本文完全基于李航老师的《统计学习方法第2版》
前言
先介绍一下HMM隐式马尔科夫主要解决三大基本问题:
1.概率计算问题(已知模型参数,观测序列出现的概率):
- 直接计算法,复杂度为 O ( T N T ) O(TN^T) O(TNT),不实际
- 前向算法,复杂度为 O ( T N 2 ) O(TN^2) O(TN2)
- 后向算法
2.学习问题(已知观测序列,估计模型参数)
- 监督学习方法:计算简单,但需要大量的人工标注
- 无监督学习方法(Baum-Welch算法)
3.预测问题(已知观测序列,估计状态序列)
- 近似算法:贪心算法,获得每一个时刻t的最大概率的状态,只是考虑了局部的最优,很难得到全局最优解
- 维特比算法
维特比算法
维特比算法就是一个动态规划算法,本质是填表。考虑时间序列长度为T,可能的状态为N,算法的过程其实就是填满N*T这一大小的表。下面我们一起来结合实例,填完这个表。
考虑如下问题:

A是状态转移矩阵,B是由状态得观测的矩阵,Π是初始状态向量。故,有3个状态(N=3),又观测序列长度为3(T=3),所以我们要填一个3*3的表格。
第一步:初始化
时间1时,根据下式得到三个状态下各自的概率(视作最优)
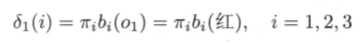
填入表格:
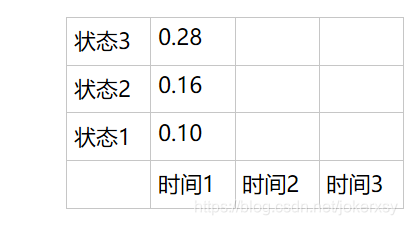
第二步:向下递推
时间2时,有三种可能的状态,考虑时间1时的三种情况与当前时间的组合,求得时间2时,三种状态下的最大概率,公式如下:
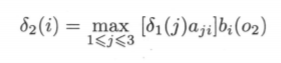
其中,当前时间,选取状态为1的概率计算如下:
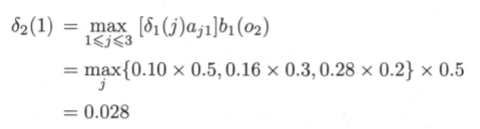 也就是说,当上一时间状态为3时,当前状态为1的可能性最大。
也就是说,当上一时间状态为3时,当前状态为1的可能性最大。
所有结果填入表格:
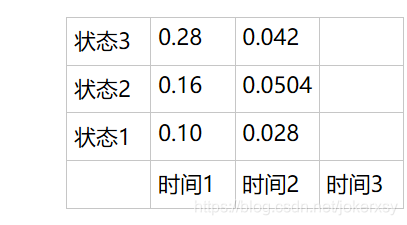
时间3时,同样根据时间2的三种情况,考虑三种情况与当前时间三种状态的组合,分别得到最大的概率(公式不变):
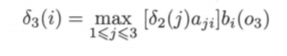
填入表格
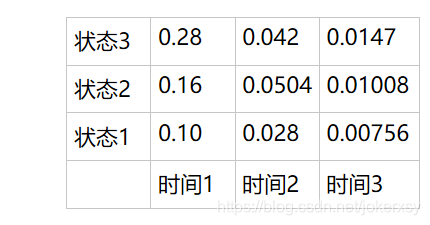
第三步:得到最优路径的概率和终点
显然,最优路径的概率为0.0147,终点是状态3.
第四步:逆向得到完整的状态序列
其实,我们得到的完整路径如下:
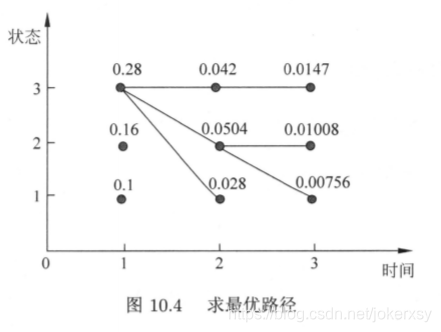
也就是说,时间1时,三个初始化概率分别为0.28、0.16、0.1;紧接着,时间2的三种状态的最大概率都是基于时间1为状态3;时间3的三种状态的最大概率中的最大为0.0147,它基于时间2为状态3。
我们在填表的过程中,也要记录这一信息,很简单,同时再维护一个数组D即可:
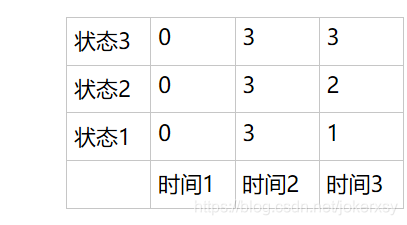
解释:第一步初始化时,全填0,第二步递推时,填剩下。
我们已经在第三步中得到终点(t=3)的状态为3,t=2时的状态为D(3,3) = 3,t=1时的状态为D(2,3)=3。
所以最后的状态序列为:[3,3,3]。
后记
完全就是一个动态规划,并把最优解给重构了。
HMM、CRF都可以用作序列标注的问题。其中,输入的单词序列是观测序列;输出的标签序列是状态序列。由于状态序列不仅和观测序列有关,根据马尔可夫性质,两两状态之间也有一定的关联,所以可以增加一定的性能。
这些模型可以精确地考虑标签之间的依赖,这是神经网络如RNN和CNN等所做不到的。但神经网络可以无限的深,能够很好的抽取特性,所以我们可以integrate them:
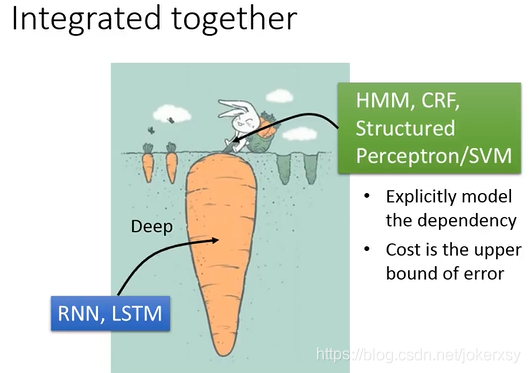
神经网络,仅仅考虑了观测序列与状态序列之间的关系,讲其输出进一步放入HMM、CRF等,进一步考虑状态与状态之间的关系。