这是我的第387篇原创文章。
一、引言
贝叶斯神经网络的结构与传统神经网络相似,但将权重参数视为随机变量,并赋予先验分布。例如,对于一个简单的用于股票价格预测的多层感知机神经网络,其输出(预测的股票价格)与输入(如历史价格、成交量、宏观经济指标等特征)的关系可以表示为:,其中 是神经网络的前向传播函数, 是权重参数向量,服从某种先验分布,如高斯分布。先验分布的选择依据对股票市场的先验知识或假设,例如认为权重不应过大,以避免过拟合或不稳定的预测。
在贝叶斯神经网络中,目标是确定神经网络参数的后验分布,而不是像传统神经网络那样确定固定的参数值。在贝叶斯神经网络中,预测不再是一个确定的值,而是一个概率分布。本文实现了一个基于贝叶斯神经网络的回归任务。通过使用变分推断(变分贝叶斯)和 ELBO 损失函数来优化模型。
二、实现过程
2.1 数据准备
代码:
def toy_function(x):
return x*np.sin(x)
x = torch.tensor([ -4, -2, -1, .0, 1, 2, 4]).reshape(-1,1)
y = toy_function(x)
x, y = x.to(device), y.to(device)toy_function定义了一个简单的目标函数 y=x⋅sin(x)y = x \cdot \sin(x)y=x⋅sin(x),用来生成一些训练数据。x是输入数据,包含了几个点(例如:-4, -2, -1, ..., 4),并将其转换为 PyTorch 张量,形状是 (7, 1)。y是目标数据,通过 toy_function(x) 得到。数据被移动到指定的设备(在这里是 CPU)。
2.2 模型定义
代码:
model = BayesMLP(1, 1, [16], activate='tanh').to(device)
# 优化器
opt = Adam(model.parameters(), lr=0.05)
# 损失
loss_fn = RegressionELBOLoss(batch_num=1) # 没有使用小批量BayesMLP是一个自定义的贝叶斯多层感知机模型(多层感知机即MLP)。它包含一个输入层和一个输出层,并且有一个隐藏层(大小为16)。activate='tanh' 表示隐藏层激活函数为双曲正切(tanh)。
Adam优化器被用于训练模型,学习率设为 0.05。
RegressionELBOLoss是一个自定义损失函数,针对回归任务,计算变分贝叶斯下的 ELBO 损失。在这个例子中,batch_num=1 表示没有使用小批量数据训练,而是对整个数据集进行训练。
2.3 模型训练
代码:
epochs = 1000
for epoch in range(epochs): # 算法2:第2行
opt.zero_grad()
model_out = model(x, 1)
loss = loss_fn(model_out, y)
loss.backward() # 算法2:第9行
opt.step() # 第法2:第12行
if epoch % 100 == 0:
print(f'epoch: {epoch:>5}/{epochs:<10} Loss: {loss.item():.6}')模型训练进行1000次迭代(epochs=1000)。每个 epoch 中,首先清零梯度 opt.zero_grad()。将输入 x 传递给模型,计算输出 model_out,并通过 loss_fn 计算 ELBO 损失。计算梯度并更新模型参数:loss.backward() 和 opt.step()。每隔100个 epoch 打印一次当前的损失值。
2.4 测试可视化
代码:
model.eval()
# 测试数据
x_test = torch.linspace(-6.5, 6.5, 100)
y_test = toy_function(x_test)
# 模型预测sample_num次
y_preds = model(x_test.reshape(-1,1).to(device), sample_num=100)
y_preds = np.array([s.cpu().detach().numpy() for s in y_preds]).squeeze(-1)
plt.plot(x_test, np.mean(y_preds, axis = 0), label='Predicted by Mean Posterior') # 平均预测
plt.plot(x_test, y_test, label='Train Datas') # 真实值
plt.fill_between(x_test.reshape(-1),
np.percentile(y_preds, 2.5, axis = 0),
np.percentile(y_preds, 97.5, axis = 0),
alpha = 0.2, label='95% Confidence')
plt.legend()
plt.scatter(x.cpu(), toy_function(x.cpu()))
plt.legend(loc='lower center')
plt.grid()
plt.show()将模型设置为评估模式 model.eval(),这样会关闭某些训练时特有的操作(如dropout)。x_test是测试集的数据,从 -6.5 到 6.5 之间均匀生成100个点。y_test是 toy_function(x_test) 对应的目标
model(x_test.reshape(-1, 1).to(device), sample_num=100)会对 x_test 数据进行预测,并进行100次样本采样,得到贝叶斯模型的不同预测结果。s.cpu().detach().numpy()将每个预测值从 GPU 转到 CPU,并转换为 NumPy 数组。
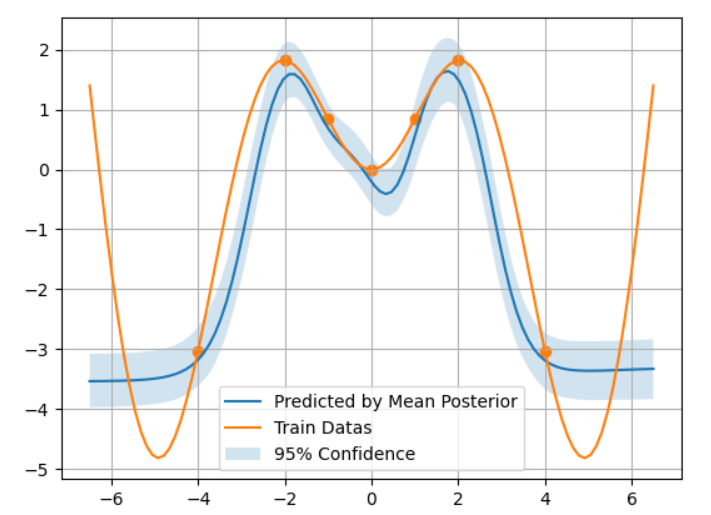
plt.plot(x_test, np.mean(y_preds, axis=0), label='Predicted by Mean Posterior')画出贝叶斯模型的后验均值(即预测结果的平均值)。
plt.plot(x_test, y_test, label='Train Datas') 画出真实的目标函数值。
plt.fill_between用于绘制预测的95%置信区间,即通过计算后验分布的2.5百分位和97.5百分位来定义置信区间。
结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。