一、T5 模型 & 数据集
T5模型,是由Google提出的一种预训练语言模型,结构基于 Transformer 架构实现。自2018年BERT模型问世以来,自然语言处理领域取得了显著进展,而T5模型在此基础上进一步创新,为文本处理任务提供了一种全新的解决方案。
T5模型的核心思想是将所有文本处理任务统一为 文本到文本 的转换任务。这表示,无论是文本分类、情感分析、问答还是机器翻译等任务,都可以通过输入一段文本,经过T5模型处理,输出另一段文本作为结果。这种统一的形式使得T5模型具有广泛的适用性。
T5 模型结构:
T5ForConditionalGeneration(
(shared): Embedding(32128, 1024)
(encoder): T5Stack(
(embed_tokens): Embedding(32128, 1024)
(block): ModuleList(
(0): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=1024, out_features=1024, bias=False)
(k): Linear(in_features=1024, out_features=1024, bias=False)
(v): Linear(in_features=1024, out_features=1024, bias=False)
(o): Linear(in_features=1024, out_features=1024, bias=False)
(relative_attention_bias): Embedding(32, 16)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerFF(
(DenseReluDense): T5DenseGatedActDense(
(wi_0): Linear(in_features=1024, out_features=2816, bias=False)
(wi_1): Linear(in_features=1024, out_features=2816, bias=False)
(wo): Linear(in_features=2816, out_features=1024, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): NewGELUActivation()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
.
. 省略中间层
.
(23): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=1024, out_features=1024, bias=False)
(k): Linear(in_features=1024, out_features=1024, bias=False)
(v): Linear(in_features=1024, out_features=1024, bias=False)
(o): Linear(in_features=1024, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerFF(
(DenseReluDense): T5DenseGatedActDense(
(wi_0): Linear(in_features=1024, out_features=2816, bias=False)
(wi_1): Linear(in_features=1024, out_features=2816, bias=False)
(wo): Linear(in_features=2816, out_features=1024, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): NewGELUActivation()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(final_layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(decoder): T5Stack(
(embed_tokens): Embedding(32128, 1024)
(block): ModuleList(
(0): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=1024, out_features=1024, bias=False)
(k): Linear(in_features=1024, out_features=1024, bias=False)
(v): Linear(in_features=1024, out_features=1024, bias=False)
(o): Linear(in_features=1024, out_features=1024, bias=False)
(relative_attention_bias): Embedding(32, 16)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerCrossAttention(
(EncDecAttention): T5Attention(
(q): Linear(in_features=1024, out_features=1024, bias=False)
(k): Linear(in_features=1024, out_features=1024, bias=False)
(v): Linear(in_features=1024, out_features=1024, bias=False)
(o): Linear(in_features=1024, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): T5LayerFF(
(DenseReluDense): T5DenseGatedActDense(
(wi_0): Linear(in_features=1024, out_features=2816, bias=False)
(wi_1): Linear(in_features=1024, out_features=2816, bias=False)
(wo): Linear(in_features=2816, out_features=1024, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): NewGELUActivation()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
.
. 省略中间层
.
(23): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=1024, out_features=1024, bias=False)
(k): Linear(in_features=1024, out_features=1024, bias=False)
(v): Linear(in_features=1024, out_features=1024, bias=False)
(o): Linear(in_features=1024, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerCrossAttention(
(EncDecAttention): T5Attention(
(q): Linear(in_features=1024, out_features=1024, bias=False)
(k): Linear(in_features=1024, out_features=1024, bias=False)
(v): Linear(in_features=1024, out_features=1024, bias=False)
(o): Linear(in_features=1024, out_features=1024, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): T5LayerFF(
(DenseReluDense): T5DenseGatedActDense(
(wi_0): Linear(in_features=1024, out_features=2816, bias=False)
(wi_1): Linear(in_features=1024, out_features=2816, bias=False)
(wo): Linear(in_features=2816, out_features=1024, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): NewGELUActivation()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(final_layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(lm_head): Linear(in_features=1024, out_features=32128, bias=False)
)
由于谷歌原生的T5模型对中文的支持不是特别友好,因此本文基于 T5 结构,使用 utrobinmv/t5_translate_en_ru_zh_small_1024 多语言翻译预训练模型作为底座模型, 强化微调训练 Ner 命名实体识别任务。数据集采用 CLUENER(中文语言理解测评基准)2020数据集。
utrobinmv/t5_translate_en_ru_zh_small_1024 模型地址:
https://huggingface.co/utrobinmv/t5_translate_en_ru_zh_small_1024

数据集下载:

数据分为10个标签类别,分别为: 地址(address),书名(book),公司(company),游戏(game),政府(goverment),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene)
数据实例如下:
{
"text": "浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,", "label": {
"name": {
"叶老桂": [[9, 11]]}, "company": {
"浙商银行": [[0, 3]]}}}
{
"text": "生生不息CSOL生化狂潮让你填弹狂扫", "label": {
"game": {
"CSOL": [[4, 7]]}}}
{
"text": "那不勒斯vs锡耶纳以及桑普vs热那亚之上呢?", "label": {
"organization": {
"那不勒斯": [[0, 3]], "锡耶纳": [[6, 8]], "桑普": [[11, 12]], "热那亚": [[15, 17]]}}}
{
"text": "加勒比海盗3:世界尽头》的去年同期成绩死死甩在身后,后者则即将赶超《变形金刚》,", "label": {
"movie": {
"加勒比海盗3:世界尽头》": [[0, 11]], "《变形金刚》": [[33, 38]]}}}
{
"text": "布鲁京斯研究所桑顿中国中心研究部主任李成说,东亚的和平与安全,是美国的“核心利益”之一。", "label": {
"address": {
"美国": [[32, 33]]}, "organization": {
"布鲁京斯研究所桑顿中国中心": [[0, 12]]}, "name": {
"李成": [[18, 19]]}, "position": {
"研究部主任": [[13, 17]]}}}
{
"text": "目前主赞助商暂时空缺,他们的球衣上印的是“unicef”(联合国儿童基金会),是公益性质的广告;", "label": {
"organization": {
"unicef": [[21, 26]], "联合国儿童基金会": [[29, 36]]}}}
{
"text": "此数据换算成亚洲盘罗马客场可让平半低水。", "label": {
"organization": {
"罗马": [[9, 10]]}}}
{
"text": "你们是最棒的!#英雄联盟d学sanchez创作的原声王", "label": {
"game": {
"英雄联盟": [[8, 11]]}}}
{
"text": "除了吴湖帆时现精彩,吴待秋、吴子深、冯超然已然归入二三流了,", "label": {
"name": {
"吴湖帆": [[2, 4]], "吴待秋": [[10, 12]], "吴子深": [[14, 16]], "冯超然": [[18, 20]]}}}
{
"text": "在豪门被多线作战拖累时,正是他们悄悄追赶上来的大好时机。重新找回全队的凝聚力是拉科赢球的资本。", "label": {
"organization": {
"拉科": [[39, 40]]}}}
其中 train.json 有 10748 条数据,dev.json 中有 1343 条数据,可作为验证集使用。
本次我们实验暂时不需要模型输出位置,这里对数据集格式进行转换:
import json
def trans(file_path, save_path):
with open(save_path, "a", encoding="utf-8") as w:
with open(file_path, "r", encoding="utf-8") as r:
for line in r:
line = json.loads(line)
text = line['text']
label = line['label']
trans_label = {
}
for key, items in label.items():
items = items.keys()
trans_label[key] = list(items)
trans = {
"text": text,
"label": trans_label
}
line = json.dumps(trans, ensure_ascii=False)
w.write(line + "\n")
w.flush()
if __name__ == '__main__':
trans("ner_data_origin/train.json", "ner_data/train.json")
trans("ner_data_origin/dev.json", "ner_data/val.json")
转换后的数据格式示例:
{
"text": "彭小军认为,国内银行现在走的是台湾的发卡模式,先通过跑马圈地再在圈的地里面选择客户,", "label": {
"address": ["台湾"], "name": ["彭小军"]}}
{
"text": "温格的球队终于又踢了一场经典的比赛,2比1战胜曼联之后枪手仍然留在了夺冠集团之内,", "label": {
"organization": ["曼联"], "name": ["温格"]}}
{
"text": "突袭黑暗雅典娜》中Riddick发现之前抓住他的赏金猎人Johns,", "label": {
"game": ["突袭黑暗雅典娜》"], "name": ["Riddick", "Johns"]}}
{
"text": "郑阿姨就赶到文汇路排队拿钱,希望能将缴纳的一万余元学费拿回来,顺便找校方或者教委要个说法。", "label": {
"address": ["文汇路"]}}
{
"text": "我想站在雪山脚下你会被那巍峨的雪山所震撼,但你一定要在自己身体条件允许的情况下坚持走到牛奶海、", "label": {
"scene": ["牛奶海", "雪山"]}}
{
"text": "吴三桂演义》小说的想像,说是为牛金星所毒杀。……在小说中加插一些历史背景,", "label": {
"book": ["吴三桂演义》"], "name": ["牛金星"]}}
{
"text": "看来各支一二流的国家队也开始走出欧洲杯后低迷,从本期对阵情况看,似乎冷门度也不太高,你认为呢?", "label": {
"organization": ["欧洲杯"]}}
{
"text": "就天涯网推出彩票服务频道是否是业内人士所谓的打政策“擦边球”,记者近日对此事求证彩票监管部门。", "label": {
"organization": ["彩票监管部门"], "company": ["天涯网"], "position": ["记者"]}}
{
"text": "市场仍存在对网络销售形式的需求,网络购彩前景如何?为此此我们采访业内专家程阳先生。", "label": {
"name": ["程阳"], "position": ["专家"]}}
{
"text": "组委会对中国区预选赛进行了抽签分组,并且对本次抽签进行了全程直播。", "label": {
"government": ["组委会"]}}
查看整体数据集 train.json 的 Token 分布:
import json
from transformers import T5Tokenizer
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
def get_token_distribution(file_path, tokenizer):
input_num_tokens, outout_num_tokens = [], []
with open(file_path, "r", encoding="utf-8") as r:
for line in r:
line = json.loads(line)
text = line['text']
label = line['label']
label = json.dumps(label, ensure_ascii=False)
input_num_tokens.append(len(tokenizer(text).input_ids))
outout_num_tokens.append(len(tokenizer(label).input_ids))
return min(input_num_tokens), max(input_num_tokens), np.mean(input_num_tokens),\
min(outout_num_tokens), max(outout_num_tokens), np.mean(outout_num_tokens)
def main():
model_path = "utrobinmv/t5_translate_en_ru_zh_small_1024"
train_data_path = "ner_data/train.json"
tokenizer = T5Tokenizer.from_pretrained(model_path, trust_remote_code=True)
i_min, i_max, i_avg, o_min, o_max, o_avg = get_token_distribution(train_data_path, tokenizer)
print(i_min, i_max, i_avg, o_min, o_max, o_avg)
plt.figure(figsize=(8, 6))
bars = plt.bar([
"input_min_token",
"input_max_token",
"input_avg_token",
"ouput_min_token",
"ouput_max_token",
"ouput_avg_token",
], [
i_min, i_max, i_avg, o_min, o_max, o_avg
])
plt.title('训练集Token分布情况')
plt.ylabel('数量')
for bar in bars:
yval = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2, yval, int(yval), va='bottom')
plt.show()
if __name__ == '__main__':
main()
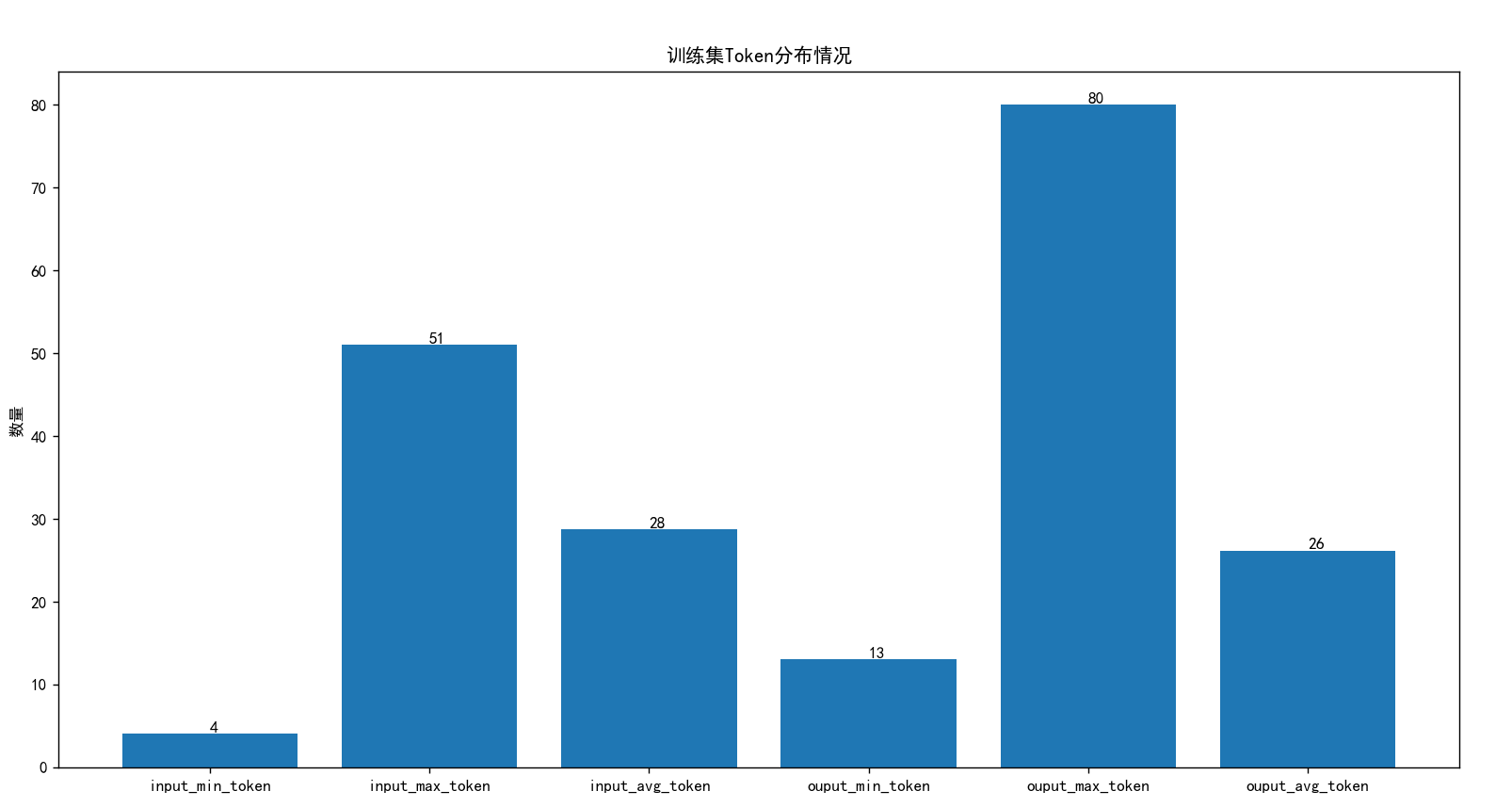
其中输入Token 最大是 51,输出 Token 最大是 90 。
二、微调训练
解析数据,构建 Dataset 数据集:
ner_dataset.py
# -*- coding: utf-8 -*-
from torch.utils.data import Dataset
import torch
import json
class NerDataset(Dataset):
def __init__(self, data_path, tokenizer, max_source_length, max_target_length) -> None:
super().__init__()
self.tokenizer = tokenizer
self.max_source_length = max_source_length
self.max_target_length = max_target_length
self.max_seq_length = self.max_source_length + self.max_target_length
self.data = []
if data_path:
with open(data_path, "r", encoding='utf-8') as f:
for line in f:
if not line or line == "":
continue
json_line = json.loads(line)
text = json_line["text"]
label = json_line["label"]
label = json.dumps(label, ensure_ascii=False)
self.data.append({
"text": text,
"label": label
})
print("data load , size:", len(self.data))
def preprocess(self, text, label):
prompt = f"实体识别任务: 找出[{
text}]中所有[address,book,company,game,goverment,movie,name,organization,position,scene]类型的实体"
encoding = self.tokenizer(
prompt,
max_length=self.max_source_length,
pad_to_max_length=True,
truncation=True,
padding="max_length",
return_tensors="pt",
)
target_encoding = self.tokenizer(
label,
max_length=self.max_target_length,
pad_to_max_length=True,
truncation=True,
padding="max_length",
return_tensors="pt",
)
input_ids = encoding["input_ids"].squeeze()
attention_mask = encoding["attention_mask"].squeeze()
labels = target_encoding["input_ids"].squeeze()
return input_ids, attention_mask, labels
def __getitem__(self, index):
item_data = self.data[index]
input_ids, attention_mask, labels = self.preprocess(**item_data)
return {
"input_ids": input_ids.to(dtype=torch.long),
"attention_mask": attention_mask.to(dtype=torch.long),
"labels": labels.to(dtype=torch.long)
}
def __len__(self):
return len(self.data)
构建训练过程,这里对全部参数微调:
# -*- coding: utf-8 -*-
import os.path
import torch
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from transformers import T5Tokenizer, T5ForConditionalGeneration
from ner_dataset import NerDataset
from tqdm import tqdm
import time, sys
def train_model(model, train_loader, val_loader, optimizer,
device, num_epochs, model_output_dir, scheduler, writer):
batch_step = 0
best_val_loss = float('inf')
for epoch in range(num_epochs):
time1 = time.time()
model.train()
for index, data in enumerate(tqdm(train_loader, file=sys.stdout, desc="Train Epoch: " + str(epoch))):
input_ids = data['input_ids'].to(device, dtype=torch.long)
attention_mask = data['attention_mask'].to(device, dtype=torch.long)
labels = data['labels'].to(device, dtype=torch.long)
# 清空过往梯度
optimizer.zero_grad()
# 前向传播
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
loss = outputs.loss
# 反向传播,计算当前梯度
loss.backward()
# 更新网络参数
optimizer.step()
writer.add_scalar('Loss/train', loss, batch_step)
batch_step += 1
# 100轮打印一次 loss
if index % 100 == 0 or index == len(train_loader) - 1:
time2 = time.time()
tqdm.write(
f"{
index}, epoch: {
epoch} -loss: {
str(loss)} ; lr: {
optimizer.param_groups[0]['lr']} ;each step's time spent: {
(str(float(time2 - time1) / float(index + 0.0001)))}")
# 验证
model.eval()
val_loss = validate_model(model, device, val_loader)
writer.add_scalar('Loss/val', val_loss, epoch)
print(f"val loss: {
val_loss} , epoch: {
epoch}")
# 学习率调整
scheduler.step(val_loss)
# 保存最优模型
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model_path = os.path.join(model_output_dir, "best")
print("Save Best Model To ", best_model_path, ", epoch: ", epoch)
model.save_pretrained(best_model_path)
# 保存当前模型
last_model_path = os.path.join(model_output_dir, "last")
print("Save Last Model To ", last_model_path, ", epoch: ", epoch)
model.save_pretrained(last_model_path)
def validate_model(model, device, val_loader):
running_loss = 0.0
with torch.no_grad():
for _, data in enumerate(tqdm(val_loader, file=sys.stdout, desc="Validation Data")):
input_ids = data['input_ids'].to(device, dtype=torch.long)
attention_mask = data['attention_mask'].to(device, dtype=torch.long)
labels = data['labels'].to(device, dtype=torch.long)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
loss = outputs[0]
running_loss += loss.item()
return running_loss / len(val_loader)
def main():
# 基础模型位置
model_name = "utrobinmv/t5_translate_en_ru_zh_small_1024"
# 训练集
train_json_path = "ner_data/train.json"
# 验证集
val_json_path = "ner_data/val.json"
max_source_length = 100
max_target_length = 120
epochs = 10
batch_size = 30
lr = 1e-4
model_output_dir = "output_ner"
logs_dir = "logs"
# 设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载分词器和模型
tokenizer = T5Tokenizer.from_pretrained(model_name, trust_remote_code=True)
model = T5ForConditionalGeneration.from_pretrained(model_name, trust_remote_code=True)
print("Start Load Train Data...")
train_params = {
"batch_size": batch_size,
"shuffle": True,
"num_workers": 4,
}
training_set = NerDataset(train_json_path, tokenizer, max_source_length, max_target_length)
training_loader = DataLoader(training_set, **train_params)
print("Start Load Validation Data...")
val_params = {
"batch_size": batch_size,
"shuffle": False,
"num_workers": 4,
}
val_set = NerDataset(val_json_path, tokenizer, max_source_length, max_target_length)
val_loader = DataLoader(val_set, **val_params)
# 日志记录
writer = SummaryWriter(logs_dir)
# 优化器
optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr)
# 学习率调度器,连续两个周期没有改进,学习率调整为当前学习率的一半
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', patience=2, factor=0.5)
model = model.to(device)
# 开始训练
print("Start Training...")
train_model(
model=model,
train_loader=training_loader,
val_loader=val_loader,
optimizer=optimizer,
device=device,
num_epochs=epochs,
model_output_dir=model_output_dir,
scheduler=scheduler,
writer=writer
)
writer.close()
if __name__ == '__main__':
main()
训练过程:
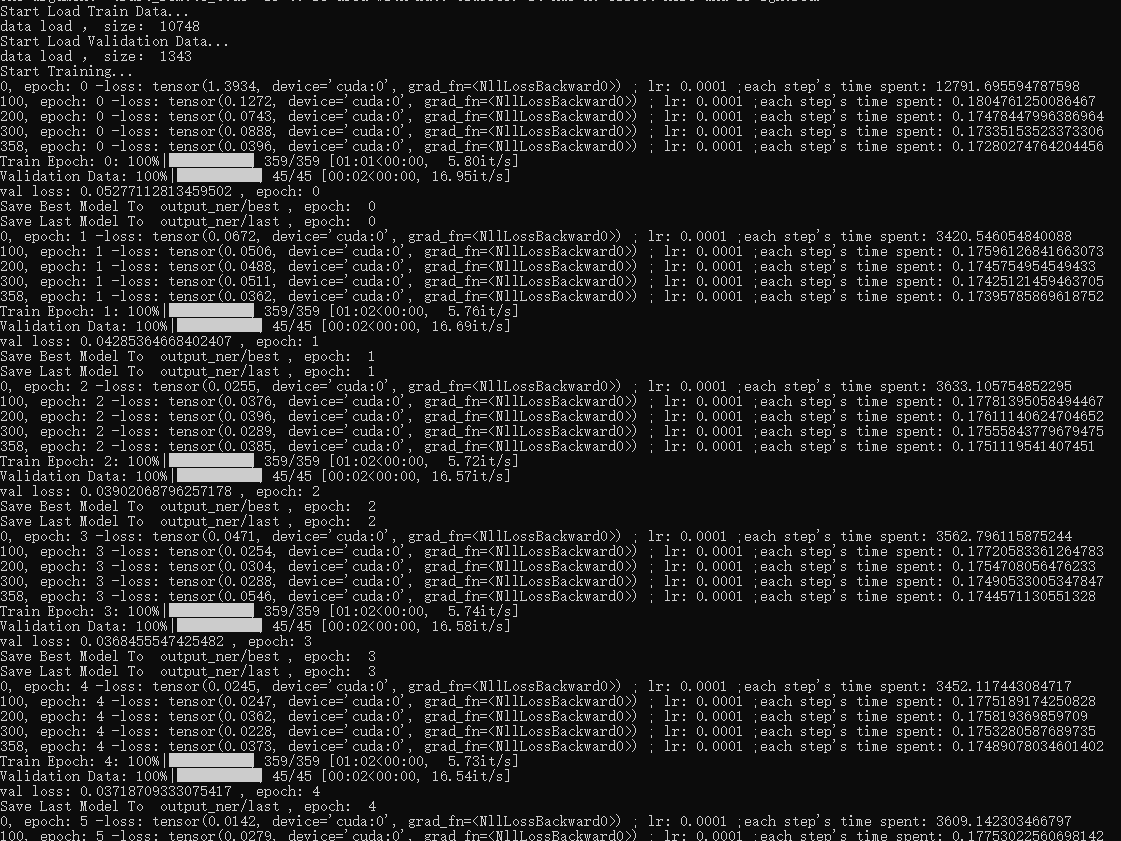
训练大概占用 11.5G 的显存,如果显存不足可以适当调整 batch_size 或修改为梯度累计的方式:
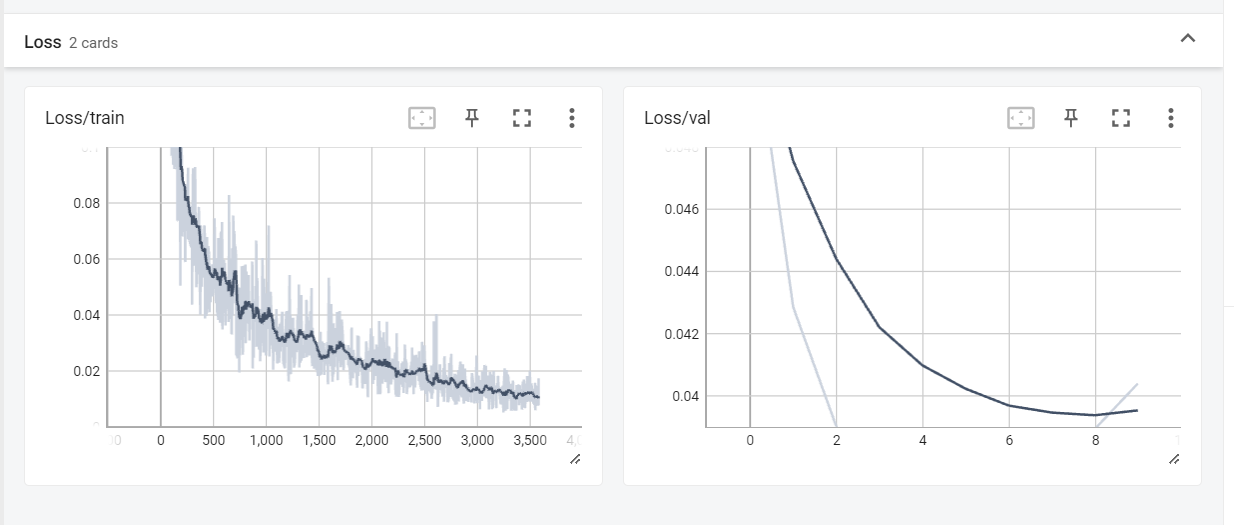
训练结束后,可以查看下 tensorboard 中你的 loss 曲线:
tensorboard --logdir=logs --bind_all
在 浏览器访问 http:ip:6006/
三、模型测试
# -*- coding: utf-8 -*-
from transformers import T5Tokenizer, T5ForConditionalGeneration
import torch
import json
def main():
model_path = "utrobinmv/t5_translate_en_ru_zh_small_1024"
train_model_path = "output_ner/best"
test_file_path = "ner_data_origin/test.json"
tokenizer = T5Tokenizer.from_pretrained(model_path, trust_remote_code=True)
model = T5ForConditionalGeneration.from_pretrained(train_model_path, trust_remote_code=True)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
test_count = 0
with open(test_file_path, "r", encoding="utf-8") as r:
for line in r:
line = json.loads(line)
id = line['id']
text = line['text']
prompt = f"实体识别任务: 找出[{
text}]中所有[address,book,company,game,goverment,movie,name,organization,position,scene]类型的实体"
encoded_input = tokenizer(prompt, max_length=100)
input_ids = torch.tensor([encoded_input['input_ids']]).to(device)
attention_mask = torch.tensor([encoded_input['attention_mask']]).to(device)
outputs = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
max_new_tokens=120
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("----------------------------------")
print(f"id: {
id}, input: {
text}\nresult: {
response}")
test_count+=1
if test_count > 100:
break
if __name__ == '__main__':
main()
id: 5, input: filippagowski:14岁时我感觉自己像梵高
result: {
"name": ["filippagowski", "梵高"]}
----------------------------------
id: 6, input: 央视新址文化中心外立面受损严重
result: {
"address": ["央视新址文化中心"]}
----------------------------------
id: 7, input: 单看这张彩票,税前总奖金为5063992元。本张票面缩水后阿森纳的结果全部为0,斯图加特全部为1,
result: {
"organization": ["阿森纳", "斯图加特"]}
----------------------------------
id: 8, input: 你会和星级厨师一道先从巴塞罗那市中心兰布拉大道的laboqueria市场的开始挑选食材,
result: {
"address": ["巴塞罗那市中心兰布拉大道的laboqueria市场"], "position": ["厨师"]}
----------------------------------
id: 9, input: 波特与凤凰社》的率队下更加红火。乘着7月的上升气流,《发胶》、《辛普森一家》、《谍影憧憧ⅲ》
result: {
"movie": ["波特与凤凰社》", "《发胶》", "《辛普森一家》", "《谍影憧憧iii》"]}
----------------------------------
id: 10, input: 他们需要在当地的签证申请中心留下自己的生物指纹记录。
result: {
"address": ["签证申请中心"]}
----------------------------------
id: 11, input: 可尝试作为“博胆”。切尔西上轮欧冠输给罗马场面太过“难看”,不能用正常水准来衡量。
result: {
"organization": ["切尔西", "欧冠", "罗马"]}
----------------------------------
id: 12, input: 是否有一种更加合理和安全的方式能够保护消费者的用卡安全,值得信用卡发行者探讨。(记者陈翔、黄丹彤)
result: {
"name": ["陈翔", "黄丹彤"], "position": ["记者"]}
----------------------------------
id: 13, input: 而此前招行则明确表示,其信用卡要“从进攻转向防守,脚步要放慢,要沉潜下来,进行内在转型”。
result: {
"company": ["招行"]}
----------------------------------
id: 14, input: 2009年1月,北京市长郭金龙在其政府工作报告中曾明确提出,限价房不停建,
result: {
"address": ["北京"], "name": ["郭金龙"], "position": ["市长"]}