线性判别分析基础
理论
我们回顾一下二元假设检验问题,它的目标是判断某一个observation x ∈ R d x \in \mathbb{R}^d x∈Rd到底属于总体 P 1 P_1 P1还是 P 2 P_2 P2,在统计理论中,Neyman-Pearson引理说明了似然比检验是最优检验,也就是基于 log P 2 ( x ) P 1 ( x ) \log \frac{P_2(x)}{P_1(x)} logP1(x)P2(x)导出的检验统计量与拒绝域是最优的。现在我们考虑线性判别分析的设定,假设两个总体分别是 N ( μ 1 , Σ ) , N ( μ 2 , Σ ) N(\mu_1,\Sigma),N(\mu_2,\Sigma) N(μ1,Σ),N(μ2,Σ),则给定某个observation x ∈ R d x \in \mathbb{R}^d x∈Rd,对数似然比为(多元正态分布的概率密度参考我之前这一篇)
log P 1 ( x ) P 2 ( x ) = log ( 2 π ) − d / 2 ∣ Σ ∣ − 1 / 2 exp ( − 1 2 ( x − μ 1 ) ′ Σ − 1 ( x − μ 1 ) ) ( 2 π ) − d / 2 ∣ Σ ∣ − 1 / 2 exp ( − 1 2 ( x − μ 2 ) ′ Σ − 1 ( x − μ 2 ) ) = 1 2 ( x − μ 2 ) ′ Σ − 1 ( x − μ 2 ) − 1 2 ( x − μ 1 ) ′ Σ − 1 ( x − μ 1 ) = 1 2 ( x − μ 1 + ( μ 1 − μ 2 ) ) ′ Σ − 1 ( x − μ 1 + μ 2 2 + μ 1 + μ 2 2 − μ 2 ) − 1 2 ( x − μ 1 ) ′ Σ − 1 ( x − μ 1 + μ 2 2 + μ 1 + μ 2 2 − μ 1 ) = 1 2 ( x − μ 1 ) ′ Σ − 1 ( x − μ 1 + μ 2 2 ) + 1 2 ( μ 1 − μ 2 ) ′ Σ − 1 ( x − μ 1 + μ 2 2 ) + 1 4 ( x − μ 1 ) ′ Σ − 1 ( μ 1 − μ 2 ) + 1 4 ( μ 1 − μ 2 ) ′ Σ − 1 ( μ 1 − μ 2 ) − 1 2 ( x − μ 1 ) ′ Σ − 1 ( x − μ 1 + μ 2 2 ) − 1 4 ( x − μ 1 ) ′ Σ − 1 ( μ 1 − μ 2 ) = 1 2 ( μ 1 − μ 2 ) ′ Σ − 1 ( x − μ 1 + μ 2 2 ) + 1 4 ( μ 1 − μ 2 ) ′ Σ − 1 ( μ 1 − μ 2 ) ∝ Ψ ( x ) = ( μ 1 − μ 2 ) ′ Σ − 1 ( x − μ 1 + μ 2 2 ) \log \frac{P_1(x)}{P_2(x)}=\log \frac{(2\pi)^{-d/2}|\Sigma|^{-1/2}\exp \left( -\frac{1}{2}(x-\mu_1)'\Sigma^{-1}(x-\mu_1) \right)}{(2\pi)^{-d/2}|\Sigma|^{-1/2}\exp \left( -\frac{1}{2}(x-\mu_2)'\Sigma^{-1}(x-\mu_2) \right)} \\ = \frac{1}{2}(x-\mu_2)'\Sigma^{-1}(x-\mu_2) -\frac{1}{2}(x-\mu_1)'\Sigma^{-1}(x-\mu_1) \\ = \frac{1}{2}(x-\mu_1+(\mu_1-\mu_2))'\Sigma^{-1}(x-\frac{\mu_1+\mu_2}{2}+\frac{\mu_1+\mu_2}{2}-\mu_2) \\-\frac{1}{2}(x-\mu_1)'\Sigma^{-1}(x-\frac{\mu_1+\mu_2}{2}+\frac{\mu_1+\mu_2}{2}-\mu_1) \\ = \frac{1}{2}(x-\mu_1)'\Sigma^{-1}(x-\frac{\mu_1+\mu_2}{2})+\frac{1}{2}(\mu_1-\mu_2)'\Sigma^{-1}(x-\frac{\mu_1+\mu_2}{2}) \\ +\frac{1}{4}(x-\mu_1)'\Sigma^{-1}(\mu_1-\mu_2)+\frac{1}{4}(\mu_1-\mu_2)'\Sigma^{-1}(\mu_1-\mu_2) \\ - \frac{1}{2}(x-\mu_1)'\Sigma^{-1}(x-\frac{\mu_1+\mu_2}{2})-\frac{1}{4}(x-\mu_1)'\Sigma^{-1}(\mu_1-\mu_2) \\ = \frac{1}{2}(\mu_1-\mu_2)'\Sigma^{-1}(x-\frac{\mu_1+\mu_2}{2})+\frac{1}{4}(\mu_1-\mu_2)'\Sigma^{-1}(\mu_1-\mu_2) \\ \propto \Psi(x)=(\mu_1-\mu_2)'\Sigma^{-1}(x-\frac{\mu_1+\mu_2}{2}) logP2(x)P1(x)=log(2π)−d/2∣Σ∣−1/2exp(−21(x−μ2)′Σ−1(x−μ2))(2π)−d/2∣Σ∣−1/2exp(−21(x−μ1)′Σ−1(x−μ1))=21(x−μ2)′Σ−1(x−μ2)−21(x−μ1)′Σ−1(x−μ1)=21(x−μ1+(μ1−μ2))′Σ−1(x−2μ1+μ2+2μ1+μ2−μ2)−21(x−μ1)′Σ−1(x−2μ1+μ2+2μ1+μ2−μ1)=21(x−μ1)′Σ−1(x−2μ1+μ2)+21(μ1−μ2)′Σ−1(x−2μ1+μ2)+41(x−μ1)′Σ−1(μ1−μ2)+41(μ1−μ2)′Σ−1(μ1−μ2)−21(x−μ1)′Σ−1(x−2μ1+μ2)−41(x−μ1)′Σ−1(μ1−μ2)=21(μ1−μ2)′Σ−1(x−2μ1+μ2)+41(μ1−μ2)′Σ−1(μ1−μ2)∝Ψ(x)=(μ1−μ2)′Σ−1(x−2μ1+μ2)
如果 Ψ ( x ) > 0 \Psi(x)>0 Ψ(x)>0,我们认为 x x x是来自 P 1 P_1 P1的样本;如果 Ψ ( x ) ≤ 0 \Psi(x) \le 0 Ψ(x)≤0,我们认为 x x x是来自 P 2 P_2 P2的样本;所以判别分析出错的概率是
E r r ( Ψ ) = 1 2 P 1 [ Ψ ( x ) ≤ 0 ] + 1 2 P 2 [ Ψ ( x ) > 0 ] Err(\Psi)=\frac{1}{2}P_1[\Psi(x)\le 0]+\frac{1}{2}P_2[\Psi(x)>0] Err(Ψ)=21P1[Ψ(x)≤0]+21P2[Ψ(x)>0]
定义
γ = ( μ 1 − μ 2 ) ′ Σ − 1 ( μ 1 − μ 2 ) \gamma = \sqrt{(\mu_1-\mu_2)'\Sigma^{-1}(\mu_1-\mu_2)} γ=(μ1−μ2)′Σ−1(μ1−μ2)
先计算第一个概率,如果 x ∼ N ( μ 1 , Σ ) x \sim N(\mu_1,\Sigma) x∼N(μ1,Σ),则
E Ψ ( x ) = ( μ 1 − μ 2 ) ′ Σ − 1 ( μ 1 − μ 1 + μ 2 2 ) = γ 2 2 V a r ( Ψ ( x ) ) = ( μ 1 − μ 2 ) ′ Σ − 1 Σ Σ − 1 ( μ 1 − μ 2 ) = γ 2 E\Psi(x)=(\mu_1-\mu_2)'\Sigma^{-1}(\mu_1-\frac{\mu_1+\mu_2}{2})=\frac{\gamma^2}{2} \\ Var(\Psi(x))=(\mu_1-\mu_2)'\Sigma^{-1} \Sigma \Sigma^{-1}(\mu_1-\mu_2)=\gamma^2 EΨ(x)=(μ1−μ2)′Σ−1(μ1−2μ1+μ2)=2γ2Var(Ψ(x))=(μ1−μ2)′Σ−1ΣΣ−1(μ1−μ2)=γ2
所以 Ψ ( x ) ∣ P 1 ∼ N ( γ / 2 , γ ) \Psi(x)|_{P_1} \sim N(\gamma/2,\gamma) Ψ(x)∣P1∼N(γ/2,γ),于是
P 1 [ Ψ ( x ) ≤ 0 ] = P 1 ( Ψ ( x ) − γ 2 2 γ ≤ − γ 2 ) = Φ ( − γ / 2 ) P_1[\Psi(x)\le 0]=P_1(\frac{\Psi(x)-\frac{\gamma^2}{2}}{\gamma} \le -\frac{\gamma}{2})=\Phi(-\gamma/2) P1[Ψ(x)≤0]=P1(γΨ(x)−2γ2≤−2γ)=Φ(−γ/2)
接下来计算第二个概率,如果 x ∼ N ( μ 2 , Σ ) x \sim N(\mu_2,\Sigma) x∼N(μ2,Σ),则
E Ψ ( x ) = ( μ 1 − μ 2 ) ′ Σ − 1 ( μ 2 − μ 1 + μ 2 2 ) = − γ 2 2 V a r ( Ψ ( x ) ) = ( μ 1 − μ 2 ) ′ Σ − 1 Σ Σ − 1 ( μ 1 − μ 2 ) = γ 2 E\Psi(x)=(\mu_1-\mu_2)'\Sigma^{-1}(\mu_2-\frac{\mu_1+\mu_2}{2})=-\frac{\gamma^2}{2} \\ Var(\Psi(x))=(\mu_1-\mu_2)'\Sigma^{-1} \Sigma \Sigma^{-1}(\mu_1-\mu_2)=\gamma^2 EΨ(x)=(μ1−μ2)′Σ−1(μ2−2μ1+μ2)=−2γ2Var(Ψ(x))=(μ1−μ2)′Σ−1ΣΣ−1(μ1−μ2)=γ2
所以 Ψ ( x ) ∣ P 2 ∼ N ( γ / 2 , γ ) \Psi(x)|_{P_2} \sim N(\gamma/2,\gamma) Ψ(x)∣P2∼N(γ/2,γ),于是
P 2 [ Ψ ( x ) ≤ 0 ] = P 2 ( Ψ ( x ) + γ 2 2 γ > γ 2 ) = Φ ( − γ / 2 ) P_2[\Psi(x)\le 0]=P_2(\frac{\Psi(x)+\frac{\gamma^2}{2}}{\gamma} > \frac{\gamma}{2})=\Phi(-\gamma/2) P2[Ψ(x)≤0]=P2(γΨ(x)+2γ2>2γ)=Φ(−γ/2)
综上,
E r r ( Ψ ) = Φ ( − γ / 2 ) Err(\Psi)=\Phi(-\gamma/2) Err(Ψ)=Φ(−γ/2)
算法
我们看一下理论部分的判别规则:如果 Ψ ( x ) > 0 \Psi(x)>0 Ψ(x)>0,我们认为 x x x是来自 P 1 P_1 P1的样本;如果 Ψ ( x ) ≤ 0 \Psi(x) \le 0 Ψ(x)≤0,我们认为 x x x是来自 P 2 P_2 P2的样本;要使用这个规则进行判别,我们需要计算出
Ψ ( x ) = ( μ 1 − μ 2 ) ′ Σ − 1 ( x − μ 1 + μ 2 2 ) \Psi(x)=(\mu_1-\mu_2)'\Sigma^{-1}(x-\frac{\mu_1+\mu_2}{2}) Ψ(x)=(μ1−μ2)′Σ−1(x−2μ1+μ2)
为此,我们需要样本均值与协方差矩阵的估计。假设我们有 n 1 + n 2 n_1+n_2 n1+n2个样本,前 n 1 n_1 n1个来自总体 P 1 P_1 P1,后 n 2 n_2 n2个来自总体 P 2 P_2 P2,引入样本均值
μ ^ 1 = 1 n 1 ∑ i = 1 n 1 x i , μ ^ 2 = 1 n 2 ∑ i = n 1 + 1 n 1 + n 2 x i \hat \mu_1 = \frac{1}{n_1}\sum_{i=1}^{n_1} x_i,\hat \mu_2 = \frac{1}{n_2} \sum_{i=n_1+1}^{n_1+n_2} x_i μ^1=n11i=1∑n1xi,μ^2=n21i=n1+1∑n1+n2xi
Pooled sample covariance matrix,
Σ ^ = ∑ i = 1 n 1 ( x i − μ ^ 1 ) ( x i − μ ^ 1 ) T + ∑ i = 1 n 2 ( x i − μ ^ 2 ) ( x i − μ ^ 2 ) T n 1 + n 2 − 2 \hat \Sigma =\frac{\sum_{i=1}^{n_1}(x_i-\hat \mu_1)(x_i - \hat \mu_1)^T+\sum_{i=1}^{n_2}(x_i-\hat \mu_2)(x_i - \hat \mu_2)^T}{n_1+n_2-2} Σ^=n1+n2−2∑i=1n1(xi−μ^1)(xi−μ^1)T+∑i=1n2(xi−μ^2)(xi−μ^2)T
把这三个估计量代入 Ψ ( x ) \Psi(x) Ψ(x),我们就可以得到Fisher线性判别函数(Fisher linear determinant function):
Ψ ^ ( x ) = ( μ ^ 1 − μ ^ 2 ) ′ Σ ^ − 1 ( x − μ ^ 1 + μ ^ 2 2 ) \hat{\Psi}(x)=(\hat \mu_1- \hat \mu_2)' \hat \Sigma^{-1}(x-\frac{\hat \mu_1+ \hat \mu_2}{2}) Ψ^(x)=(μ^1−μ^2)′Σ^−1(x−2μ^1+μ^2)
基于Fisher线性判别函数的判别错误概率为
E r r ( Ψ ^ ) = 1 2 P 1 [ Ψ ^ ( x ) ≤ 0 ] + 1 2 P 2 [ Ψ ^ ( x ) > 0 ] Err(\hat \Psi)=\frac{1}{2}P_1[\hat \Psi(x)\le 0]+\frac{1}{2}P_2[\hat \Psi(x)>0] Err(Ψ^)=21P1[Ψ^(x)≤0]+21P2[Ψ^(x)>0]
一个重要的问题是,基于Fisher线性判别函数的判别错误概率能不能等于判别分析出错的理论概率,或者说只比判别分析出错的理论概率大一点点?概统祖师爷Kolmogorov分析过这个问题,如果 d / n i → α , ∀ i = 1 , 2 d/n_i \to \alpha,\forall i=1,2 d/ni→α,∀i=1,2, ∥ μ ^ 1 − μ ^ 2 ∥ 2 → p γ \left\| \hat \mu_1- \hat \mu_2 \right\|_2\to_p \gamma ∥μ^1−μ^2∥2→pγ,协方差矩阵为单位阵,则
E r r ( Ψ ^ ) → p Φ ( − γ 2 2 γ 2 + α 2 ) Err(\hat \Psi) \to_p \Phi(-\frac{\gamma^2}{2\sqrt{\gamma^2+\alpha^2}}) Err(Ψ^)→pΦ(−2γ2+α2γ2)
我们来简单看一下下面的实证结果:
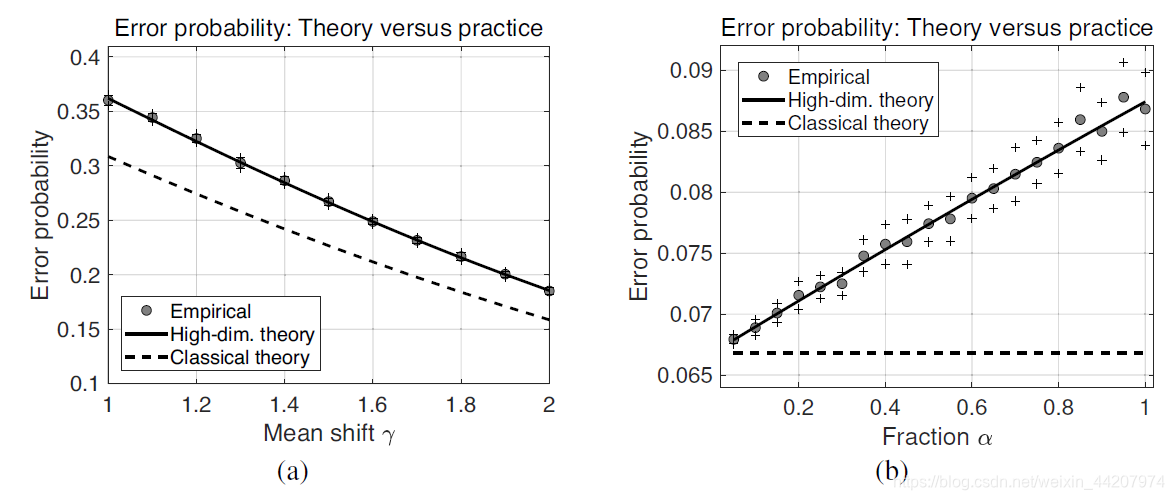
左图:Mean shrift越大,说明这两个总体分得越开,越不容易判别出错;实验结果略大于理论结果,所以还是比较可信的;
右图: α \alpha α越大说明 d / n i d/n_i d/ni越大,也就是这个问题的维度越高,这时实验的结果就会越差,但经典理论的结果是不变,因此我们需要建立新的理论来解释高维统计问题。