一、为什么需要MOE?——突破模型规模与训练成本的矛盾
随着深度学习模型参数量的指数级增长(如GPT-3达到1750亿参数),传统密集模型的训练成本呈现平方级攀升。以Transformer为例,其计算复杂度为O(N²d)(N为序列长度,d为特征维度)。当模型规模达到万亿级别时,单次训练的成本已超过千万美元量级。
核心矛盾:
- 模型容量需求:复杂任务需要更大模型捕捉细粒度模式
- 计算资源限制:硬件内存和算力存在物理瓶颈
- 训练效率问题:全参数更新导致计算冗余
MOE的破局点:
通过稀疏激活机制,使模型总参数量达到万亿级别时,每个样本仅激活约50亿参数的子网络。例如Google的GShard模型在2048个TPU上实现6000亿参数规模,而激活参数仅为每样本13亿。
二、MOE架构原理与实现细节
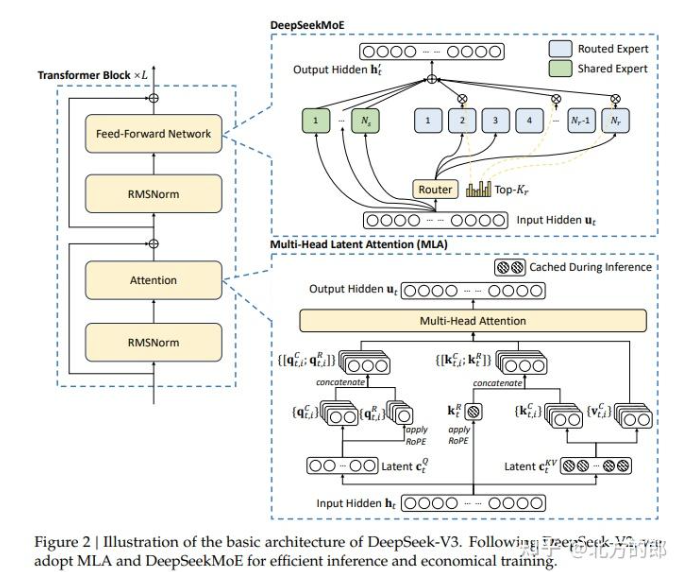
2.1 核心组件解析
• 专家网络(Expert):多个独立的前馈子网络,典型结构为:
class Expert(nn.Module):
def __init__(self, dim, hidden_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Linear(hidden_dim, dim),
nn.Dropout(0.1)
)
def forward(self, x):
return self.net(x)
• 门控网络(Gating Network):动态路由控制器,计算样本到专家的分配权重:
MoE(x)=∑i=1n(G(x)iEi(x))MoE(x)=i=1∑n(G(x)iEi(x))
G(x)=TopK(softmax(Wgx+ϵ))G(x)=TopK(softmax(Wgx+ϵ))
其中TopK操作实现稀疏性(通常k=1或2),ε为噪声项防止坍缩
注:上述第 1 个公式表示了包含 n 个专家的 MoE 层的计算过程。具体来讲,首先对样本 x 进行 门控计算, W 表示权重矩阵;然后,由 Softmax 处理后获得样本 x 被分配到各个 expert 的权 重; 然后,只取前 k (通常取 1 或者 2)个最大权重;最终,整个MoE Layer 的计算结果就是选 中的 k 个专家网络输出的加权和。
2.2 动态路由示例
假设有4个专家处理文本序列:
输入x: [batch=32, seq_len=128, dim=1024]
门控计算:
gate_logits = linear(x) # [32,128,4]
gate_probs = softmax(gate_logits)
topk_indices = top2(gate_probs) # 选择前两个专家
输出整合:
expert1_out = Expert1(x) * mask1
expert2_out = Expert2(x) * mask2
moe_out = expert1_out + expert2_out
2.3 负载均衡优化
为防止专家坍缩(部分专家长期未被激活),引入均衡损失:
Lbalance=λ⋅CV(专家激活次数)Lbalance=λ⋅CV(专家激活次数)
其中CV为变异系数,λ通常取0.01-0.1。在每批训练中约束各专家的使用频率差异。
三、MOE分布式并行策略详解
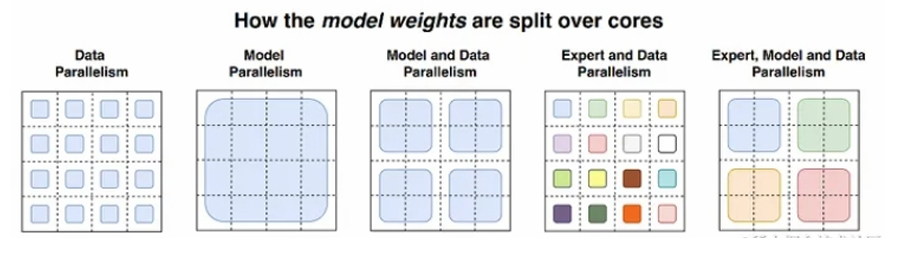
3.1 MOE + 数据并行
在数据并行模式下包含MOE架构,门网络(gate)和专家网络都被复制地放置在各个运算单元上。下图展示了一个 有三个专家的两路数据并行MoE模型进行前向计算的方式。
点击【MoE】MoE与分布式面试常考查看全文