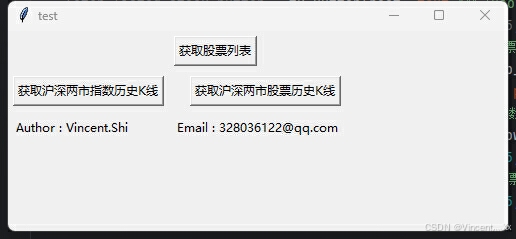
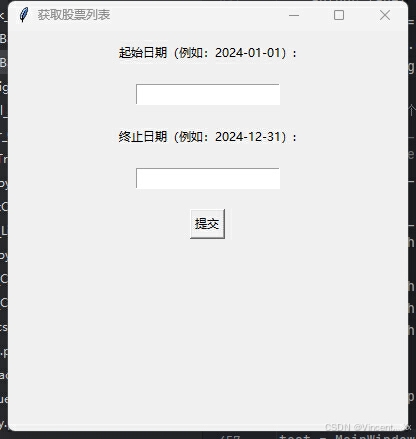
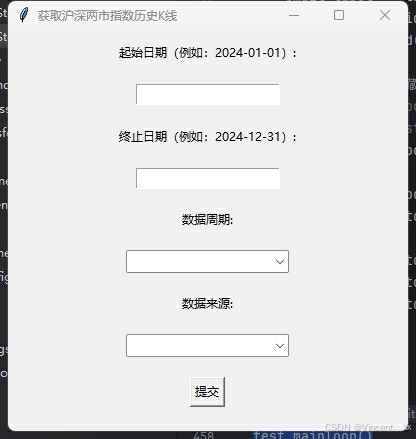
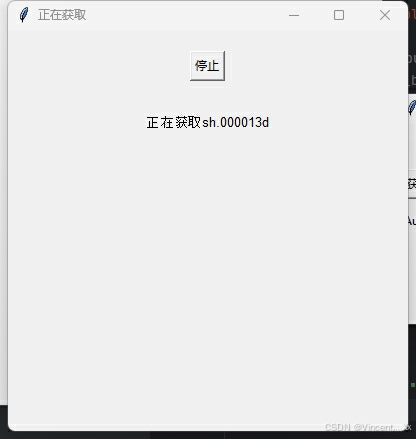
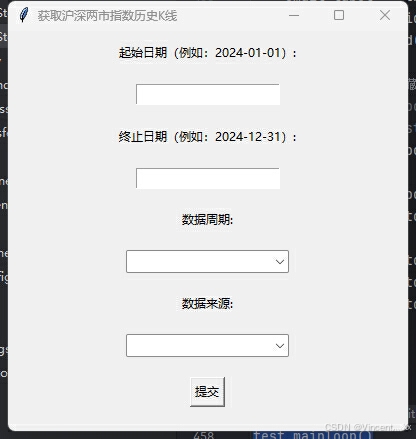
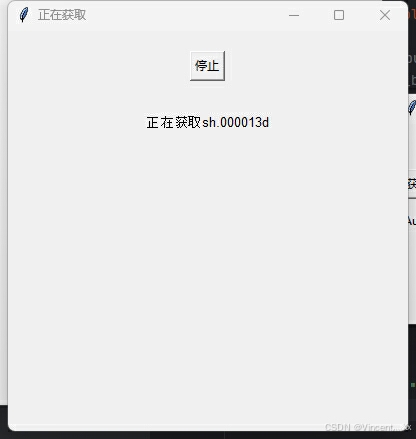
gui界面演示