在矩阵中,若数值为0的元素数目远远多于非0元素的数目,并且非0元素分布没有规律时,则称该矩阵为稀疏矩阵。 ——来自百度百科。
为什么会用到稀疏矩阵,最近在做协同过滤算法时,调用评分图和信任图,数据的稀疏程度达到99.9%,这样的数据存储到内存中,0会占据大量的内存,本想无所谓,但奈何内存放不下这样的数据量,无奈进行稀疏矩阵的存储与计算。记录下学习笔记。
先举一个小栗子,展示双精度数据大小和内存之间的关系图
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 1e6, 10)
plt.plot(x, 8.0 * (x**2) / 1e6, lw=5)
plt.xlabel('size n')
plt.ylabel('memory [MB]')
plt.show()
显示结果

稀疏矩阵的存储:
稀疏矩阵作为一个矩阵,绝大多数都是0,为空。存储所有的0是浪费。
所以想办法进行压缩。节省大量内存空间。
稀疏矩阵的可视化图(样例):
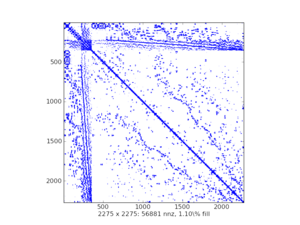
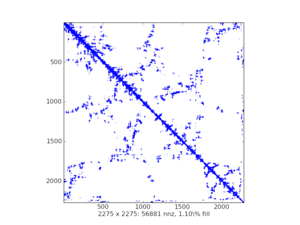
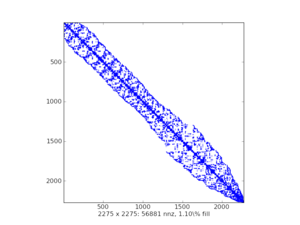
scipy.sparse中有七类稀疏矩阵:
csc_matrix: 压缩列格式
csr_matrix: 压缩行格式
bsr_matrix: 块压缩行格式
lil_matrix: 列表的列表格式
dok_matrix: 值的字典格式
coo_matrix: 座标格式 (即 IJV, 三维格式)
dia_matrix: 对角线格式
每一个类型适用于一些任务
许多都利用了由Nathan Bell提供的稀疏工具 C ++ 模块
-
- 算术操作的默认实现
- 通常转化为CSR
- 为了效率而子类覆盖
- 形状、数据类型设置/获取
- 非0索引
- 格式转化、与Numpy交互(toarray(), todense())
- ...
- 算术操作的默认实现
-
属性:
- mtx.A - 与mtx.toarray()相同
- mtx.T - 转置 (与mtx.transpose()相同)
- mtx.H - Hermitian (列举) 转置
- mtx.real - 复矩阵的真部
- mtx.imag - 复矩阵的虚部
- mtx.size - 非零数 (与self.getnnz()相同)
- mtx.shape - 行数和列数 (元组)
- 数据通常储存在Numpy数组中
对角线格式 (DIA)
形状 (n_diag, length) 的密集Numpy数组的对角线。固定长度距离当离主对角线比较远时会浪费空间。_data_matrix的子类 (带数据属性的稀疏矩阵类)
每个对角线的偏移:0 是主对角线,负偏移 = 下面,正偏移 = 上面
快速矩阵 * 向量 (sparsetools)(*代表矩阵相乘)
构建器接受 :1、密集矩阵 (数组);2、稀疏矩阵;3、形状元组 (创建空矩阵);4、(数据, 偏移) 元组
没有切片、没有单个项目访问
用法 : 通过有限微分解偏微分方程;有一个迭代求解器
举例DIA矩阵
【1】
import numpy as np
import scipy.sparse as sparse
import matplotlib.pyplot as plt
data = np.array([[1, 2, 3, 4]]).repeat(3, axis=0)
offsets = np.array([0, -1, 2])
mtx = sparse.dia_matrix((data, offsets), shape=(4, 4))
print(mtx)
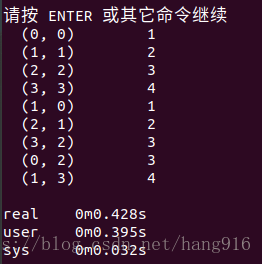

由此可以看出,mtx是一个4*4的矩阵,mtx的值,我是真不知道为什么,跪求高人指点,网友说看下面的图能看懂了,可能我脑回路有问题,我是真没看懂。

【2】右图为大神给的解释图,但是我还是有点问题


dia_matrix源码:

【3】矩阵相乘

列表格式(LIL)
基于行的连接列表。1、每一行是一个Python列表(排序的)非零元素的列索引;2、行存储在Numpy数组中 (dtype=np.object);3、非零值也近似存储
高效增量构建稀疏矩阵
构建器接受 :1、密集矩阵 (数组);2、稀疏矩阵;3、形状元组 (创建一个空矩阵)
举例LIL矩阵
【1】

【2】,更多的切片和索引


字典格式 (DOK)
Python字典的子类:1、键是 (行, 列) 索引元组 (不允许重复的条目);2、值是对应的非零值
高效增量构建稀疏矩阵
构建器支持:1、密集矩阵 (数组);2、稀疏矩阵;3、形状元组 (创建空矩阵)
高效 O(1) 对单个元素的访问
一旦创建完成后可以被高效转换为coo_matrix
算术很慢 (循环用dict.iteritems())
用法:当稀疏模式是未知的假设或改变时

座标格式 (COO)
称为 ‘ijv’ 或 ‘triplet’ 格式:1、三个NumPy数组: row, col, data;2、data[i]是在 (row[i], col[i]) 位置的值;3、允许重复值
构建稀疏矩阵的高速模式
构建器接受:1、密集矩阵 (数组);2、稀疏矩阵;3、形状元组 (创建空数组);4、(data, ij)元组
可以与CSR/CSC格式非常快的互相转换
快速的矩阵 * 向量 (sparsetools)
快速而简便的逐项操作:直接操作数据数组 (快速NumPy机制)
没有切片,没有算术 (直接)
使用:1、在各种稀疏格式间的灵活转换;2、当转化到其他形式 (通常是 CSR 或 CSC), 重复的条目被加总到一起
case【1】

行格式 (CSR)
面向行
三个Numpy数组: indices, indptr, data
- indices是列索引的数组
- data是对应的非零值数组
- indptr指向indices和data开始的行
- 长度是n_row + 1, 最后一个项目 = 值数量 = indices和data的长度
- 第i行的非零值是列索引为indices[indptr[i]:indptr[i+1]]的data[indptr[i]:indptr[i+1]]
- 项目 (i, j) 可以通过data[indptr[i]+k], k是j在indices[indptr[i]:indptr[i+1]]的位置来访问
快速矩阵向量相乘和其他算术 (sparsetools)
构建器接受:1、密集矩阵 (数组);2、稀疏矩阵;3、形状元组 (创建空矩阵);4、(data, ij) 元组;5、(data, indices, indptr) 元组
高效行切片,面向行的操作
较慢的列切片,改变稀疏结构代价昂贵
用途:
- 实际计算 (大多数线性求解器都支持这个格式)
case
【1】用(data, indices, indptr)元组创建:

解释下mtx.indptr,mtx.indices
# 对于第i行,非0数据列是indices[indptr[i]:indptr[i+1]] 数据是data[indptr[i]:indptr[i+1]]
# 第0行,有非0的数据列是indices[indptr[0]:indptr[1]] = indices[0:2] = [0,2]
# 数据是data[indptr[0]:indptr[1]] = data[0:2] = [1,2],所以在第0行第0列是1,第0行第2列是2
# 第1行,有非0的数据列是indices[indptr[1]:indptr[2]] = indices[2:3] = [2]
# 数据是data[indptr[1]:indptr[2] = data[2:3] = [3],所以在第1行第2列是3
# 第2行,有非0的数据列是indices[indptr[2]:indptr[3]] = indices[3:6] = [0,1,2]
# 数据是data[indptr[2]:indptr[3]] = data[3:6] = [4,5,6],所以在第2行第0列是4,第2行第1行是5,第2行第2列是6
【2】用(data, ij)元组创建:

列格式 (CSC) (与CSR类似)
三个Numpy数组: indices、indptr、data
- indices是行
- 索引的数组
- data是对应的非零值
- indptr指向indices和data开始的列
- 长度是n_col + 1, 最后一个条目 = 值数量 = indices和data的长度
- 第i列的非零值是行索引为indices[indptr[i]:indptr[i+1]]的data[indptr[i]:indptr[i+1]]
- 项目 (i, j) 可以作为data[indptr[j]+k]访问, k是i在indices[indptr[j]:indptr[j+1]]的位置
快速矩阵向量相乘和其他算术 (sparsetools)
构建器接受:1、密集矩阵 (数组);2、稀疏矩阵;3、形状元组 (创建空矩阵);4、(data, ij)元组;5、(data, indices, indptr)元组
高效列切片、面向列的操作
较慢的行切片、改变稀疏结构代价昂贵
用途:
- 实际计算 (巨大多数线性求解器支持这个格式)
case
【1】用(data, indices, indptr)元组创建:

解释下mtx.indptr,mtx.indices
# 对于第i列,非0数据行是indices[indptr[i]:indptr[i+1]] 数据是data[indptr[i]:indptr[i+1]]
# 第0列,有非0的数据行是indices[indptr[0]:indptr[1]] = indices[0:2] = [0,2]
# 数据是data[indptr[0]:indptr[1]] = data[0:2] = [1,2],所以在第0列第0行是1,第0列第2行是2
# 第1列,有非0的数据行是indices[indptr[1]:indptr[2]] = indices[2:3] = [2]
# 数据是data[indptr[1]:indptr[2] = data[2:3] = [3],所以在第1列第2行是3
# 第2列,有非0的数据行是indices[indptr[2]:indptr[3]] = indices[3:6] = [0,1,2]
# 数据是data[indptr[2]:indptr[3]] = data[3:6] = [4,5,6],所以在第2列第0行是4,第2列第1行是5,第2列第2行是6
【2】用(data, ij)元组创建:

块压缩行格式 (BSR)
CSR带有密集的固定形状的子矩阵而不是纯量的项目
块大小(R, C)必须可以整除矩阵的形状(M, N)
三个Numpy数组: indices、indptr、data
- indices是每个块列索引的数组
- data是形状为(nnz, R, C)对应的非零值
快速矩阵向量相乘和其他的算术 (sparsetools)
构建器接受:1、密集矩阵 (数组);2、稀疏矩阵;3、形状元组 (创建空的矩阵);4、(data, ij)元组;5、(data, indices, indptr)元组
许多对于带有密集子矩阵的稀疏矩阵算术操作比CSR更高效很多
用途:
- 类似CSR
case
【1】用(data, ij)元组创建:

【2】用块大小(data, indices, indptr)的元组创建:
