接上文:COCO目标检测标签转YOLO格式+按需实现标签筛选
将COCO-keypoints的标签文件转成YOLOv8的标签文件。
训练集标签:person_keypoints_train2017.json
测试集标签:person_keypoints_val2017.json
转换的坑:
因为懒,没画关键点的连线。绿点表示可见关键点,红色表示不可见关键点。
1.不是每个人都有关键点,如下图,中间部分的人没标注关键点:

2.存在遮挡关键点,如上图和下图,红色的点(下图甚至标注错误,漏标了腿):

YOLOv8关键点损失函数:
基于欧式距离计算:
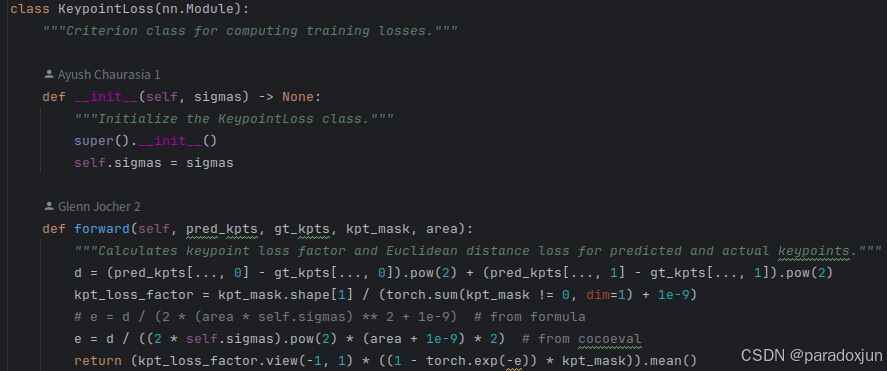
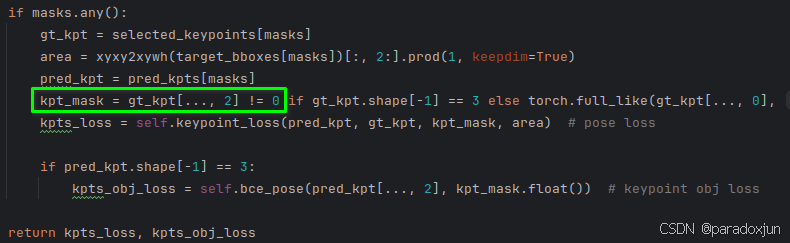
关键点的损失,如绿色框所示,只计算遮挡和可见的关键点的loss:
转换代码:
保存图片列表+生成txt文件。
import json
import os
from collections import defaultdict
"""
# categories[0]:
person_info = {'supercategory': 'person',
'id': 1,
'name': 'person',
'keypoints': ['nose', 'left_eye', 'right_eye', 'left_ear', 'right_ear', 'left_shoulder',
'right_shoulder', 'left_elbow', 'right_elbow', 'left_wrist', 'right_wrist',
'left_hip', 'right_hip', 'left_knee', 'right_knee', 'left_ankle', 'right_ankle'],
'skeleton': [[16, 14], [14, 12], [17, 15], [15, 13], [12, 13], [6, 12], [7, 13], [6, 7], [6, 8], [7, 9],
[8, 10], [9, 11], [2, 3], [1, 2], [1, 3], [2, 4], [3, 5], [4, 6], [5, 7]]}
"""
def tlwh2xywhn(xywh, shape, precision=8):
"""左上+宽高 => 归一化的中心+宽高"""
x, y, w, h = xywh[:4]
x_center = round((x + w / 2.0) / shape[1], precision)
y_center = round((y + h / 2.0) / shape[0], precision)
box_width = round(w / shape[1], precision)
box_height = round(h / shape[0], precision)
return [x_center, y_center, box_width, box_height]
def coco2yolo_keypoints(coco_anno, shape, precision=8):
"""
将一条coco关键点标注转换yolo格式
:param coco_anno: 一条coco标注
:param shape: 图片的(高度,宽度)
:param precision: 保留几位小数
:return: 一条yolo标注
"""
keypoints = coco_anno['keypoints']
bbox = coco_anno['bbox']
yolo_anno = [0] # 只有一个人标签,人的id是1,修改为预测类别0
yolo_anno.extend(tlwh2xywhn(bbox, shape, precision=precision)) # 加入检测框
for i in range(0, len(keypoints), 3):
x = round(keypoints[i] / shape[1], precision)
y = round(keypoints[i + 1] / shape[0], precision)
yolo_anno.extend([x, y, keypoints[i + 2]])
return yolo_anno
def coco2yolo_pose_get_dict(coco_json_path):
"""
读取coco检测标签文件地址,将其转化成字典信息
:param coco_json_path: 标签地址
:return: 字典信息
"""
coco_data = json.loads(open(coco_json_path).read())
image_list = coco_data['images'] # 列表存放字典,需要用到的key{'file_name', 'height', 'width', 'id'}
annotations = coco_data['annotations'] # 列表存放字典,需要用到的key{'bbox': xywh, 'category_id', 'id'}
categories = coco_data['categories'] # 列表存放字典,需要用到的key{'supercategory', 'id', name}
print(f"INFO:读取到的图片总共有: [{len(image_list)}] 张,获取的标签条目总共有: [{len(annotations)}] 个。")
print(f"INFO: 原数据 含有key:{coco_data.keys()}")
print(f"INFO: image 含有key:{image_list[0].keys()}")
print(f"INFO:annotations含有key:{annotations[0].keys()}")
print(f"INFO:categories 含有key:{categories[0].keys()}")
print(f"INFO:")
print(f"INFO:第一个图片条目:{image_list[0]}")
print(f"INFO:第一个标注条目:{annotations[0]}")
print(f"INFO:第一个类别条目:{categories[0]}") # 只有一个类别:人
print(f"INFO:")
# 只有一个人标签,人的id是1,修改为预测类别0
image_info = defaultdict(dict) # 存储图片信息
# 先遍历图片,为所有图片建立一个字典条目,用于储存信息
for image in image_list:
# 获取图片基本信息:标识,名字,大小
image_id = image['id'] # coco_data['images']的'id'对应coco_data['annotations']的'image_id'
file_name = image['file_name']
shape = (image['height'], image['width']) # (高度,宽度)
image_info[image_id]['file_name'] = file_name # 一张图片的文件名
image_info[image_id]['shape'] = shape # 一张图片的形状
image_info[image_id]['yolo_data'] = [] # 一张图片的yolo格式数据
image_info[image_id]['valid'] = True # 一张图是否有用,原数据有‘iscrowd’属性,表示覆盖,去除改类图片
# 然后遍历标注信息,因为一张图片可能有多个标注条目信息,所以需要用哈希映射到对应图片
for anno in annotations:
if anno['num_keypoints'] < 1:
continue
image_id = anno['image_id'] # 图片id
is_crowd = anno['iscrowd'] # 是否有类别覆盖
anno_yolo = coco2yolo_keypoints(anno, image_info[image_id]['shape'])
image_info[image_id]['yolo_data'].append(anno_yolo)
image_info[image_id]['valid'] = image_info[image_id]['valid'] and not is_crowd
print(f"INFO:提取数据成功,获取的第一条数据:{image_info[image_list[0]['id']]}")
return image_info
def save_yolo_labels(image_info, output_dir, image_root, txt_path):
"""
将字典信息里的yolo坐标保存到指定文件夹下
:param image_info: 字典信息
:param output_dir: 保存路径
:param image_root: 图片根路径
:param txt_path: 保存图片路径的txt的保存路径
:return:
"""
if not os.path.exists(output_dir):
os.makedirs(output_dir)
i = 0 # 标注框个数
file_list = [] # 文件列表
# 遍历每张图片的信息
for image_id, info in image_info.items():
if not info['yolo_data'] or not info['valid']: # 关键点标注为空或者存在覆盖,就判定为无效
# print(f"{info['file_name']}: 标注为空or存在覆盖,跳过。")
continue
file_name = info['file_name']
yolo_data = info['yolo_data']
txt_file_path = os.path.join(output_dir, f"{os.path.splitext(file_name)[0]}.txt") # 构建输出文件路径
file_list.append(os.path.join(image_root, file_name))
with open(txt_file_path, 'w') as f: # 写入YOLO格式数据到TXT文件
for data in yolo_data:
line = ' '.join(map(str, data)) # 将列表中的数据转换成字符串并写入文件
f.write(line + '\n')
i += 1
print(f"INFO:成功将YOLO标签保存到目录:{output_dir},共{i}个标注。")
# 生成包含所有图片路径的文件
with open(txt_path, 'w') as f:
for file_path in file_list:
f.write(file_path + '\n')
print(f"INFO:所有文件路径已保存到:{txt_path}")
if __name__ == '__main__':
json_path = r'./COCO2017/annotations_trainval2017/person_keypoints_val2017.json'
image_info_all = coco2yolo_pose_get_dict(json_path)
save_path = r'./COCO2017/pose_ren/labels/val2017'
txt_path = r'./COCO2017/val2017_pose.txt'
save_yolo_labels(image_info_all, save_path, './images/val2017', txt_path)可视化代码:
显示检测结果和关键点结果。
import os
import random
import cv2
import time
colors = [(255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 0), (255, 0, 255), (0, 255, 255)]
skeleton = [[16, 14], [14, 12], [17, 15], [15, 13], [12, 13], [6, 12], [7, 13], [6, 7], [6, 8], [7, 9], [8, 10],
[9, 11], [2, 3], [1, 2], [1, 3], [2, 4], [3, 5], [4, 6], [5, 7]]
keypoints = ['nose', 'left_eye', 'right_eye', 'left_ear', 'right_ear', 'left_shoulder', 'right_shoulder', 'left_elbow',
'right_elbow', 'left_wrist', 'right_wrist', 'left_hip', 'right_hip', 'left_knee', 'right_knee',
'left_ankle', 'right_ankle']
def load_labels(label_path):
with open(label_path, 'r') as file:
lines = file.readlines()
labels = []
for line in lines:
parts = line.strip().split()
label = int(parts[0])
bbox = list(map(float, parts[1:]))
labels.append((label, bbox))
return labels
def draw_keypoints(image, keypoints, height, width, color=((0, 255, 0), (0, 0, 255))):
for i in range(0, len(keypoints), 3):
x = keypoints[i] * width
y = keypoints[i + 1] * height
v = int(keypoints[i + 2])
if x > 0 or y > 0: # 忽略无效点
cv2.circle(image, (int(x), int(y)), 3, color[v % 2], -1)
def draw_boxes(image, labels, label_map, colors):
height, width, _ = image.shape
for label, bbox in labels:
x_center, y_center, w, h = bbox[:4]
x_center, y_center, w, h = x_center * width, y_center * height, w * width, h * height
x1, y1 = int(x_center - w / 2), int(y_center - h / 2)
x2, y2 = int(x_center + w / 2), int(y_center + h / 2)
color = colors[label % len(colors)]
cv2.rectangle(image, (x1, y1), (x2, y2), color, 1)
cv2.putText(image, str(label_map[label]), (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 1)
draw_keypoints(image, bbox[4:], height, width)
def show_image(image_path, label_path, label_map, colors):
print(image_path)
image = cv2.imread(image_path)
if os.path.exists(label_path):
labels = load_labels(label_path)
draw_boxes(image, labels, label_map, colors)
cv2.imshow('YOLO Dataset', image)
def visualize_yolo_dataset(images_path, labels_path, label_map, n, auto=False, interval=1.0, seed=None):
"""
根据图片和标签显示带检测框的图片。按‘q’退出显示。
:param images_path: 图片路径
:param labels_path: 标签路径
:param label_map: 将标签值映射为标签名
:param n: 显示的图片数
:param auto: False按任意非‘q’跳到下一张;True自动播放
:param interval: 自动播放的时间间隔
:param seed: 显示随机顺序的随机种子
:return:
"""
image_files = os.listdir(images_path)
# 设置随机种子
if seed is not None:
random.seed(seed)
else:
random.seed(time.time())
random.shuffle(image_files)
idx = 0
while idx < min(n, len(image_files)):
image_file = image_files[idx]
image_path = os.path.join(images_path, image_file)
label_path = os.path.join(labels_path, os.path.splitext(image_file)[0] + '.txt')
show_image(image_path, label_path, label_map, colors)
if auto:
interval_ms = int(interval * 1000)
key = cv2.waitKey(interval_ms) & 0xFF # Wait for interval seconds
else:
key = cv2.waitKey(0) & 0xFF # Wait for a key press
if key == ord('q'):
break
idx += 1
cv2.destroyAllWindows()
if __name__ == '__main__':
# 示例标签映射字典
# label_map = {
# 0: 'ycj',
# 1: 'kx',
# 2: 'kx_dk',
# 3: 'money',
# 4: 'zbm',
# }
label_map = {k: k for k in range(80)}
# 数据集路径
dataset_path = f'./COCO2017/pose_ren'
images_path = os.path.join(dataset_path, 'images/val2017')
labels_path = os.path.join(dataset_path, 'labels/val2017')
visualize_yolo_dataset(images_path, labels_path, label_map, n=1e6, auto=False, interval=2.5, seed=2024)
生成的可视化结果:

