Flink提供了Table形式和DataStream两种形式,可以根据实际情况自己选择用哪些方式来实现,但实际开发过程中可能会有需求两种形式互相转换,这里介绍下操作方法
表可以转换为DataStream或DataSet,这样自定义流处理或批处理程序就可以继续在Table API或SQL查询的结果上运行了
将表转换为DataStream或DataSet时,需要指定生成的数据类型,即要将表的每一行转换成的数据类型
表作为流式查询的结果,是动态更新的
转换有两种转换模式: 追加(Appende)模式和撤回(Retract)模式
查看执行计划
Table API提供了一种机制来解释计算表的逻辑和优化查询计划
查看执行计划,可以通过TableEnvironment.explain(table)方法或TableEnvironment.explain()方法完成,返回一个字符串,描述三个计划
优化的逻辑查询计划
优化后的逻辑查询计划
实际执行计划
val explaination: String = tableEnv.explain(resultTable)
println(explaination)
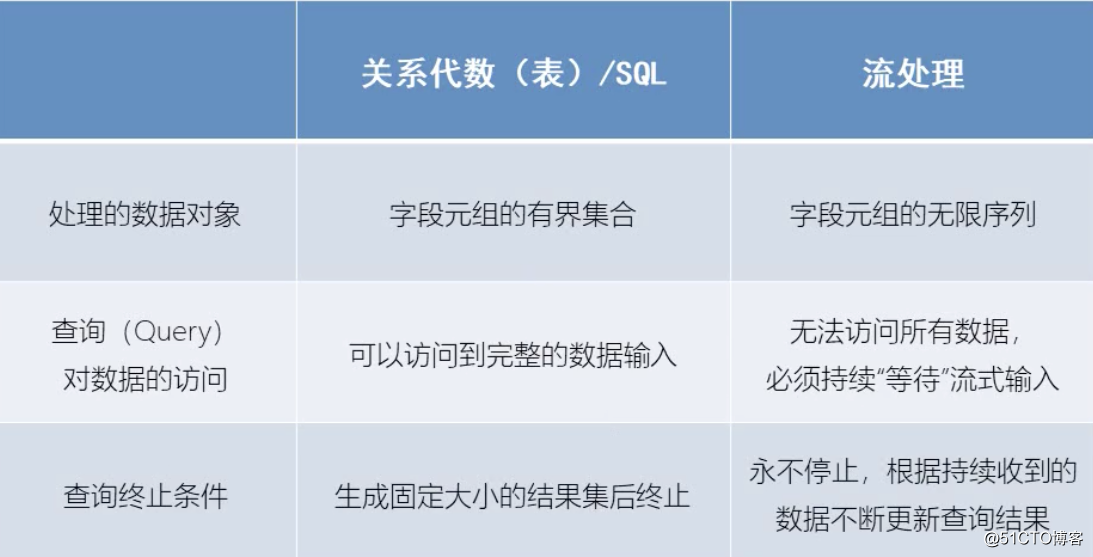
流处理和关系代数的区别
动态表(Dynamic Tables)
动态表是Flink对流数据的Table API和SQL支持的核心概念
与批处理数据的静态表不同,动态表是随时间变化的
持续查询(Continuous Query)
动态表可以像静态的批处理表 一样进行查询,查询一个动态表会产生持续查询(Continuous Query)
连续查询永远不会终止,并会生成另一个动态表
查询会不断更新其动态结果表,以反映其动态输入表上的改动
动态表和持续查询的转换过程
1) 首先输入的流会被转换为动态表,这个动态表只会一直追加
2)对动态表计算连续查询,生成新的动态表
针对之前查询的结果加一个状态,这样子就不用每次从头开始查询,提升效率
3)生成的新的动态表被转换成流然后输出
将流转换成动态表
为了处理带有关系查询的流,必须先将其转换为表
从概念上讲,流的每个数据记录,都被解释为对结果表的插入修改操作
第一个场步,读取访问日志,每来一条数据就插入一次
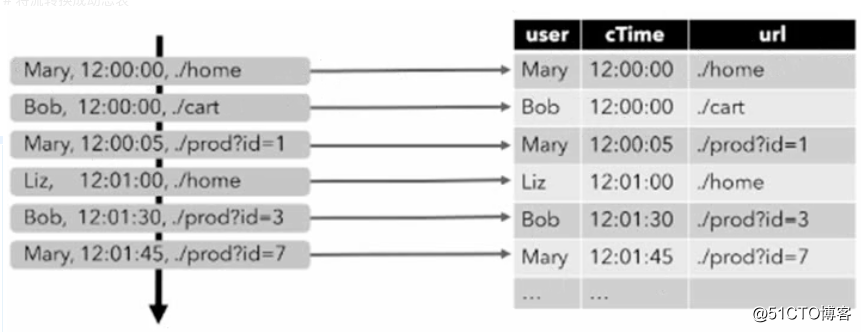
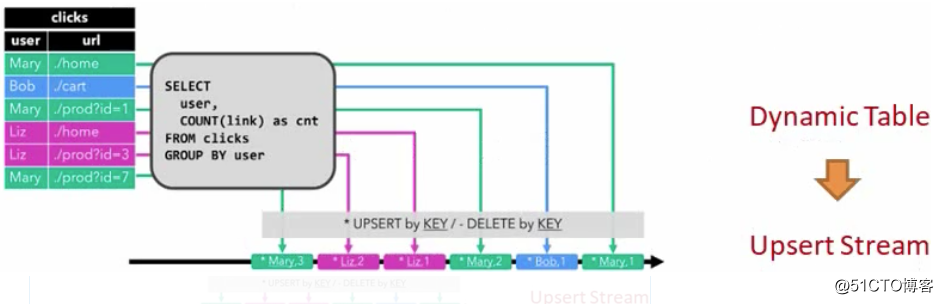
持续查询栗子,统计每一个用户点击了多少次
持续查询会在动态表上做计算处理,并作为结果生成新的动态表
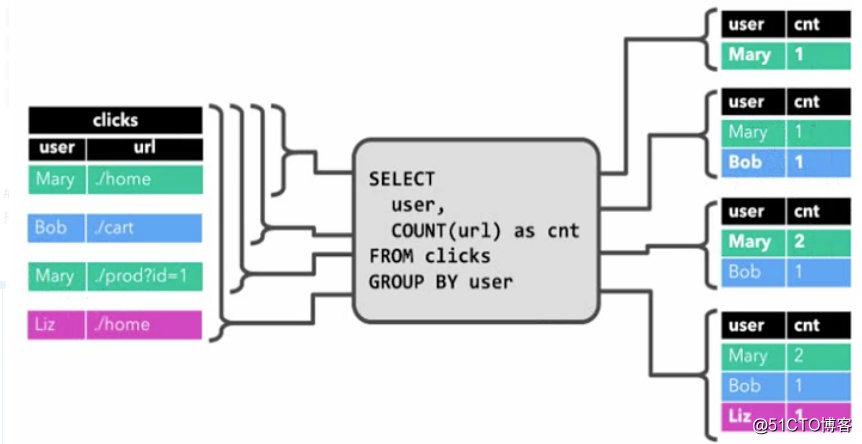
最后一步,将动态表转换成DataStream
与常规的数据库表一样,动态表可以通过插入(insert)、更新(update)和删除(delete)更改,进行持续的修改
将动态表转换为流或将其写入外部系统时,需要对这些更改进行编码
1,仅追加流(Append-only)
- 仅通过插入(insert)更改来修改的动态表,可以直接转换为仅追加流
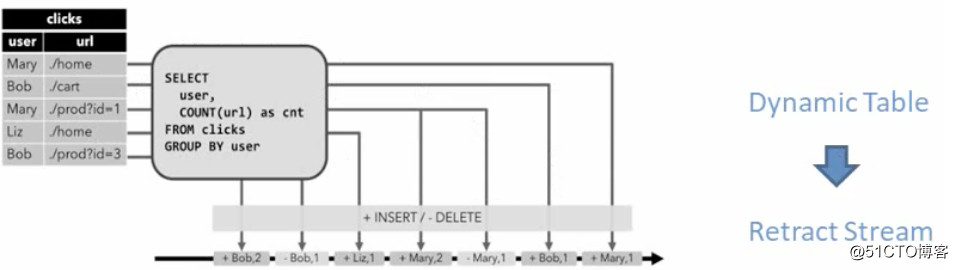
2,撤回流(Retract) - 撤回流是包含两类消息的流: 添加(add)消息和撤回(Retract)消息
3,更新插入流(Upsert) - Upsert流也包含两种类型的消息: Upsert消息和删除(Delete)消息。
将动态表转换成DataStream
Retract操作,每新增一个是insert+操作,撤回一个是delete - 操作,
这里当Mary第一次来的时候,会有一个insert,当Mary第二次来的时候会触发两个操作,Insert和delete,增加一个mary2, 删掉mary1
时间特性(Time Attributes)
基于时间的操作(比如Table API和SQL中的窗口操作),需要定义相关的时间语义和事件数据来源的信息
Table可以提供一个逻辑上的时间字段,用于在表处理程序中,指示时间和访问相应的时间戳
时间属性,可以是每个schema的一部分。一旦定义了时间属性,它就可以作为一个字段引用,并且可以在基于时间的操作中使用
时间属性的行为类似于常规时间戳,可以访问,并且进行计算
定义处理时间 (Processing Time)
处理时间语义下,允许表处理程序根据机器的本地时间生成结果。他是时间最简单的概念,既不需要提取时间戳,也不需要生成watermark
几种定义的方法:
1、由DataStream转换成表时指定(最简单的一种)
在定义schema期间,可以使用.proctime,指定字段名定义处理时间字段
这个proctime属性只能通过附加逻辑字段,来拓展物理schema,因此只能在schema定义的末尾定义它
val sensorTables = tableEnv.fromDataStream(dataStream, 'id,'temperature,'timestamp, 'pt.proctime)增加pom.xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.10.1</version>
</dependency>
栗子:
package com.mafei.apitest.tabletest
import com.mafei.sinktest.SensorReadingTest5
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api._
import org.apache.flink.table.api.scala._
import org.apache.flink.types.Row
object TimeAndWindowTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) //设置1个并发
//设置处理时间为流处理的时间
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
val inputStream = env.readTextFile("/opt/java2020_study/maven/flink1/src/main/resources/sensor.txt")
//先转换成样例类类型
val dataStream = inputStream
.map(data => {
val arr = data.split(",") //按照,分割数据,获取结果
SensorReadingTest5(arr(0), arr(1).toLong, arr(2).toDouble) //生成一个传感器类的数据,参数中传toLong和toDouble是因为默认分割后是字符串类别
})
//设置环境信息(可以不用)
val settings = EnvironmentSettings.newInstance()
.useBlinkPlanner() // Flink 10的时候默认是用的useOldPlanner 11就改为了BlinkPlanner
.inStreamingMode()
.build()
// 设置flink table运行环境
val tableEnv = StreamTableEnvironment.create(env, settings)
//流转换成表
val sensorTables = tableEnv.fromDataStream(dataStream, 'id, 'timestamp,'temperature,'pt.proctime)
sensorTables.printSchema()
sensorTables.toAppendStream[Row].print()
env.execute()
}
}
代码结构及运行效果: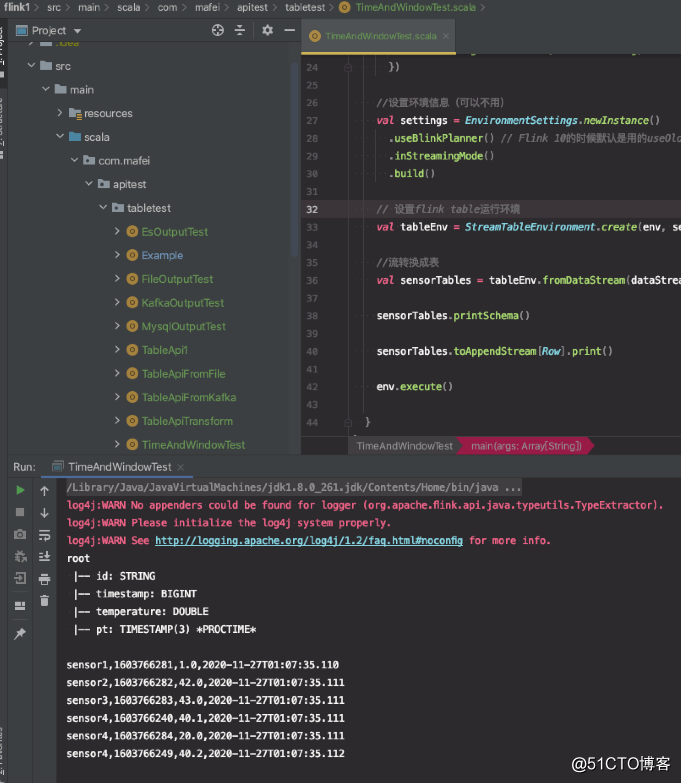
第二种,定义处理时间(Processing Time)
val filePath = "/opt/java2020_study/maven/flink1/src/main/resources/sensor.txt"
tableEnv.connect(new FileSystem().path(filePath))
.withFormat(new Csv()) //因为txt里头是以,分割的跟csv一样,所以可以用oldCsv
.withSchema(new Schema() //这个表结构要跟你txt中的内容对的上
.field("id", DataTypes.STRING())
.field("timestamp", DataTypes.BIGINT())
.field("tem", DataTypes.DOUBLE())
.field("pt", DataTypes.TIMESTAMP(3))
.proctime() //需要注意,只有输出的sink目标里面实现了DefineRowTimeAttributes才能用,否则会报错,文件中不能,但kafka中是可以用的
).createTemporaryTable("inputTable")
第三种,定义处理时间(Processing Time)另一种实现,必须使用blink引擎
val sinkDDlL: String =
"""
|create table dataTable(
| id varchar(20) not null
| ts bigint,
| temperature double,
| pt AS PROCTIME()
|) with (
| 'connector.type' = 'filesystem',
| 'connector.path' = '/sensor.txt',
| 'format.type' = 'csv'
|)
|""".stripMargin
tableEnv.sqlUpdate(sinkDDlL)
定义事件时间(Event Time)
这种就不是flink从本地取处理时间了,而是取事件中的时间来处理
事件时间语义,允许表处理程序根据每个记录中包含的时间生成结果。这样子即使在乱序事件或者延迟事件时,也可以获得正确的结果。
为了处理无序事件,并区分流中的准时和迟到事件;Flink需要从事件数据中,提取时间戳,并用来推进事件时间的进展
定义事件时间有3种方式
第一种,由DataStream转换成表时指定
在DataStream转换成Table,使用rowtime可以定义事件时间属性
//先转换成样例类类型
val dataStream = inputStream
.map(data => {
val arr = data.split(",") //按照,分割数据,获取结果
SensorReadingTest5(arr(0), arr(1).toLong, arr(2).toDouble) //生成一个传感器类的数据,参数中传toLong和toDouble是因为默认分割后是字符串类别
}).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReadingTest5](Time.seconds(1000L)) {
override def extractTimestamp(t: SensorReadingTest5): Long =t.timestamp * 1000L
}) //指定watermark
//流转换成表,指定处理时间-上面的实现方式
// val sensorTables = tableEnv.fromDataStream(dataStream, 'id, 'timestamp,'temperature,'pt.proctime)
//将DataStream转换为Table,并指定事件时间字段
val sensorTables = tableEnv.fromDataStream(dataStream, 'id, 'timestamp.proctime,'temperature)
//将DataStream转换为Table,并指定事件时间字段-直接追加字段
val sensorTables = tableEnv.fromDataStream(dataStream,"id","temperature","timestamp","rt".rowtime)
第二种,定义Table Schema时指定
val filePath = "/opt/java2020_study/maven/flink1/src/main/resources/sensor.txt"
tableEnv.connect(new FileSystem().path(filePath))
.withFormat(new Csv()) //因为txt里头是以,分割的跟csv一样,所以可以用oldCsv
.withSchema(new Schema() //这个表结构要跟你txt中的内容对的上
.field("id", DataTypes.STRING())
.field("tem", DataTypes.DOUBLE())
.rowtime(
new Rowtime()
.timestampsFromField("timestamp") //从数据字段中提取时间戳
.watermarksPeriodicBounded(2000) //watermark延迟2秒
)
).createTemporaryTable("inputTable")
在创建表的DDL中定义
//在创建表的DDL中定义
val sinkDDlL: String =
"""
|create table dataTable(
| id varchar(20) not null
| ts bigint,
| temperature double,
| rt AS TO_TIMESTAMP( FROM_UNIXTIME(ts)),
| watermark for rt as rt - interval '1' second //基于ts减去1秒生成watermark,也就是watermark的窗口时1秒
|) with (
| 'connector.type' = 'filesystem',
| 'connector.path' = '/sensor.txt',
| 'format.type' = 'csv'
|)
|""".stripMargin
tableEnv.sqlUpdate(sinkDDlL)
Flink 窗口
时间语义需要配合窗口操作才能发挥真正的作用,
在Table ApI和SQL中,主要有两种窗口
Group Windows (分组窗口)
先定义组长什么样子,在根据key进行groupby,最后一步执行聚合函数
根据时间或行计数间隔,将行聚合到有限的组(Group)中,并对每个组的数据执行一次聚合函数
Group Windows是使用window(w:GroupWindow)子句定义的,并且必须由as子句制定一个别名.
为了按照窗口对表进行分组,窗口的别名必须在group by子句中,像常规的分组字段一样引用
val table = input
.window([w;: GroupWindow] as 'w) //定义窗口,别名为w
.groupBy('w,'a) //按照字段a和窗口w分组
.select('a,'b.sum) //聚合操作
Table API提供了一组具有特定语义的预定义window类,这些类会被转换为底层DataStream或DataSet的窗口操作
滚动窗口(Tumbling windows)
滚动窗口要用Tumble类来定义
//定义事件时间的滚动窗口(Tumbling Event-time window
.window(Tumble over 10.minutes on 'rowtime as 'w)
//定义处理时间的滚动窗口(Tumbling Processing-time window)
.window(Tumble over 10.minutes on 'proctime as 'w)
//定义数据数量的滚动窗口(Tumbling Row-count window)
.window(Tumble over 10.rows on 'proctime as 'w)
滑动窗口(Sliding windows)
10分钟一个滑动窗口,每5分钟滑动一次
//Sliding Event-time window
.window(Slide over 10.minutes every 5.minutes on 'rowtime as 'w)
//Sliding Processing-time window
.window(Slide over 10.minutes every 5.minutes on 'proctime as 'w)
//Sliding Row-count window
.window(Slide over 10.minutes every 5.rows on 'proctime as 'w)
会话窗口(Session windows)
会话窗口要用Session类来定义
//Sesion Evnet-time Window
.window(Session withGap 10.minutes on 'rowtime as 'w)
//Session Processing-time Window
.window(Session withGap 10.minutes on 'procetime as 'w)
SQL中的Group Windows
Group Windows定义在SQL查询的Group By子句中
TUMBLE(time_attr, interval)
定义一个滚动窗口,第一个参数是时间字段,第二个参数是窗口长度
HOP(time_attr,interval,interval)
定义的一个滑动窗口,第一个参数是时间字段,第二个参数是窗口滑动步长,第三个是窗口长度
SESSION(time_attr, interval)
定义一个会话窗口,第一个参数是时间字段,第二个参数是窗口间隔
Over Windows
针对每个输入行,计算相邻行范围内的聚合