对于Flink来说,Watermark是个很难绕过去的概念,有的翻译为水位线,有的翻译为水印,都是同一个东西,
watermark是一种衡量Event Time进展的机制,它是数据本身的一个隐藏属性。通常基于Event Time的数据,自身都包含一个timestamp.watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用watermark机制结合window来实现。
流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的。虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、背压等原因,导致乱序的产生(out-of-order或者说late element)。
但是对于late element,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark。
设置watermark最大的作用其实就是为了解决数据乱序问题
假设10分钟发一班车,8点一班,8点10分一班,设置watermark后,8点这一班的实际会在8点10分全部发出去,会自动设置延迟
Watermark的特点
以当前最大的时间戳,减去固定的延迟作为watermark的时间戳,
也是就是每条数据出来都会算下,所有数据里面最大的那个值,再减去固定的延迟
个人理解不一定对: 以这个为例:watermark为2,当看到5的时候,watermark是5-2=3,假设桶设置的4,那么0-4的桶就不会关闭,继续往下走
下一个数字3,发现最大数还是5,那5-2=3,0-4的桶还是不动,当走到6的时候,最大是6,那6-2=4,这时候0-4的桶就会关掉了,以此类推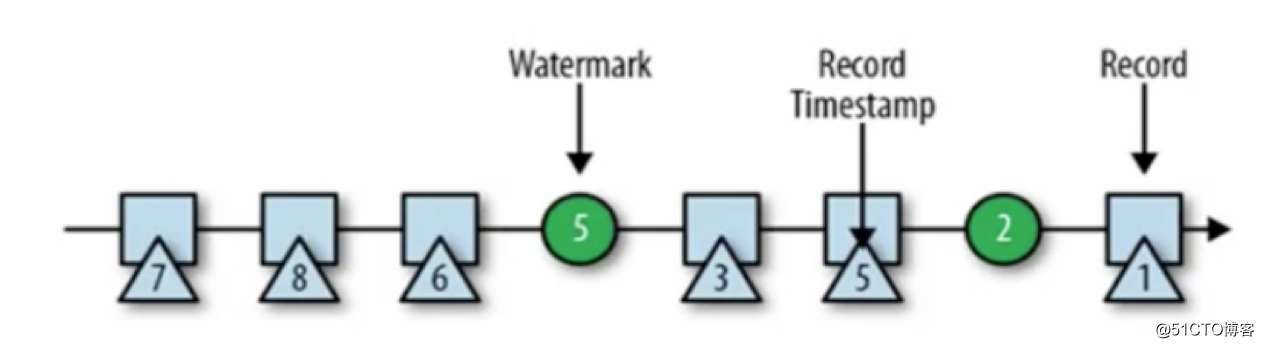
watermark是一条特殊的数据记录
watermark必须单调递增,以确保任务的事件时间时钟在向前推进,而不是在后退
watermark与数据的时间戳相关
watermark传递
上游向下游传递的时候会把watermark广播出去,
下游可能会接收到多个上游的watermark数据,会在内部建立一个分区watermark,以最小的数据作为最终的watermark
比如上游有3个数据源,输出的watermark分别为4,3,5 那么在下游会把3个数据全部接收到,最终输出最小的为自己的watermark也就是3
下面这个例子,有4个上游数据,watermark分为是4,7,6,6,分区数据watermark数据是2,4,3,6
第一张图: 当上游第1,2,3个数据都没来的时候,所有分区数据最小的是2,所以输出当前事件时间时间为2
第二张图:上游第1个数据来了,也就是4数据把原来的2覆盖了,这时候数据变成了4,4,3,6 最小的数据变成3,所以输出当前事件时间为3
第三张图:上游第2个数据7来了,也就是7把原来的4覆盖了,这时候数据变成了4,7,3,6 最小的数据还是3,所以输出当前事件时间还是3
第四张图:上游第3个数据6来了,也就是6把3给覆盖了,这时候数据变成了4,7,6,6 最小的数据变成了4,所以输出当前事件时间是4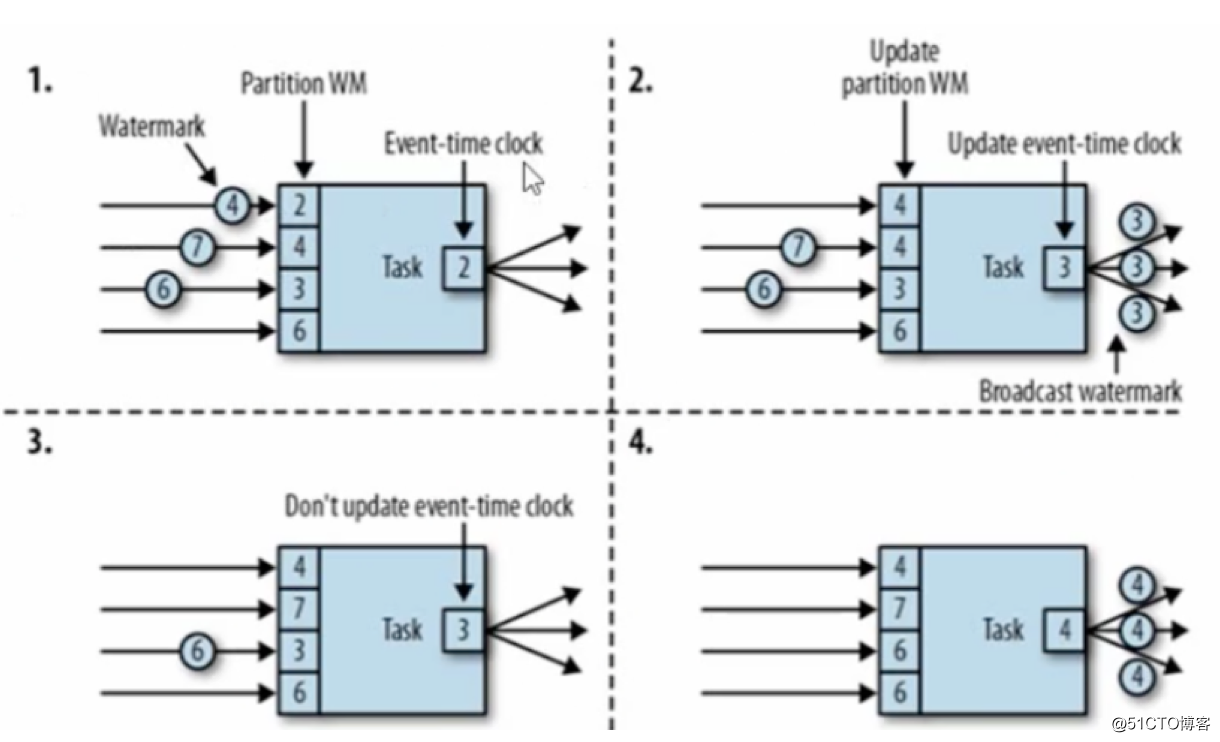
watermark的引入
Event Time的使用一定要指定数据源中的时间戳
调用assignTimestampAndWatermarks方法,传入一个BoundedOutOfOrdernessTimestampExtractor,就可以指定watermark
//先转换成样例类类型
val dataStream = inputStream
.map(data => {
val arr = data.split(",") //按照,分割数据,获取结果
SensorReadingTest5(arr(0), arr(1).toLong, arr(2).toDouble) //生成一个传感器类的数据,参数中传toLong和toDouble是因为默认分割后是字符串类别
})
// .assignAscendingTimestamps(_.timestamp ) //这种是当时间肯定是按照时间排序的,没有乱序的情况,升序提取时间戳(如果数据中timestamp为秒,可以*1000L转为毫秒)
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReadingTest5](Time.seconds(3)) { // 指定乱序最大等3
override def extractTimestamp(t: SensorReadingTest5): Long = t.timestamp * 1000L //指定watermark的字段
})
watermark的设定
在Flink中,watermark由应用开发人员生成,这通常需要对对应的领域有一定的了解
如果watermark设置的延迟太久,收到结果的速度可能就会很慢,解决办法是在水位线到达之前输出一个近似结果
而如果watermark到达得太早,则可能收到错误结果,不过flink处理迟到数据的机制可以解决这个问题
周期性水印(With Periodic Watermarks)
AssignerWithPeriodicWatermarks周期性地分配timestamp和生成watermark(可能依赖于元素或者纯粹基于处理时间)。
watermark产生的事件间隔(每n毫秒)是通过ExecutionConfig.setAutoWatermarkInterval(...)来定义的,每当分配器的getCurrentWatermark()方法呗调用时,如果返回的watermark是非空并且大于上一个watermark的话,一个新的watermark将会被发射。
Assigner with punctuated watermarks
间断式的生成watermark。和周期性水印不一样,这种方式不是固定时间的,而是可以根据需要对每条数据进行筛选和处理
对于乱序数据处理,flink提供3重保障
1、watermark: 可以设置小一点hold住大部分情况,提供近似正确的结果
2、.allowedLateness(Time.minutes(1)) //允许处理迟到数据1分钟
3、.sideOutputLateData(new OutputTag(String, Double, Long)) //侧输出流,先输出到一个旁路,打上标签,保证数据不会丢