你将学到
1. 什么场景下需要读写分离
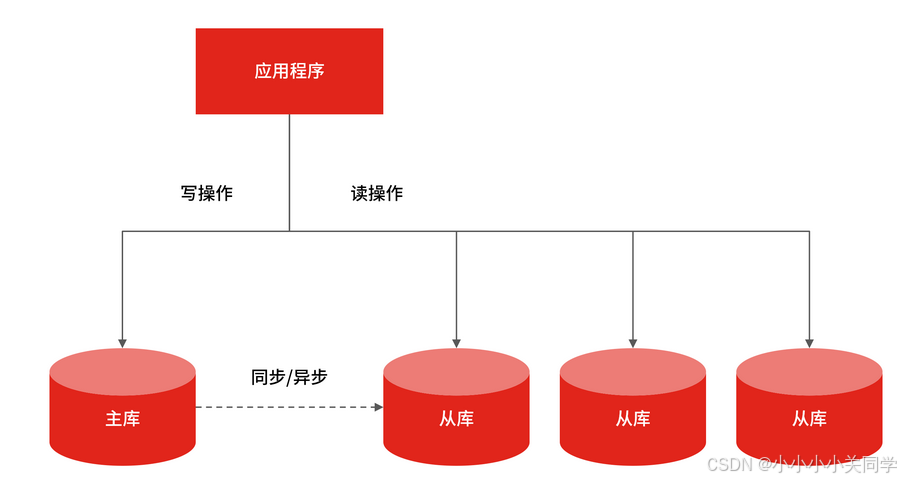
互联网大部分业务场景都是读多写少的,对于电商等典型业务,读和写的请求对比可能差了不止一个数量级。为了不让数据库的读成为业务瓶颈,同时也为了保证写库的成功率,一般会采用读写分离的技术来保证。
读写分离顾名思义,就是分离读库和写库操作,从 CRUD 的角度,主数据库处理新增、修改、删除等事务性操作,而从数据库处理 SELECT 查询操作。具体的实现上,可以有一主一从,一个主库配置一个从库;也可以一主多从,也就是一个主库,但是配置多个从库,读操作通过多个从库进行,支撑更高的读并发压力。
读写分离的实现是把访问的压力从主库转移到从库,特别在单机数据库无法支撑并发读写,并且业务请求大部分为读操作的情况下。如果业务特点是写多读少,比如一些需要动态更新的业务场景,应用读写分离就不合适了,由于MySQLInnoD8 等关系型数据库对事务的支持,使得写性能不会太高,一般会选择更高性能的 NoSQL 等存储来实现。
案例分析
某电商平台的商品信息管理系统,商品信息的查询频率远高于更新频率,如用户浏览商品详情、搜索商品等操作非常频繁,而商品信息的更新(如价格、库存调整)相对较少。
解决方案:读写分离
为了应对高并发查询和减轻主数据库的压力,采用读写分离架构:
-
主数据库(Master):负责处理写操作(如商品信息的更新)。
-
从数据库(Slave):负责处理读操作(如商品信息的查询),通过主从复制同步主库的数据。
2. 如何实现读写分离(MySQL主从复制的原理)
读写分离是基于主从复制架构实现的,下面介绍游戏额MySQL中的主从复制技术。
2.1 binlog日志
Binlog(Binary Log)是 MySQL 中的二进制日志文件,用于记录所有对数据库的写操作(如 INSERT
UPDATE、 DELETE 等),但不记录 SELECT 操作。前面的博客中有对binlog的详细介绍:【MySQL】常见的MySQL日志都有什么用?_mysql的日志有哪几类,作用是什么-CSDN博客文章浏览阅读1.7k次,点赞32次,收藏23次。MySQL日志的内容非常重要,面试中经常会被问到。同时,掌握日志相关的知识也有利于我们理解MySQL 底层原理,必要时帮助我们排查解决问题。主要介绍了二进制i日志、慢查询日志、重做日志、撤销日志_mysql的日志有哪几类,作用是什么https://blog.csdn.net/qq_45875349/article/details/140318005
binlog 有三种格式: Statement、Row及 Mixed。
1. Statement 格式,基于 SQL 语句的复制
在 Statement 格式中,binlog 会记录每一条修改数据的 SQL 操作,从库拿到后在本地进行回放就可以了
2. Row 格式,基于行信息复制
Row 格式以行为维度,记录每一行数据修改的细节,不记录执行 SQL 语句的上下文相关的信息,仅记录行数据的修改。假设有一个批量更新操作,会以行记录的形式来保存二进制文件,这样可能会产生大量的日志内容。
3. Mixed 格式,混合模式复制
Mixed 格式,就是 Statement与 Row 的结合,在这种方式下,不同的 SQL 操作会区别对待。比如一般的数据操作使用 row 格式保存,有些表结构的变更语句,使用 statement 来记录。
2.2 主从复制过程
MySQL 主从复制过程如下图所示:

- 主库将变更写入 binlog 日志,从库连接到主库之后,主库会创建一个log dump 线程,用于发送 bin log 的内容。
- 从库开启同步以后,会创建一个 IO 线程用来连接主库,请求主库中更新的 bin log,I/O 线程接收到主库binlog dump 进程发来的更新之后,保存在本地 relay 日志中。
- 接着从库中有一个 SQL 线程负责读取 relay log 中的内容,同步到数据库存储中,也就是在自己本地进行回放,最终保证主从数据的一致性。
3. 数据复制方式(主从复制模型)
二进制日志(binlog),它是一个文件,在进行网络传输的过程中就一定会存在一些延迟,比如200ms,这样就可能造成用户在从库上读取的数据不是最新的数据,也就会造成主从同步中的数据不一致的情况发生。比如我们对一条记录进行更新,这个操作是在主库上完成的,而在很短的时间内,比如100ms,又对同一个记录进行读取,这时候从库还没有完成数据的同步,那么,我们通过从库读取到的数据就是一条旧的数据。这时候就要了解数据复制方式了。
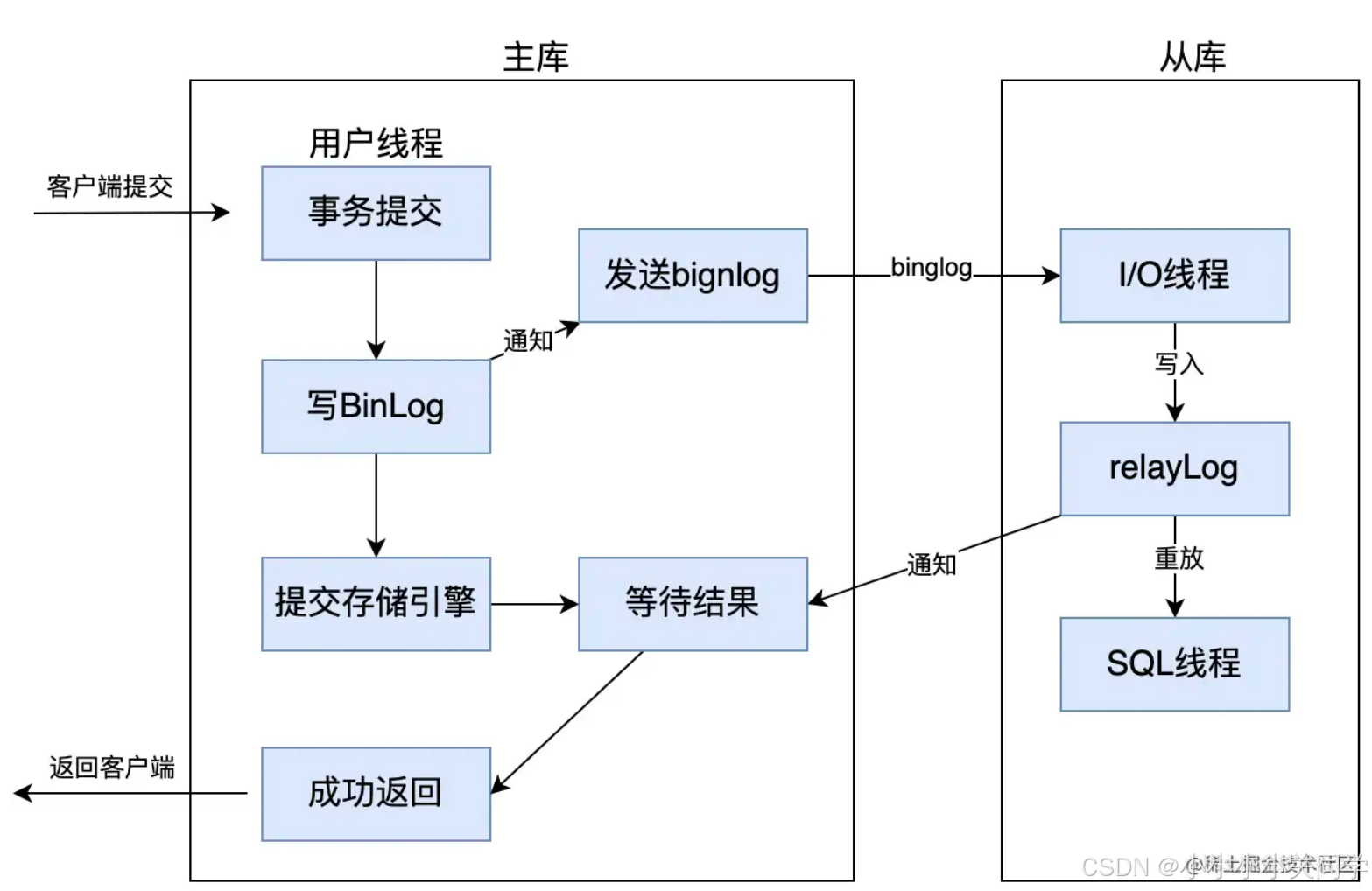
3.1 全同步复制
全同步复制,就是当主库执行完一个事务之后,要求 所有的从库 也都必须执行完该事务,才可以返回处理结果给客户端。因此,虽然全同步复制数据一致性得到保证了,但是主库完成一个事务需要等待所有从库也完成,性能会比较低。
3.2 异步复制
MySQL 主从复制,默认采用的复制策略就是异步复制。

异步复制,就是当主库提交事务后,会通知 binlog dump 线程发送 binlog 日志给从库,一旦 binlogdump 线程将 binlog 日志发送给从库之后,不需要等到从库也同步完成事务,主库就会将处理结果返回给客户端。
因为主库只管自己执行完事务,就可以将处理结果返回给客户端,而不用关心从库是否执行完事务,这就可能导致短暂的主从数据不一致的问题了,比如刚在主库插入的新数据,如果马上在从库查询,就可能查询不到。
而且,当主库提交事物后,如果宕机挂掉了,此时可能 binlog 还没来得及同步给从库,这时候如果为了恢复故障切换主从节点的话就会出现数据丢失的问题,所以异步复制虽然性能高,但数据一致性上是最弱的。
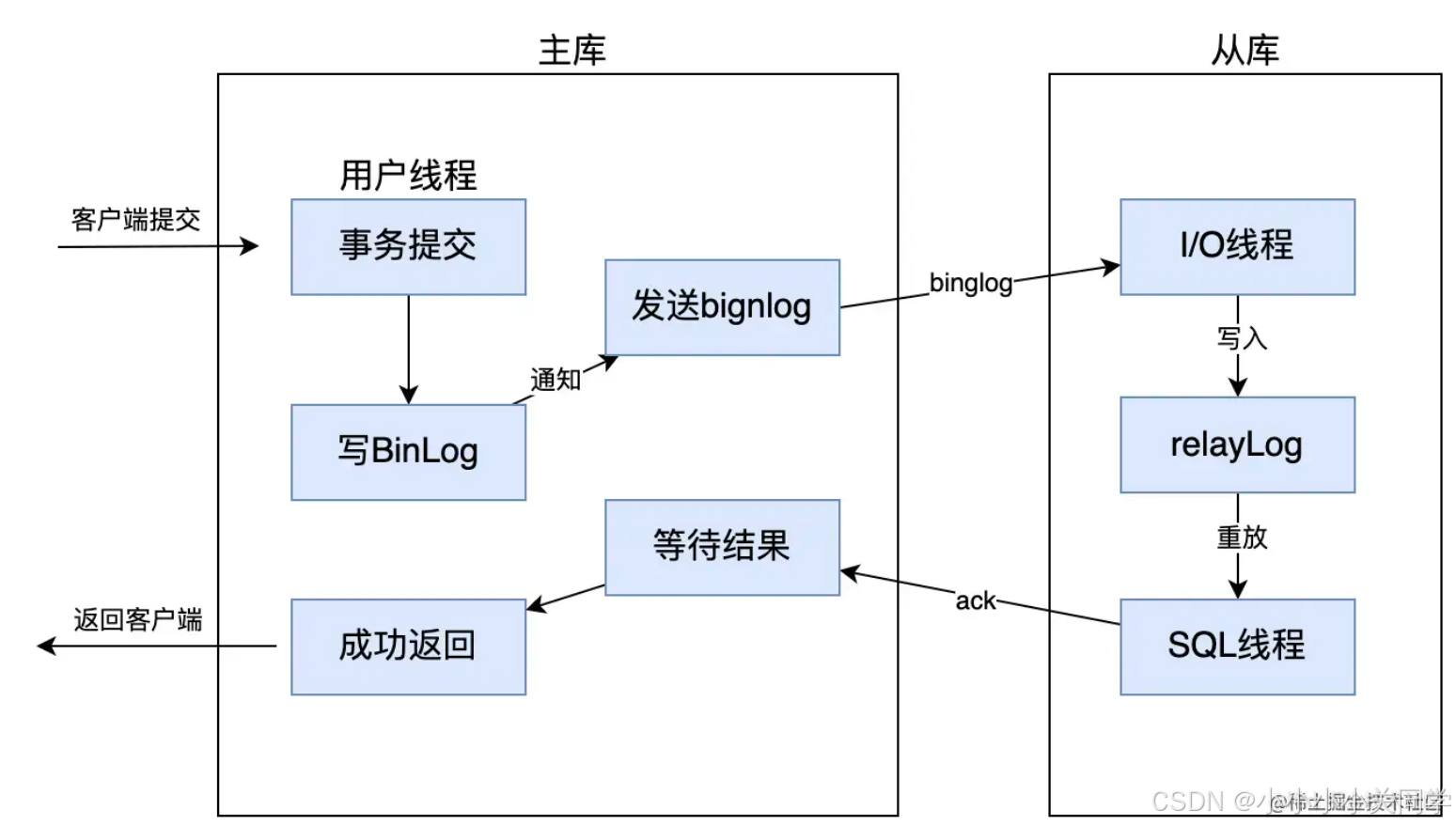
3.3 半同步复制
MySQL 5.5版本之后开始支持半同步复制的方式。原理是在客户端提交事务之后不直接将结果返回给客户端,而是等待至少有一个从库收到了 Binlog,并且写入到中继日志中,再返回给客户端。这样做的好处就是提高了数据的一致性,当然相比于异步复制来说,至少多增加了一个网络连接的延迟,降低了主库写的效率。
3.4 增强半同步复制
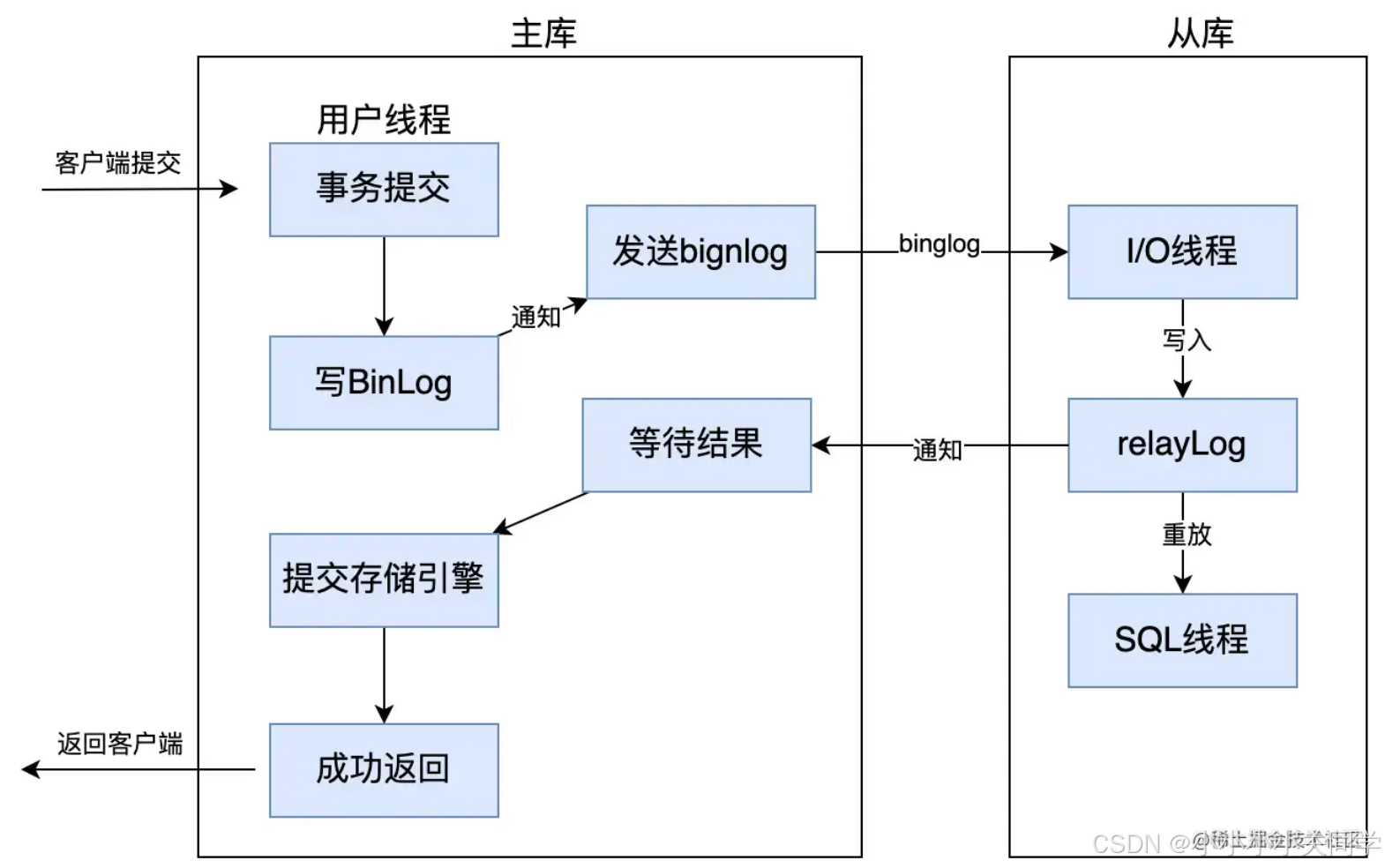
增强半同步复制,是 MySQL 5.7.2后的版本对半同步复制做的一个改进,原理上几乎是一样的,主要是解决幻读的问题。主库配置了参数 rpl semi sync master wait point=AFTER SYNC后,主库在存储引擎提交事务前,必须先收到从库数据同步完成的确认信息后,才能提交事务,以此来解决幻读问题。
4. 读写分离要注意的问题
分布式系统通过主从复制实现读写分离,解决了读和写操作的性能瓶颈问题,但同时也增加了整体的复杂性。我们看一下引入主从复制后,额外需要注意哪些问题。
4.1 主从复制下的延时问题
由于主库和从库是两个不同的数据源,主从复制过程会存在一个延时,当主库有数据写入之后,同时写入 binlog 日志文件中,然后从库通过 binlog 文件同步数据,由于需要额外执行日志同步和写入操作,这期间会有一定时间的延迟。特别是在高并发场景下,刚写入主库的数据是不能马上在从库读取的,要等待几十毫秒或者上百毫秒以后才可以。
在某些对一致性要求较高的业务场景中,这种主从导致的延迟会引起一些业务问题,比如订单支付,付款已经完成,主库数据更新了,从库还没有,这时候去从库读数据,会出现订单未支付的情况,在业务中是不能接受的。
为了解决主从同步延迟的问题,通常有以下几个方法。
- 敏感业务强制读主库
在开发中有部分业务需要写库后实时读数据,这一类操作通常可以通过强制读主库来解决
- 关键业务不进行读写分离
对一致性不敏感的业务,比如电商中的订单评论、个人信息等可以进行读写分离,对一致性要求比较高的业务,比如金融支付,不进行读写分离,避免延迟导致的问题。
4.2 主从复制如何避免丢数据
假设在数据库主从同步时,主库宕机,并且数据还没有同步到从库,就会出现数据丢失和不一致的情况,虽然这是一个极端场景,一般不会发生,但是 MySQL 在设计时还是考虑到了。
上面提到了主从复制模型的异步复制模型是mysql默认的复制模型,在该种模型下就会出现上述数据丢失的情况。我们应该采取全同步复制或者半同步复制方式。
在半同步复制模式下,主库需要等待至少一个从库完成同步之后,才完成写操作。主库在执行完客户端提交的事务后,从库将日志写入自己本地的 relay log 之后,会返回一个响应结果给主库,主库确认从库已经同步完成,才会结束本次写操作。相对于异步复制,半同步复制提高了数据的安全性,避免了主库崩溃出现的数据丢失,但是同时也增加了主库写操作的耗时。
全同步复制指的是在多从库的情况下,当主库执行完一个事务,需要等待所有的从库都同步完成以后,才完成本次写操作。全同步复制需要等待所有从库执行完对应的事务,所以整体性能是最差的。
总结
读写分离只是分布式性能优化的一个手段,不是任何读性能瓶颈都需要使用读写分离,除了读写分离,还可以进行分库分表,以及利用缓存,文件索引等 NoSQL 数据库来提高性能。
引用
2. https://juejin.cn/post/7269953746851266620