快速排序
本文先介绍一种分而治之(divide and conquer,D&C)的策略,应用这种类递归式的策略来进行快速排序。
分而治之
分而治之(D&C)的工作原理:
- 找出简单的基线条件;
- 确定如何缩小问题的规模,使其符合基线条件。
示例1:
Q:农场主的土地均匀的分成尽可能大的方块
A:在D&C策略指导下,问题分成两个步骤
1)找出基线条件;
2)不断将问题分解(或者说缩小规模),直到符合基线条件。
此处如何将问题分解呢?其实指的就是递归条件,长短边的相对关系在每次裁掉一个能裁的最大方块之后会发生变化,直至找到最终的方块(最大的)
欧几里得算法:“适用于这小块地的最大方块,也是适用于整块地的最大方块”。
详情请查看 可汗学院.
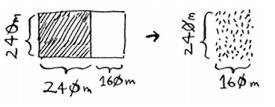
240 * 400,很自然的分成240240、160240
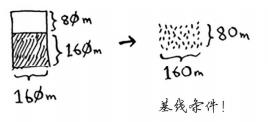
240*160继续分
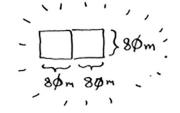
160 * 80 正好分成两个方块
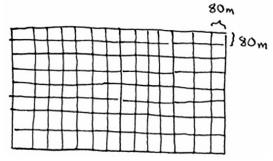
所以80 * 80 就是最大的方块
示例2:使用递归来执行求和操作
def sum(arr):
total = 0
for x in arr:
total += x
return total
print sum([1, 2, 3, 4])
函数运行过程如下:

一目了然
快速排序
引例
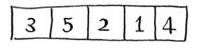
上述数组进行排序,根据不同的基准值选择,你可能有不同的花销
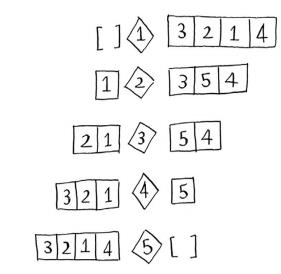
鉴于花销的不同,我们决定选择使用之前提过的二分查找方法来选择基准值。二分查找能够节省大量的时间,本文不再赘述。
代码如下
if len(array) < 2:
return array
else:
pivot = array[0]
less = [i for i in array[1:] if i <= pivot]
greater = [i for i in array[1:] if i > pivot]
return quicksort(less) + [pivot] + quicksort(greater)
print quicksort([10, 5, 2, 3])
小结
D&C将问题逐步分解。使用D&C处理列表时,基线条件很可能是空数组或只包含一个元
素的数组。
实现快速排序时,请随机地选择用作基准值的元素。快速排序的平均运行时间为O(n log n)。
大O表示法中的常量有时候事关重大,这就是快速排序比合并排序快的原因所在。
比较简单查找和二分查找时,常量几乎无关紧要,因为列表很长时,O(log n)的速度比O(n)
快得多
附表
| 排序方法 | 平均时间复杂度 |
|---|---|
| 直接插入 | O(n^2) |
| shell排序 | O(n^1.3) |
| 直接选择 | O(n^2) |
| 堆排序 | O(n log 2(n) ) |
| 冒泡排序 | O(n^2) |
| 快速排序 | O(n log 2(n) ) |
| 归并排序 | O(n log 2(n) ) |