map:
val streamMap = stream.map { x=> x*2}
flatMap
也就是将嵌套集合转换并平铺成非嵌套集合
例如: 一个List想要打散按照空格分隔提取数据可以这样做:
List("a b", "c d").flatMap(line => line.split(" "))
最终结果是: List(a,b,c,d
val streamFlatMap = stream.flatMap{
x => x.split(" ")
}
filter
就是做过滤的类似if,给一个lambda表达式,返回的就是一个bool类型的值,根据最终结果是否为true来判断当前结果是否保留
val streamFilter = stream.filter{
x => x == 1
}
KeyBy 
先分组再做聚合
DataStream -> KeyedStream: 逻辑的将一个流拆分成不相交的分区,每个分区包含具有相同的key元素,在内部以hash的形式实现的。
滚动聚合算子(Rolling Aggregation)
这些算子可以针对KeyedStream的每一个支流做聚合。
sum()
min()
max()
minBy()
maxBy()
Reduce
Split和Select
Split
DataStream -> SplitStream: 根据某些特征,把一个DataStram拆分成两个或多个DataStream
Select
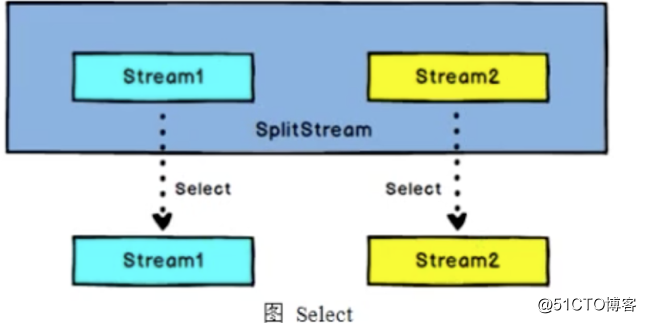
SplitStream->DataStream: 从一个SplitStream中获取一个或多个DataStream。
需求: 传感器数据按照温度高低(以30度为界),拆分成两个流。
Connect和CoMap
流合并,但只是把2条流合并为一条流的形式,具体合并后的2个流还是独立的,互不影响
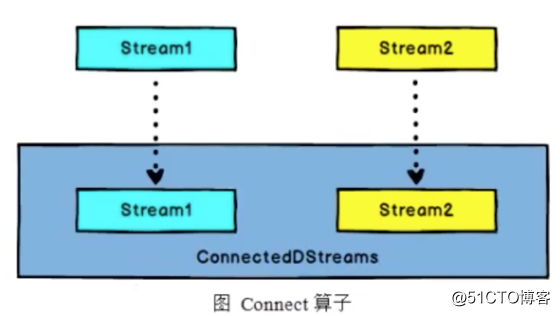
DataStream,DataStream -> ConnectedStreams: 连接两个保持他们类型的数据流,两个数据流被Connect之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。
CoMap,CoFlatMap
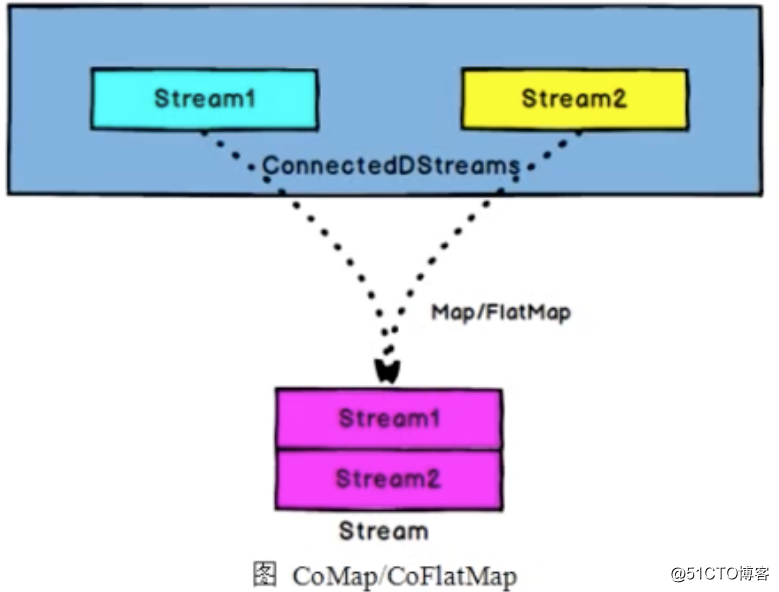
ConnectedStreams -> DataStream:作用于ConnectedStreams上,功能与map和flatMap一样,对ConnectedStreams中的每一个Stream分别进行map和flatMap处理。
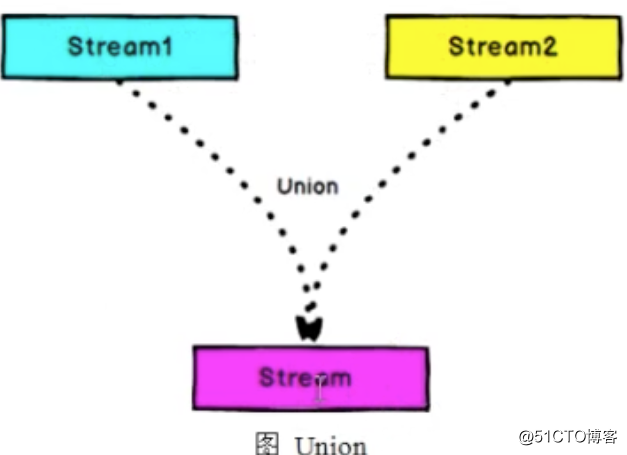
Union
流合并,是直接把2条流数据合并成为一条流,要求两条流的数据必须保持一致,否则不能用
环境:
新建包,com.mafei.apitest,新建一个scala Object类,TransformTest
package com.mafei.apitest
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, createTypeInformation}
//获取传感器数据
case class SensorReadingTest(id: String,timestamp: Long, temperature: Double)
object TransformTest {
def main(args: Array[String]): Unit = {
//创建执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val inputStream= env.readTextFile("/opt/java2020_study/maven/flink1/src/main/resources/sensor.txt")
env.setParallelism(1)
// inputStream.print()
//先转换成样例类类型
val dataStream = inputStream
.map(data =>{
val arr = data.split(",") //按照,分割数据,获取结果
SensorReadingTest(arr(0), arr(1).toLong,arr(2).toDouble) //生成一个传感器类的数据,参数中传toLong和toDouble是因为默认分割后是字符串类别
})
/**
* dataStream.print() 输出样例
1> SensorReadingTest(sensor4,1603766240,40.1)
4> SensorReadingTest(sensor4,1603766284,44.0)
2> SensorReadingTest(sensor1,1603766281,41.0)
3> SensorReadingTest(sensor3,1603766283,43.0)
2> SensorReadingTest(sensor2,1603766282,42.0)
*/
//分组聚合,输出每个传感器当前最小值
val aggStream = dataStream
.keyBy("id") //根据id来进行分组
// .min("temperature") //获取每一组中temperature 为最小的数据
.min("temperature") //获取每一组中temperature 为最小的数据
/**
aggStream.print()
1> SensorReadingTest(sensor1,1603766281,41.0)
2> SensorReadingTest(sensor3,1603766283,43.0)
4> SensorReadingTest(sensor2,1603766282,42.0)
1> SensorReadingTest(sensor4,1603766240,40.1) // 所有sensor的数据只会输出最小的值
1> SensorReadingTest(sensor4,1603766240,40.1) // 所有sensor的数据只会输出最小的值
*/
//需要输出当前最小的温度值,以及最近的时间戳,要用到reduce
val resultStream = dataStream
.keyBy("id")
// .reduce((curState, newData)=>{
// SensorReadingTest(curState.id,newData.timestamp, curState.temperature.min(newData.timestamp))
// })
.reduce( new MyreduceFunction) //如果不用上面的lambda表达式,也可以自己写实现类,一样的效果,二选一
/**
print(resultStream.print())
SensorReadingTest(sensor2,1603766282,42.0)
SensorReadingTest(sensor3,1603766283,43.0)
SensorReadingTest(sensor4,1603766240,40.1)
SensorReadingTest(sensor4,1603766284,40.1) //可以看到虽然sensor4的时间戳还是在更新,但是temperature 一直是最小的一个
SensorReadingTest(sensor4,1603766249,40.1)
*/
// 多流转换操作
//分流,将传感器温度数据分成低温、高温两条流
val splitStream = dataStream
.split(data =>{
if (data.temperature > 30.0 ) Seq("high") else Seq("low")
})
val highStream = splitStream.select("high")
val lowStream = splitStream.select("low")
val allStream = splitStream.select("high", "low")
/**
*
* 数据输出样例: 大于30的都在high里面,小于30都在low
* highStream.print("high")
* lowStream.print("low")
* allStream.print("all")
*
* all> SensorReadingTest(sensor1,1603766281,41.0)
* high> SensorReadingTest(sensor1,1603766281,41.0)
* all> SensorReadingTest(sensor2,1603766282,42.0)
* high> SensorReadingTest(sensor2,1603766282,42.0)
* all> SensorReadingTest(sensor4,1603766284,20.0)
* low> SensorReadingTest(sensor4,1603766284,20.0)
* all> SensorReadingTest(sensor4,1603766249,40.2)
* high> SensorReadingTest(sensor4,1603766249,40.2)
* all> SensorReadingTest(sensor3,1603766283,43.0)
* high> SensorReadingTest(sensor3,1603766283,43.0)
* all> SensorReadingTest(sensor4,1603766240,40.1)
* high> SensorReadingTest(sensor4,1603766240,40.1)
*/
//合流,connect
val warningStream = highStream.map(data =>(data.id, data.temperature))
val connectedStreams = warningStream.connect(lowStream)
//用coMap对数据进行分别处理
val coMapResultStream = connectedStreams
.map(
warningData =>(warningData._1,warningData._2,"warning"),
lowTempData => (lowTempData.id, "healthy")
)
/**
* coMapResultStream.print()
*
* (sensor1,41.0,warning)
* (sensor4,healthy)
* (sensor2,42.0,warning)
* (sensor4,40.2,warning)
* (sensor3,43.0,warning)
* (sensor4,40.1,warning)
*/
env.execute("stream test")
}
}
class MyreduceFunction extends ReduceFunction[SensorReadingTest]{
override def reduce(t: SensorReadingTest, t1: SensorReadingTest): SensorReadingTest =
SensorReadingTest(t.id, t1.timestamp, t.temperature.min(t1.temperature))
}
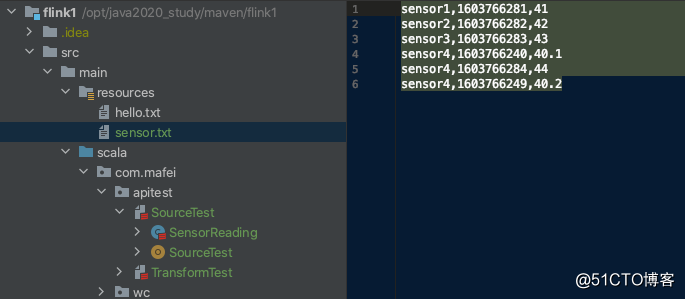
用到的数据 sensor.txt
sensor1,1603766281,41
sensor2,1603766282,42
sensor3,1603766283,43
sensor4,1603766240,40.1
sensor4,1603766284,44
sensor4,1603766249,40.2
最终的代码结构: