目录
本节总结了在数据分析领域中,需要掌握的一些SQL基本知识,具体内容见以下目录:
基础语句
SQL 运行原理(运行顺序)
- from--where--group by--having--order by--limit--select
- 执行from语句从数据库中调取复制一份表格
- 执行where语句在复制的表格中筛选出符合条件的数据行
- 执行group by语句依据指定字段对筛选后的数据分区,将依据的字段去重分组,相当于Excel建立了一个数据透视表,添加了行标签
- 执行having语句筛选满足条件的分组
- 执行order by语句对筛选后的数据进行排序
- 执行limit语句对排序后的数据限制显示的行
- 执行select语句,提取最后要显示的字段
select……from
小tips: 单行代码不需要加分号,只有运行多段代码才需要用分号来分割开
#起别名时所有的as都可省略 ,后面的可简写,直接空格+别名即可
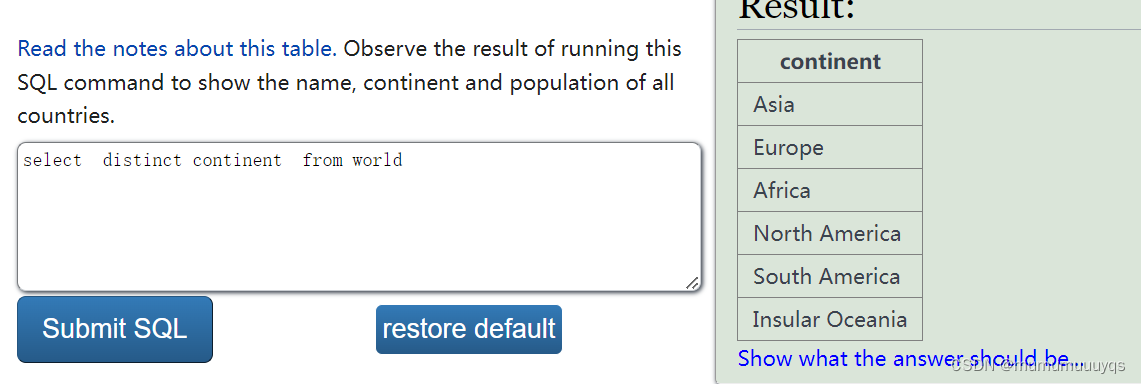
select name as 国家名,continent 大洲,population 人口 from worlddistinct 去重
显示多个字段时,distinct无法对单一字段去重,只能对这几个字段组成的行中重复的数据去重,所以select的本质是加在select后,而不是字段前
where
注意区分字符串的null和空值<null>,两者在where中的判断是不同的 。
前者是字符串,用="null'判断,后者用is null来判断
数值直接跟,若是字符串,文本需要用英文单引号('字符串')包裹
模糊查询like:%用来匹配多个字符(可以是零个或多个字符),_仅能用来匹配单个字符
like后的表达式要用英语单引号包裹,毕竟是字符串
between……and……包含两者边界值,若不想包含,可以再and加一个条件,如and !=666
order by
默认asc 升序(可省略),降序desc
#按照学科,获奖者姓名排序,其中要求诺贝尔化学奖和物理学奖排在最后
SELECT winner, subject
FROM nobel
WHERE yr=1984
ORDER BY subject IN ('physics','chemistry'), subject,winner
#解释:因为将in部分句子放在order by 句子,其值返回1,其他不满足该条件的返回0,按照升序排列的话,1就在0后面limit
limit [位置偏移量,]行数 限制查询结果集显示的行数
limit子句是可选项,行数是子句中的必选参数,参数位置偏移量是可选参数
#查询面积排名前三的国家
#limit n 返回前n条数据,因此可以通过order by和limit子句来达成查询面积前三的需求
select name
from world
order by area desc
limit 3
# limit x,n意味从x+1行开始返回n行
# 查询人口数第4到第7的国家和人口
select name
from world
order by population desc
limit 3,4
聚合函数&group by
使用了group by子句,就相当于对原有数据进行了切分,后续select的查询就是基于切分后的分组计算。
其就类似Excel的数据透视表,group by后面的语句就是透视表的行,select 后的查询,就是列
#查询2013至2015年每年每个科目的获奖人数,结果按年份从大到小,人数从大到小排序
select year,subject,count(winner) 获奖人数
from nobel
where year between 2013 and 2015
group by yaer,subject
order by year desc,count(winner) desc注意:group by 子句比select子句先运行。因此,使用group by 子句时,select 只能使用聚合函数和group by 引用过的字段,否则会报错 。select的作用就相当于确定哪些字段展现,以及在后面增添一些聚合字段
having
having是基于聚合后的结果进行筛选,where是聚合前筛选
部分常见函数
round函数
- round(x,y)——四舍五入函数
- round函数对x值进行四舍五入,精确到小数点后y位
- y为负值时,保留小数点左边相应的位数为0,不进行四舍五入
- 例如:round(3.15,1)返回3.2,round(14.15,-1)返回10
字符串函数
- concat(s1,s2,...)——连接字符串函数
- concat函数返回连接参数s1、s2等产生的字符串
- 任一参数为null时,则返回null
- 例如:concat('My',' ','SQL')返回My SQL,concat('My',null,'SQL')返回null
- replace(s,s1,s2)——替换函数
- replace函数使用字符串s2代替s中所有的s1
- 例如:replace('MySQLMySQL','SQL','sql')返回MysqlMysql
- left(s,n)、right(s,n)&substring(s,n,len)——截取字符串一部分的函数
- left函数返回字符串s最左边n个字符
- right函数返回字符串s最右边n个字符
- substring函数返回字符串s从第n个字符起取长度为len的子字符串,n也可以为负值,则从倒数第n个字符起取长度为len的子字符串,没有len值则取从第n个字符起到最后一位
- 例如:left('abcdefg',3)返回abc,right('abcdefg',3)返回efg,substring('abcdefg',2,3)返回bcd,substring('abcdefg',-2,3)返回fg,substring('abcdefg',2)返回bcdefg
数据类型转换函数
- cast(x as type)——转换数据类型的函数
- cast函数将一个类型的x值转换为另一个类型的值
- type参数可以填写char(n)、date、time、datetime、decimal等转换为对应的数据类型
日期时间函数
year(date)、month(date),day(date)——获取年月日的函数
date_add(date,interval expr type)&date_sub(date,interval expr type)——对指定起始时间进行加减操作
例如::date_add('2021-08-03 23:59:59',interval 1 second)返回2021-08-04 24:00:00,date_sub('2021-08-03 23:59:59',interval 2 month)返回2021-06-03 23:59:59
datediff(date1,date2)——计算两个日期之间间隔的天数
date_format(date,format)——将日期和时间格式化
条件判断函数
if(expr,v1,v2)
case when
#查询首都和名称,其中首都需是国家名称的扩展
select
capital,name
from world
where capital like concat(name,'%')
and capital != name;

高级语句
窗口函数
每一个窗口函数的运算,就相当于在原有表的基础上新开的一个表,在该窗口中把我需要的数值计算好,over后在匹配回原来的表,这样就不影响原来的表结构
加上窗口函数后的运行顺序:

排序窗口函数
- rank() over() 跳跃式排序 1 1 3 4
- dense_rank()over() 并列连续型排序 1 1 2 3
- row_number()over() 连续性排序 1 2 3 4
举例:
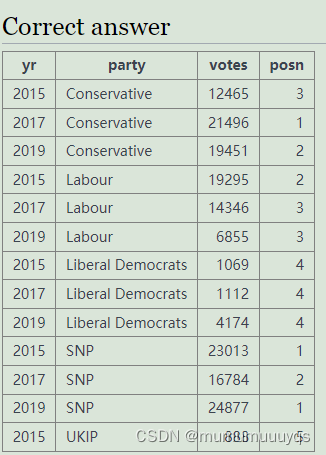
#查询每一年S14000021选区中所有候选人所在的团体(party)和得票数(votes),
并对每一年中的所有候选人根据选票数的高低赋予名次,选票数最高则为1,
第二名则为2,后续以此类推,最后根据团体(party)和年份(yr)排序
select yr,party,votes,rank()over(partition by yr order by votes desc) as posn
from ge
where constituency = 'S14000021'
order by party,yr
偏移分析函数
表连接
三种类型
1. 内连接(默认,即仅有join时)
- select 字段名 from 表名1 inner join 表名2 on 表名1.字段名 = 表名2.字段名
在完全连接的基础上,只要左右表的某一字段存在空值,则剔除
2. 左连接(给左边的表添加数值)
- select 字段名 from 表名1 left join 表名2 on 表名1.字段名 = 表名2.字段名
左边表的值全部都在,即左边是不会出现NULL 的,右边的值若没匹配上,则填NULL
3. 右连接
- select 字段名 from 表名1 right join 表名2 on 表名1.字段名 = 表名2.字段名
例题:
#查询队伍1(team1)的教练是“Fernando Santos”的球队名称(teamname)、比赛日期(mdate)和赛事编号(id)
select mdate,teamname,game.id
from game join eteam on eteam.id = game.team1
where coach = 'Fernando Santos'
#当然,表也与字段类似,可以取别名
子查询
这块比较简单啦
子查询本身就是一段完整的查询语句,然后用括号英文括号()包裹嵌套在主查询语句中,子查询可以多层嵌套。SQL执行顺序,先执行子查询,再执行外面的查询(由内到外)
子查询嵌套在where子句
#查询跟阿尔及尼亚(Argentina)和澳大利亚(Australia)在同一大洲的
所有国家名及其所属大洲,并按照国家名进行排序
select name,continent
from world
where continent in (
select continent
from world
where name in ('Argentina','Australia')
)
order by name
子查询嵌套在from子句
经典::若对窗口函数进行筛选,必须利用子查询再来一次