目录
一、通道注意力
1.1、通道注意力是什么
1.1.1、背景前言
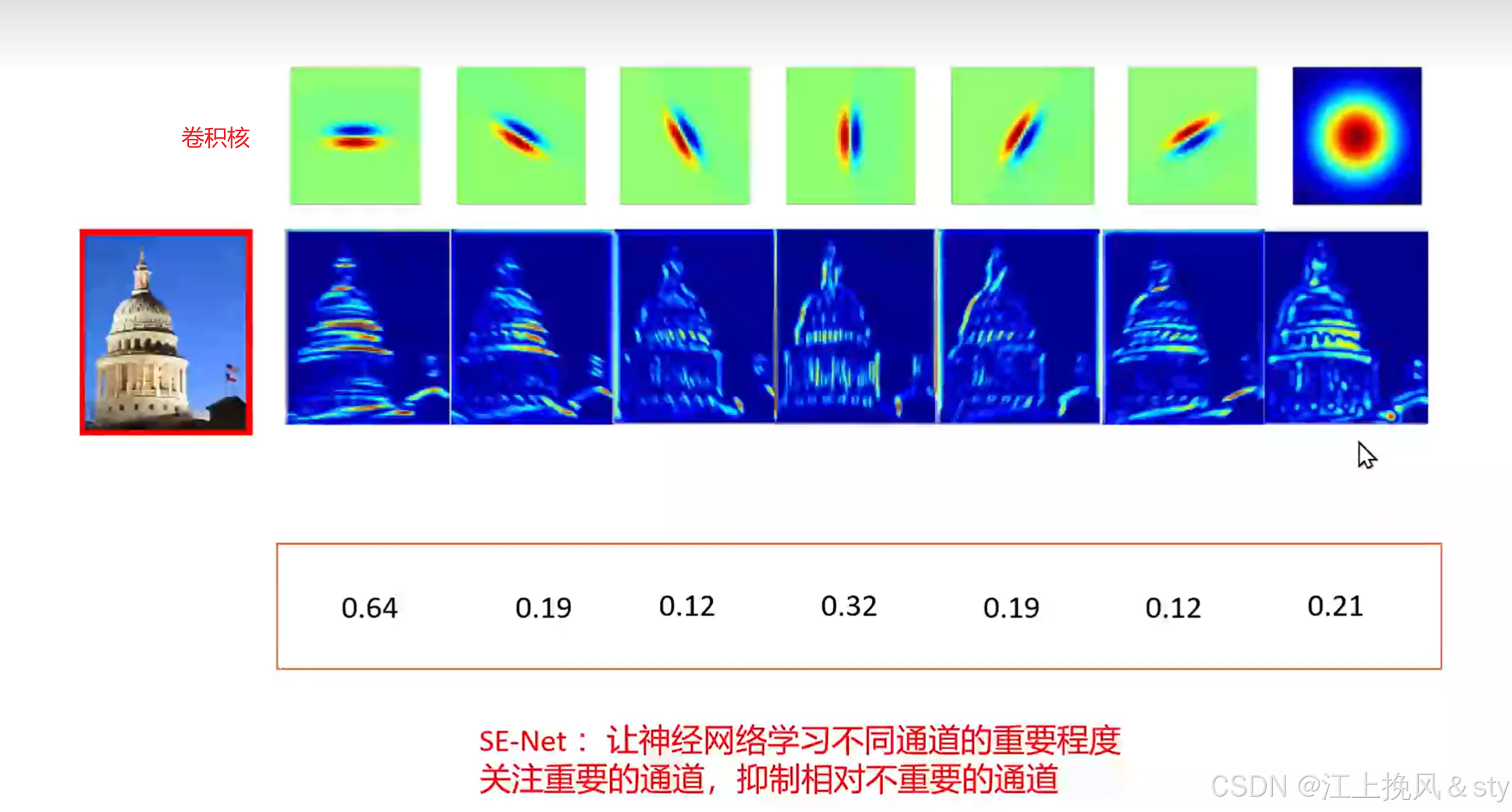
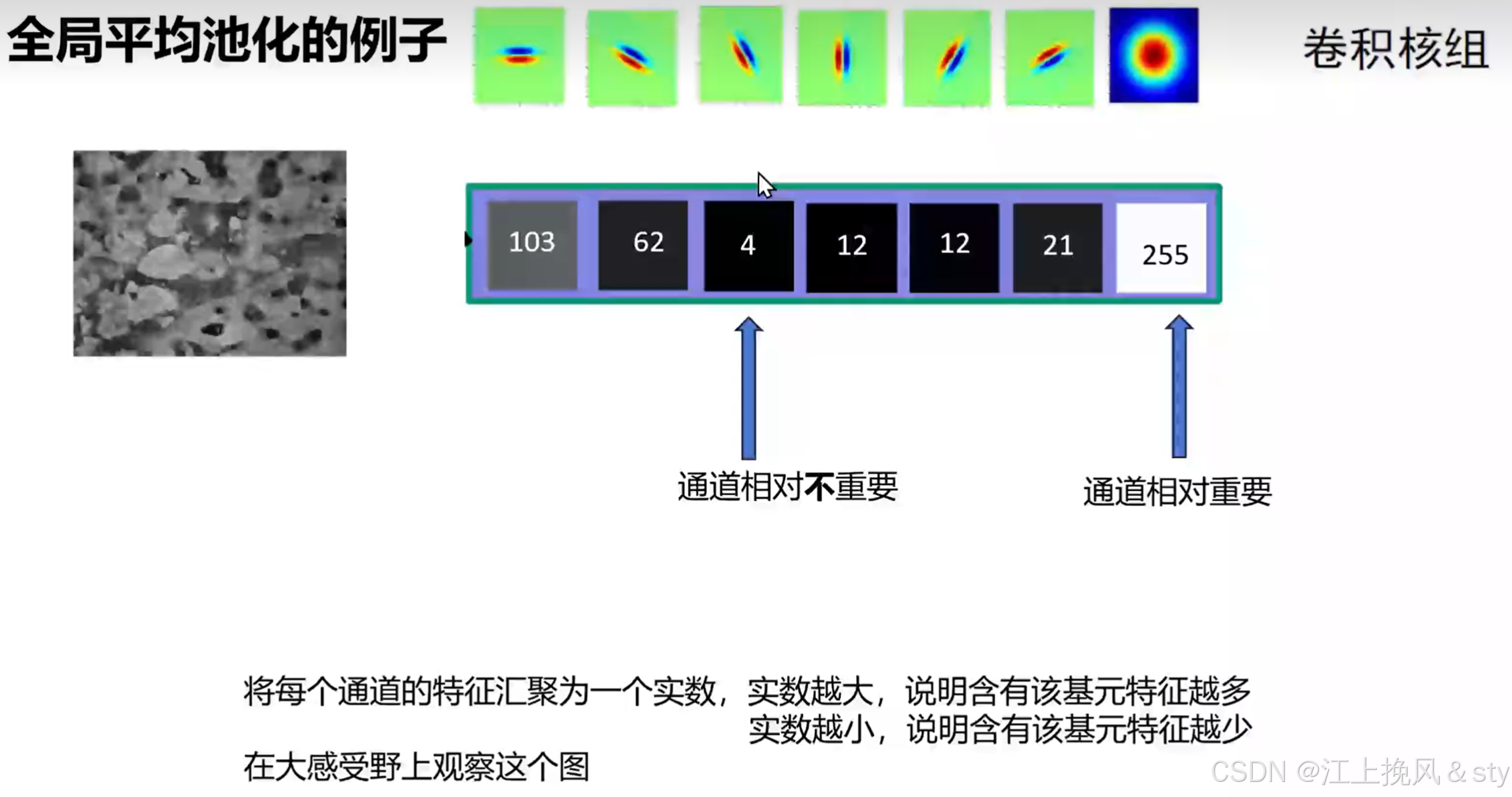
卷积神经网络建立在卷积运算的基础上,它通过在局部感受野内将空间和通道信息融合在一起来提取信息特征。这种方式通常将每一个通道特征赋予相同的重要程度,但是事实上有些通道比较重要,有些通道没这么重要,为此,引入了通道注意力机制(Channel Attention Mechanism, CAM),聚焦特征图中的重要通道,为重要通道分配更高的权重。比如下图的建筑物图像经过不同的卷积核卷积操作后,得到了不同的特征图,从特征图可以看出来,每一个通道特征的重要程度存在差异,为了关注重要的通道,抑制不重要的通道,神经网络需要学习不同通道的重要程度。
1.1.2、目的
-
增强关键特征:通过为每个通道分配不同的权重,通道注意力机制能够强调对任务贡献最大的通道,同时抑制无关或冗余的通道,从而提升模型的整体表现。
-
动态调整特征响应:通道注意力机制通过动态调整每个通道的权重,使得网络能够更加聚焦于关键特征,从而提升整体性能。
1.1.3、解决的问题
-
特征通道的重要性差异:在卷积神经网络中,不同通道的特征对最终任务的贡献度往往不同。通道注意力机制通过学习每个通道的重要性,为每个通道分配不同的权重,从而解决这一问题。
-
提升模型性能:通道注意力机制在多种计算机视觉任务中展现出了显著的优势,包括图像分类、目标检测、图像分割等。通过引入通道注意力机制,这些任务中的神经网络能够更好地聚焦于关键特征,从而提升整体性能。
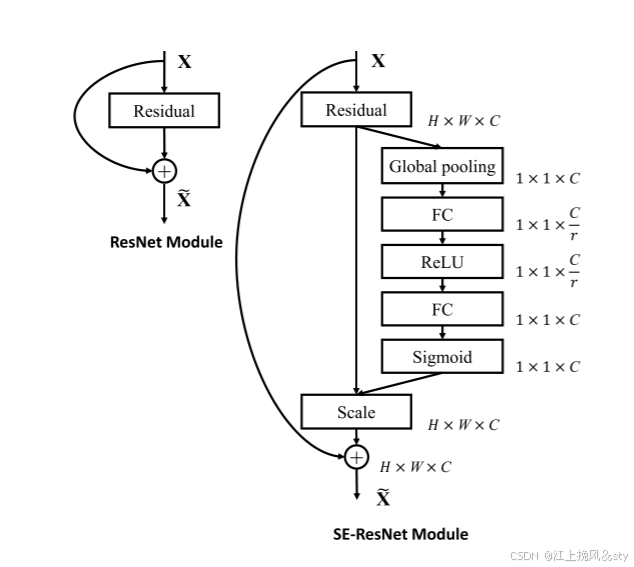
1.2、通道注意力结构图
通道注意力的结构图如下所示:

1.3、通道注意力的计算
通道注意力的处理流程如下:
-
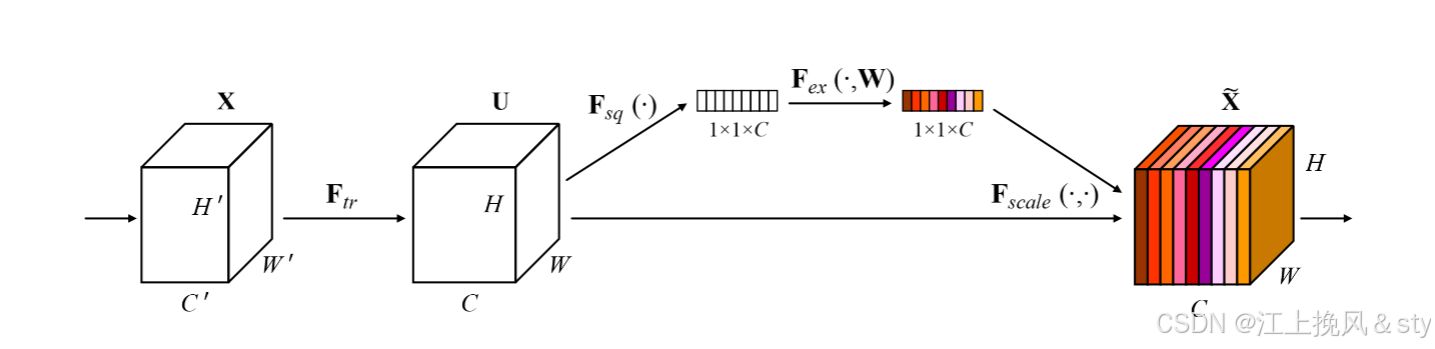
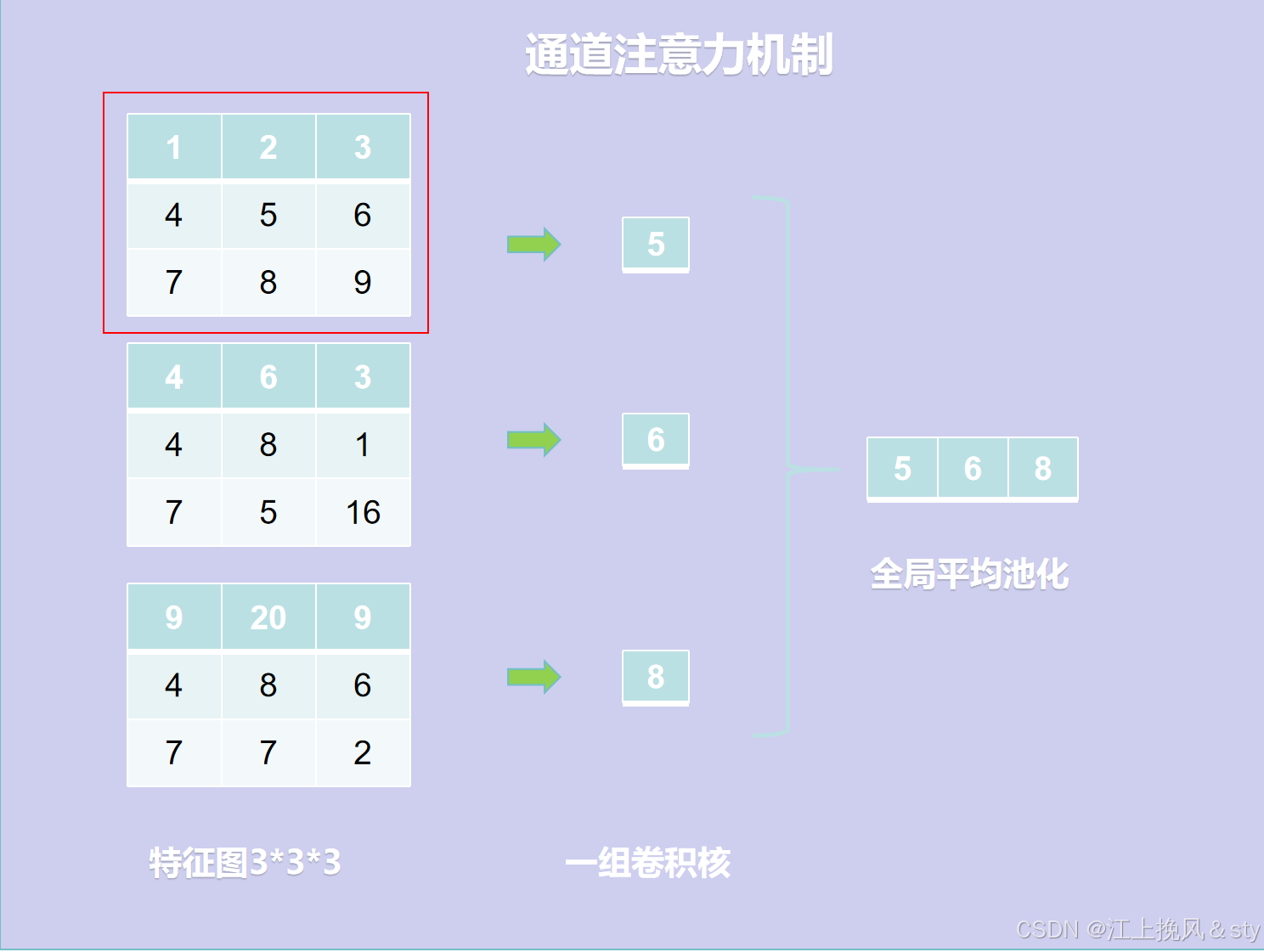
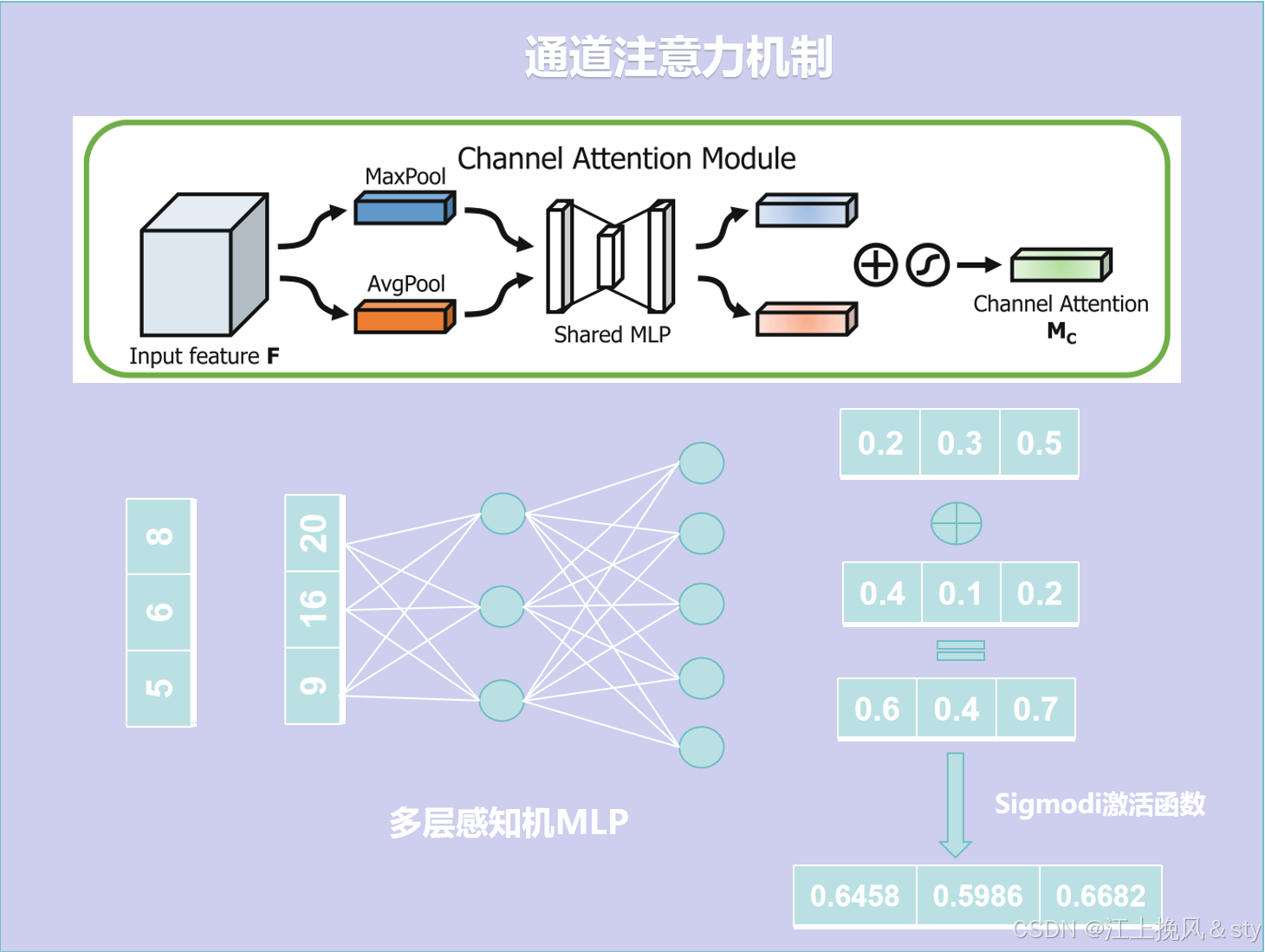
首先,对于尺寸为H*W*C的输入特征图F(图中Input feature F)进行全局最大池化(Maxpool)和全局平均池化(AvgPool),得到两个1*1*C的特征图。这是在空间维度上对特征图进行压缩,减小图像尺寸,便于后面学习通道的特征;(换个方式可以理解为就是现在C张白纸,白纸的高度和宽幅分别为H和W。现在进行全局最大池化,就是对于每一张高为H,宽为W的白纸,从中找到其中最大的数值,因为一共有C张白纸,所以会得到C个数值。全局平均池化,就是对于每一张高为H,宽为W的白纸中的全部元素值相加求平均值,得到对应白纸的平均值,因为一共有C张白纸,所以也会得到C个数值)
-
其次,将全局最大池化和全局平均池化的结果分别送入到一个共享的多层感知机(MLP)中学习,还是得到两个1*1*C的特征图。MLP第一层的神经元数目为C/r,激活函数为Relu,第二层神经元的个数为C,其中经过大量实验证实,r=16实验效果是最好的;
-
最后,将MLP输出的两个1*1*C的特征图进行相加(Add)操作,然后通过一个Sigmoid激活函数进行映射处理,最终得到通道注意力权重矩阵Mc;
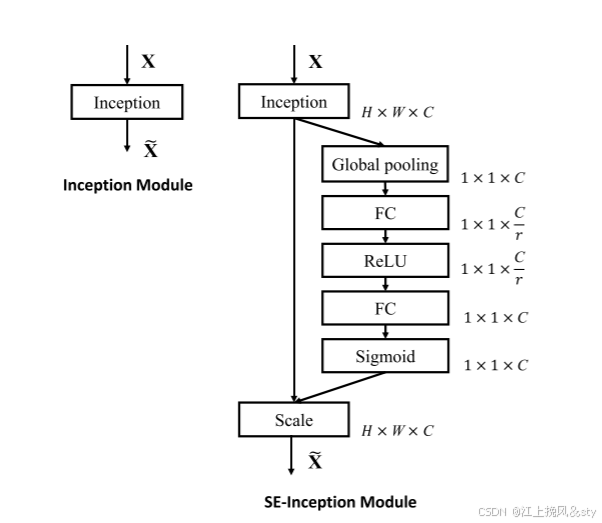
整体流程:
原始输入特征图经过一些列卷积操作后得到特征图
,再将输入特征
(上图是F)与通道注意力权重矩阵Mc相乘得到含有通道权重的特征图
。
其中MLP如下图所示:
计算公式:
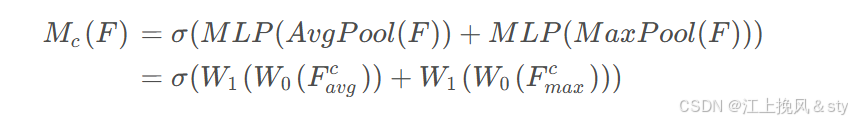
其中,和
分别表示全局平均池化和最大池化特征,通道注意力权重矩阵
。
以下是个人的理解,如有误请指出:
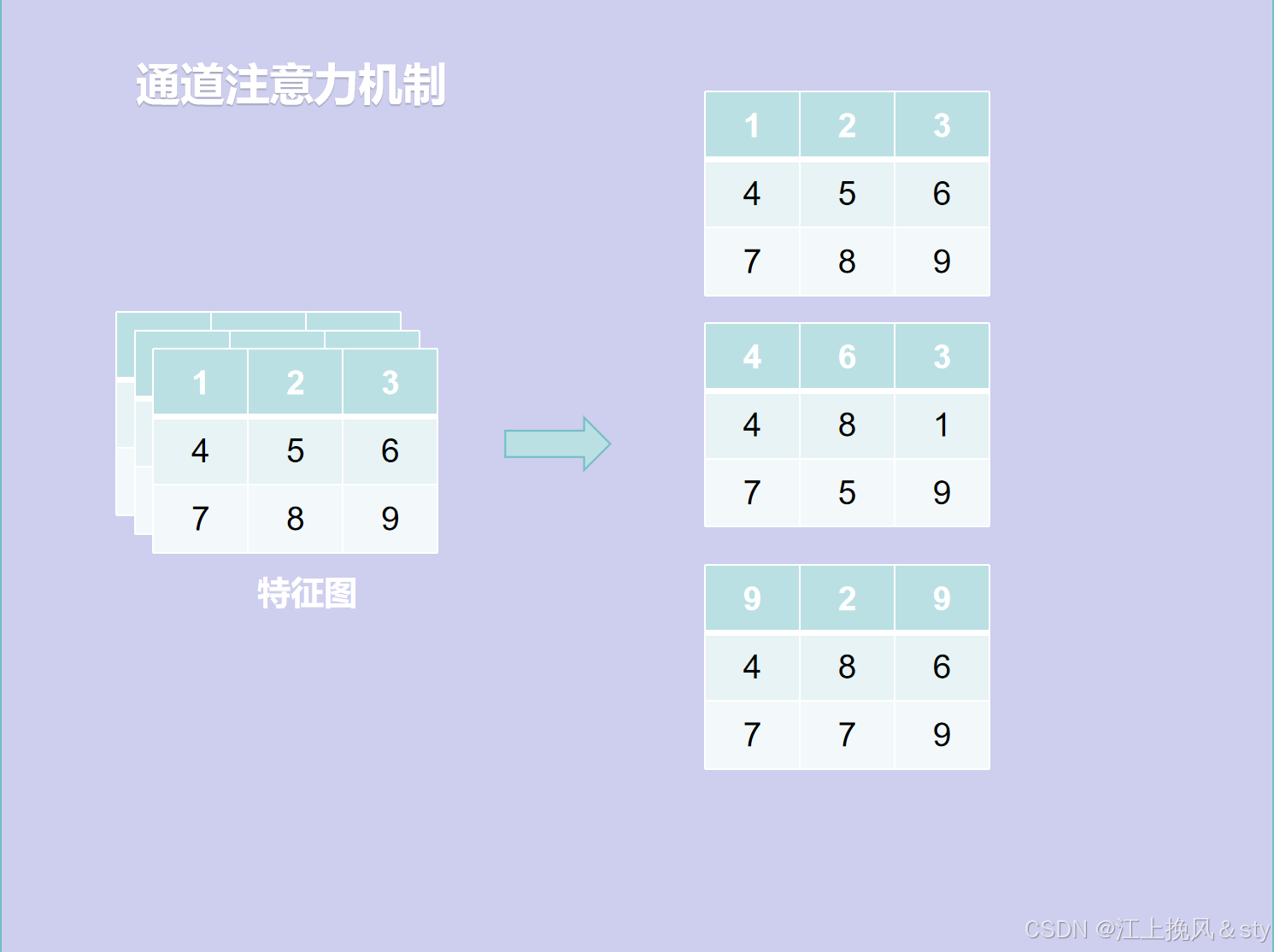
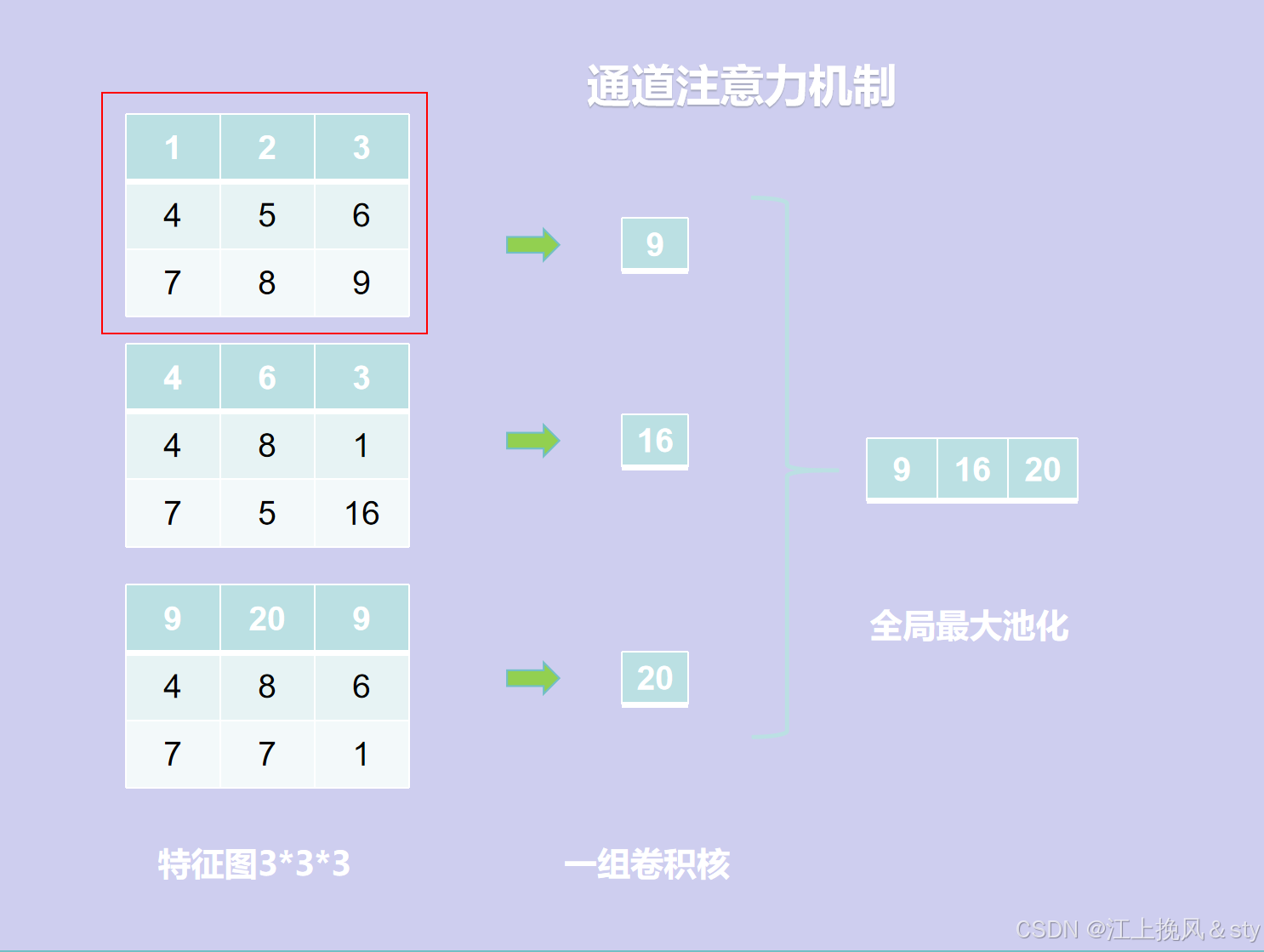
二、空间注意力
2.1、空间注意力是什么
2.1.1、背景前言
在计算机视觉任务中,卷积神经网络(CNNs)已经取得了显著的性能提升。然而,传统的CNNs在处理图像时,往往对整个图像进行均匀处理,没有区分不同区域的重要性。这种均匀处理的方式忽略了图像中某些区域可能包含更多关键信息的事实,从而导致模型在处理复杂图像时的性能受限。为此引入了空间注意力机制(Spatial Attention Mechanism, SAM),和CAM类似,空间注意力则更侧重于每一个通道中的空间信息,为了关注重要的空间信息,抑制不重要的空间信息,神经网络需要学习不同空间的重要程度。
2.1.2、目的
-
提升关键区域的特征表达:空间注意力机制通过对特征图中特定空间位置进行加权,来强调对任务贡献最大的区域,同时抑制无关或冗余区域,从而提升模型性能。
-
增强模型的局部区域表现:通过给予重要的图像区域更多的注意力,空间注意力机制能够提高模型在局部区域的表现
2.1.3、解决的问题
-
空间信息的不均衡:在图像中,不同的区域对任务的贡献度不同。空间注意力机制通过生成权重掩膜(mask),为每个位置分配不同的权重,从而解决这一问题。
-
提升模型的鲁棒性:空间注意力机制通过自适应地选择关注的区域,能够提高模型的性能和鲁棒性。
2.2、空间注意力结构图
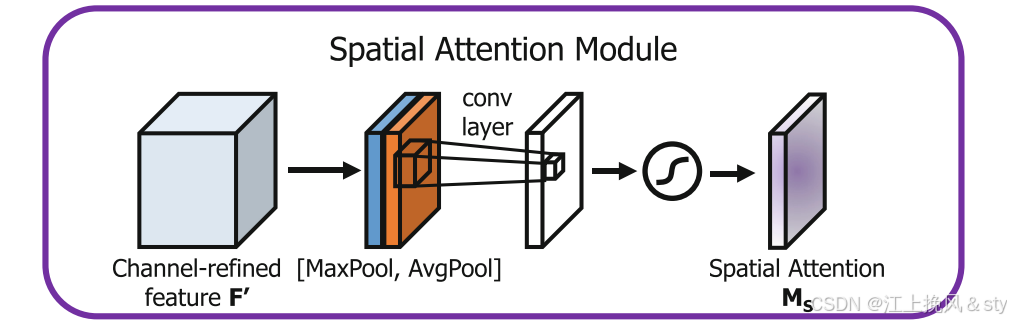
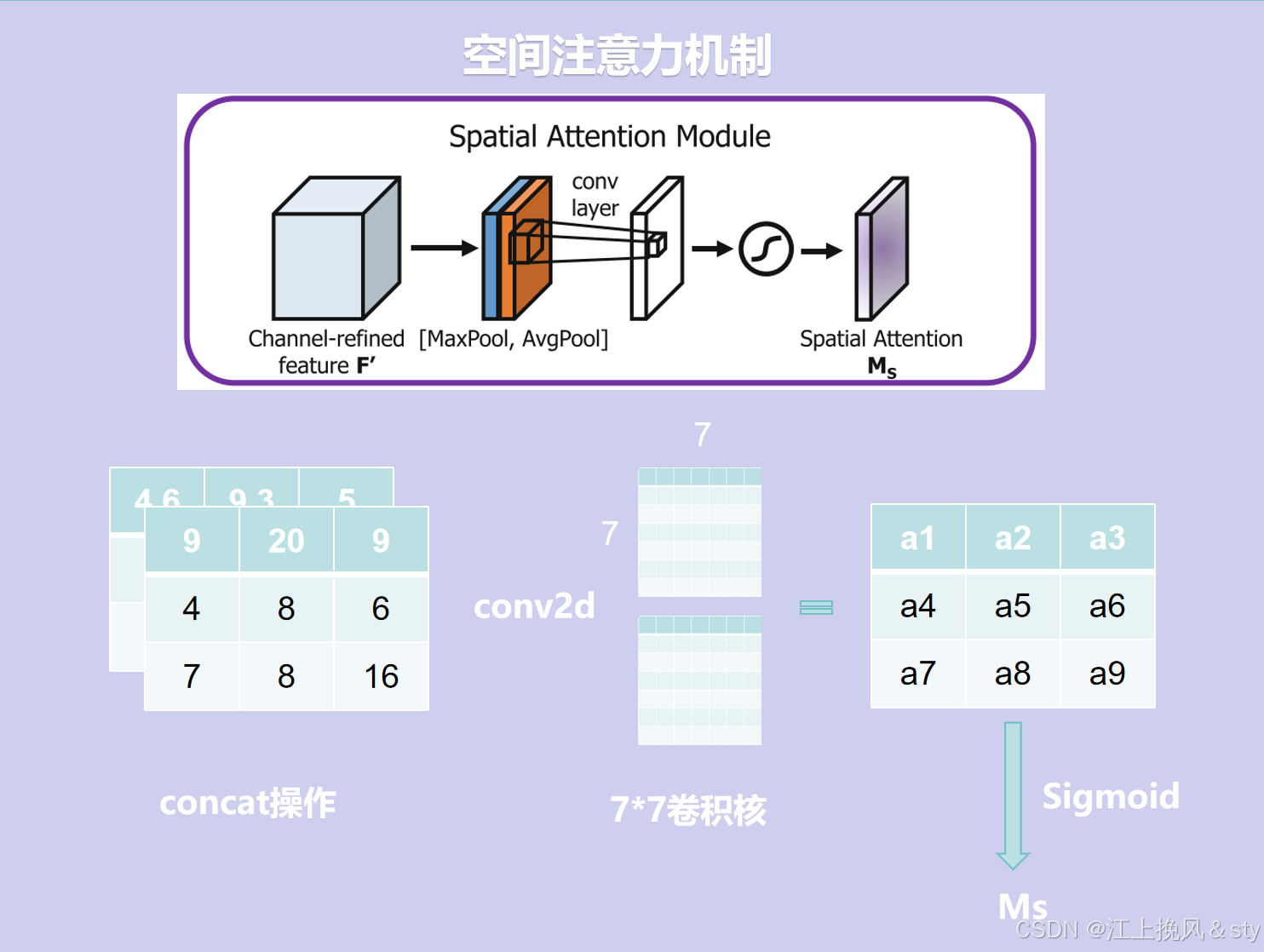
空间注意力的结构图如下图所示:
2.3、空间注意力的计算
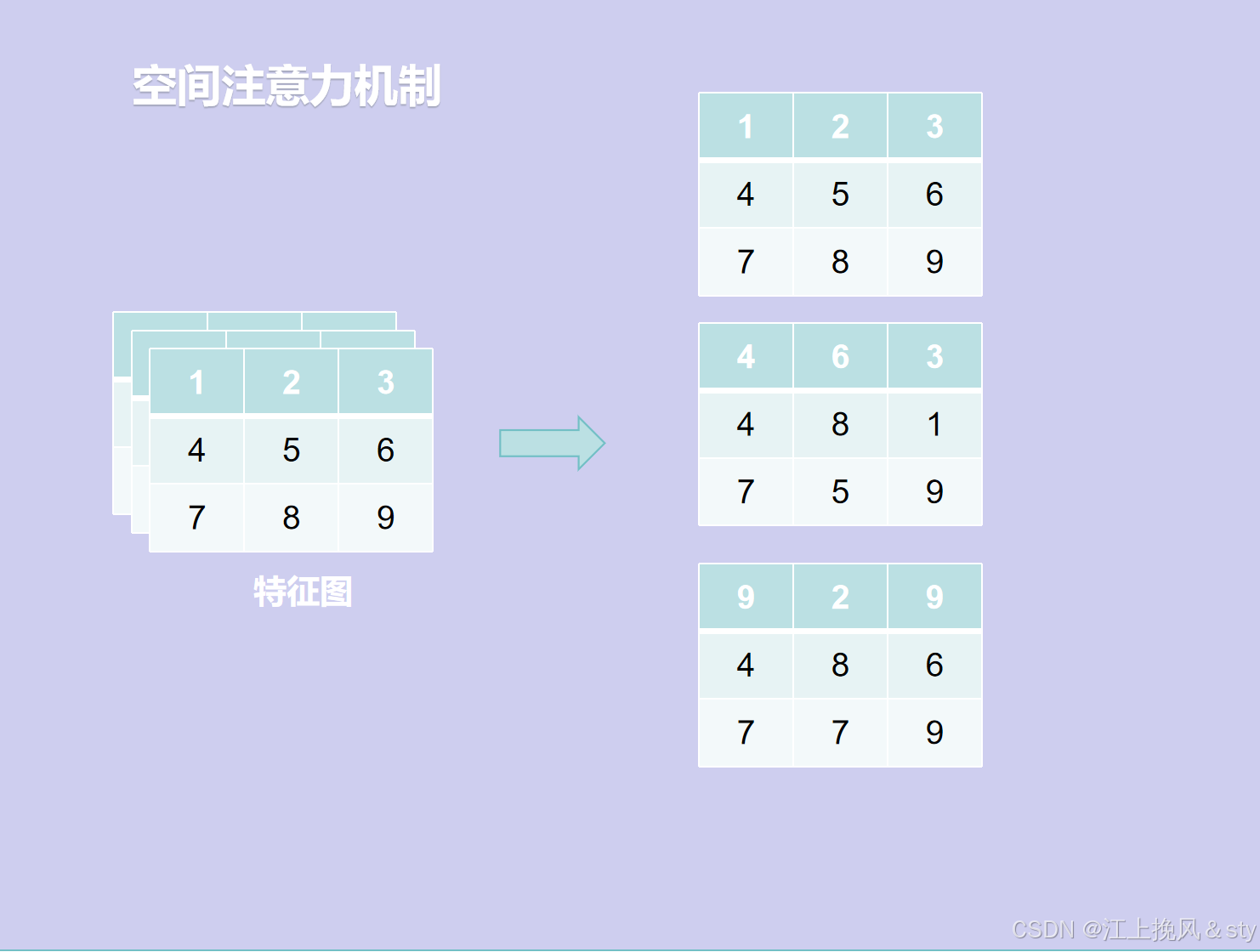
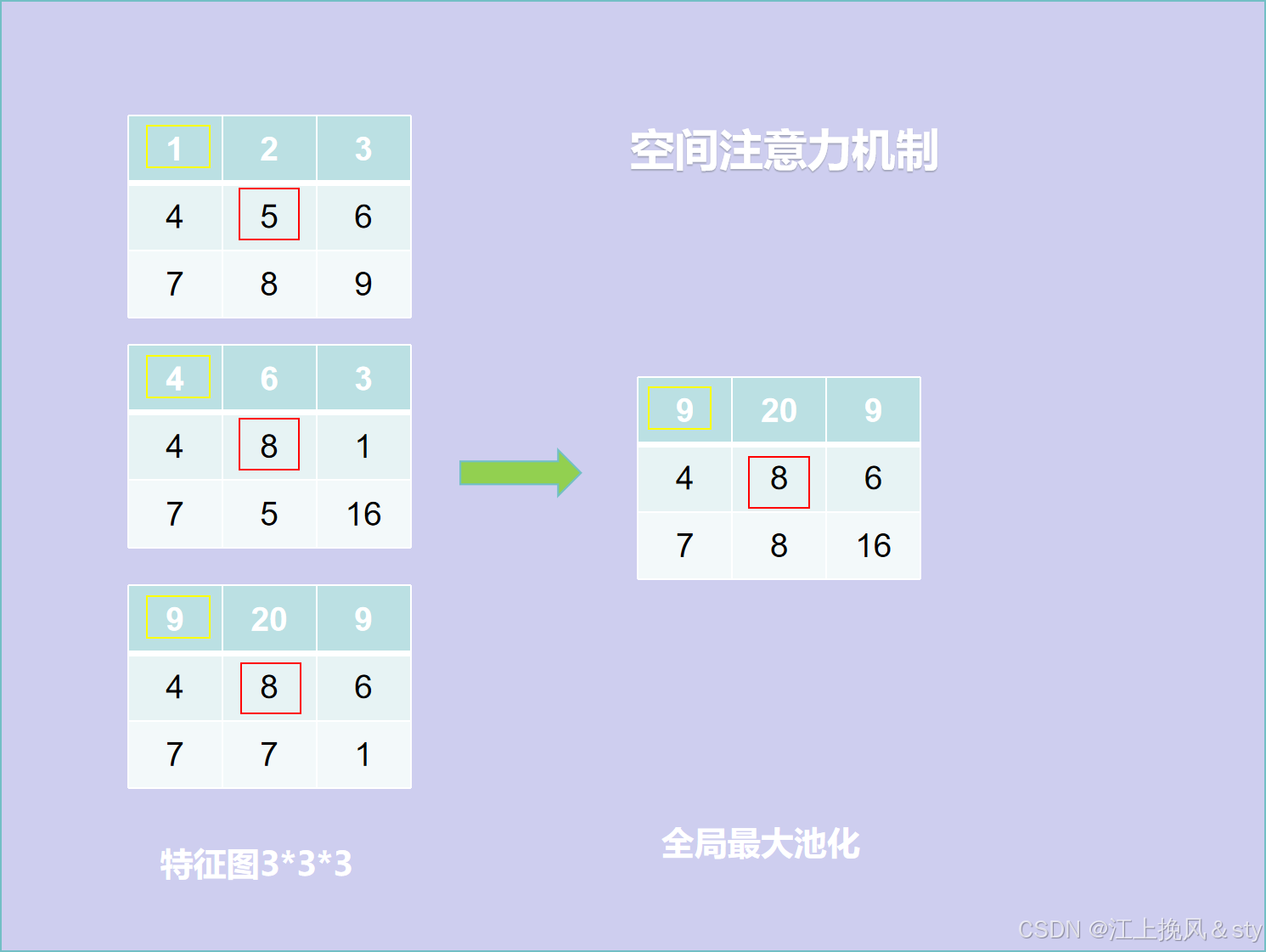
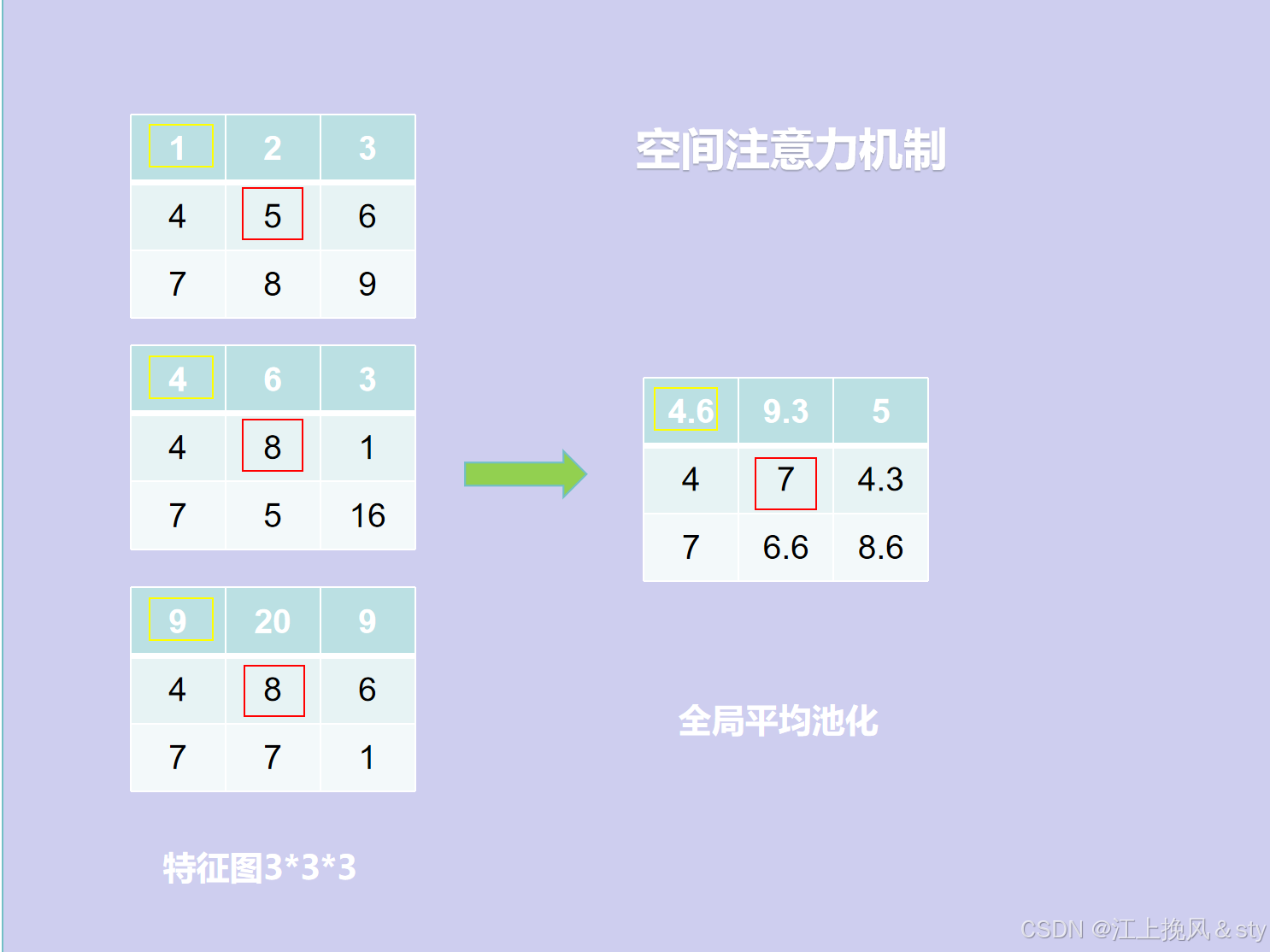
空间注意力的处理流程如下:
- 首先,对于尺寸为H*W*C的输入特征图F(图中Input feature
)进行Maxpool和AvgPool,得到两个H*W*1的特征图;(换个方式可以理解为就是现在C张白纸,白纸的高度和宽幅分别为H和W。现在进行全局最大池化,在通道维度上对于每一张高为H,宽为W的白纸的同一个位置,从中找到其中最大的数值,因为一共有C张白纸,所以会有C个数值,找到其中最大的那个值输出得到对应输出特征图的同一个位置,因为白纸的高宽分别为H和W,所以输出得到的特征图大小高宽也为H和W。全局平均池化,就是对于每一张高为H,宽为W的白纸中的同一个位置的全部元素值相加求平均值,得到输出特征图的对应位置的数值,特征图大小高宽也为H和W)
- 其次,将全局最大池化和全局平均池化的结果按照通道进行拼接(concat操作),得到特征图的尺寸为H*W*2;
- 最后,对拼接的结果进行7*7的卷积操作,得到特征图的尺寸为H*W*1,接着经过Sigmoid激活函数进行映射,得到空间注意力权重矩阵Ms;
计算公式:
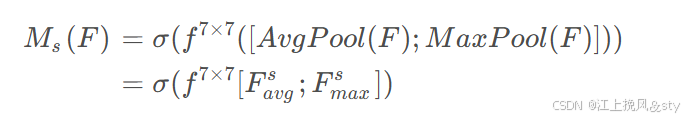
其中,空间注意力权重矩阵,全局平均池化产生的特征图
,全局最大池化产生的特征图
。
以下是个人的理解,如有误请指正:
三、CBAM
3.1、简要概述
卷积块注意力模块(CBAM)通过顺序应用通道注意力和空间注意力模块,对中间特征图进行自适应细化。通过通道注意力和空间注意力的结合,显著提升了CNNs在图像分类和目标检测任务上的性能。
3.2、CBAM结构图
CBAM的结构图如下所示:

3.3、CBAM的计算
通道注意力:
空间注意力:
将通道注意力和空间注意力应用到输入特征图 F上,得到最终的细化特征图 F′′:
四、参考资料
[1] Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attention module[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 3-19.
[2] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
[3] Jaderberg M, Simonyan K, Zisserman A. Spatial transformer networks[J]. Advances in neural information processing systems, 2015, 28.