1. RL分类
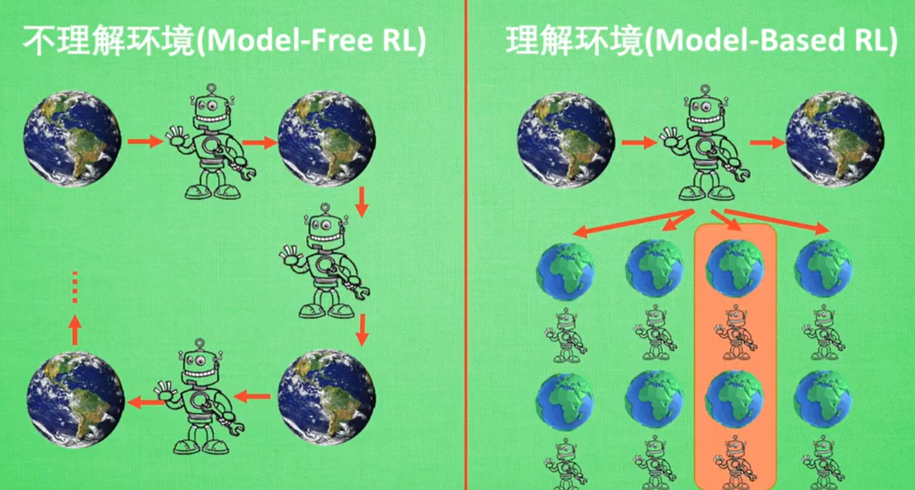
- model-free方法:对环境不了解,每次行动只能等环境的反馈才可以进行下一步
- model-based方法:由于已经对环境有一定的了解,所以每次在执行行动的时候可以预先想象到之后环境的反馈,来更好指导自己的决策。
- 对环境的了解主要体现在:环境的奖励、环境的一些状态转移概率,这些内容是否已知
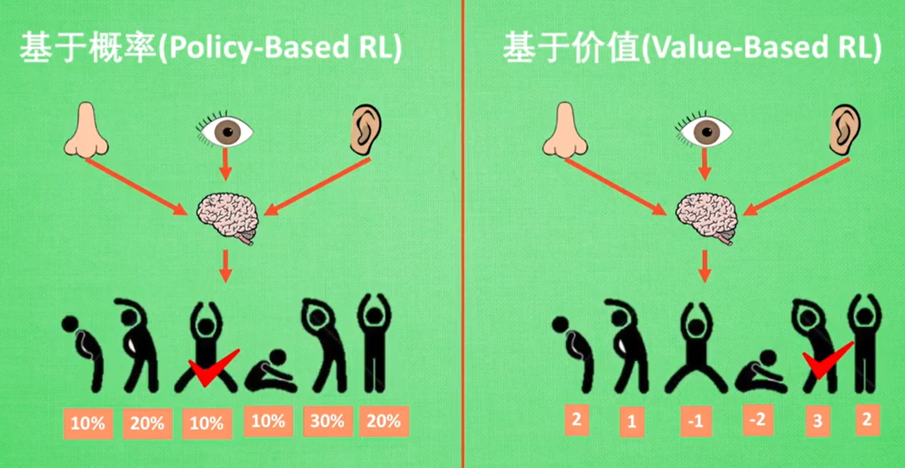
- 基于概率的方法输出的是每个动作的概率,这时每个动作都有可能被选到
- 基于价值的方法输出的每个动作的价值,这时只会选到价值最大的动作
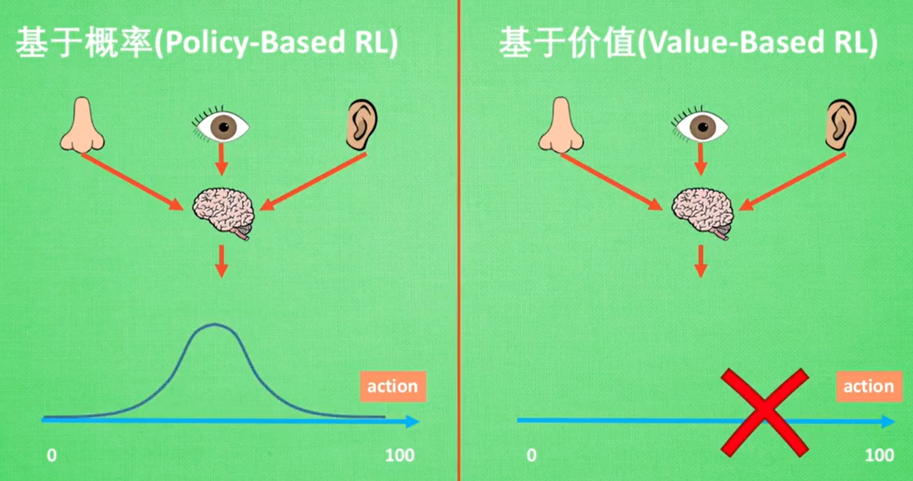
- 对于动作空间是连续值的场景来说,基于价值的方法是无能为力的,但是基于概率的方式却可以使用一个概率分布区进行描述,来选择一个动作

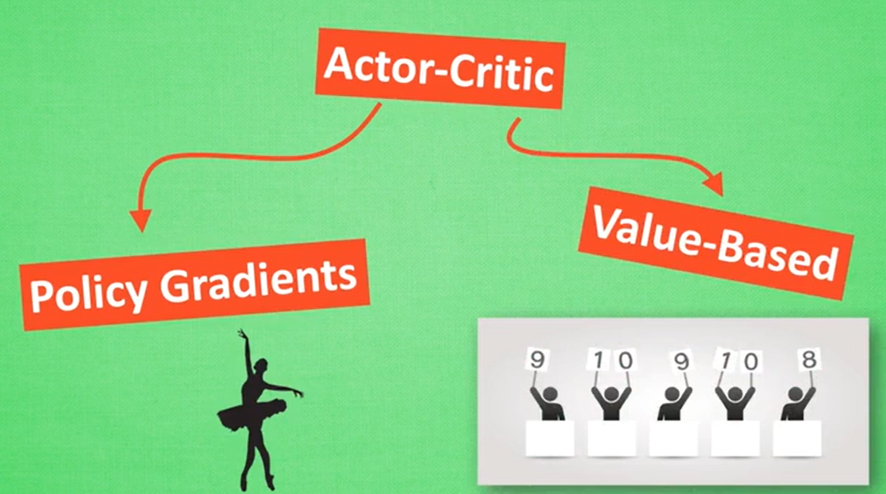
- 结合基于概率的方法和基于值的方法,可以得到一种更强大的方法:Actor-Critic
- Actor使用概率来选择动作
- Critic对actor做出的动作给出价值
- 这样就在原有的Policy Gradients基础上加入了学习过程
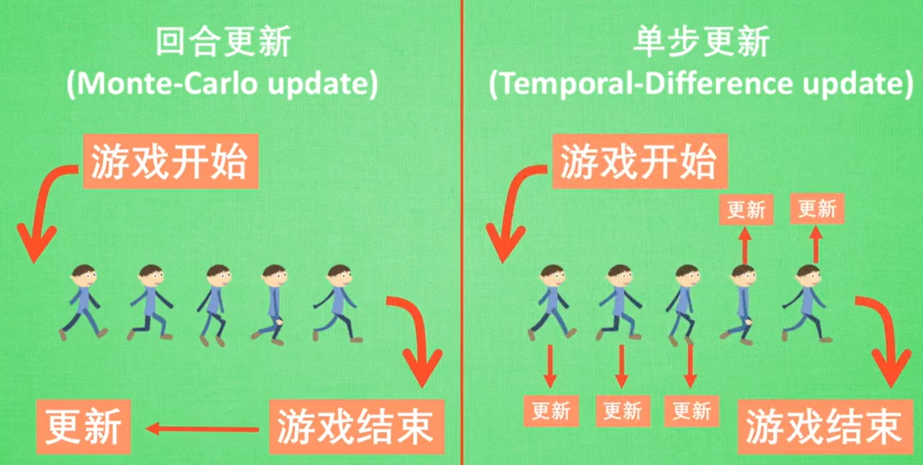

- 因为单步更新效率高,所以现在大多数方式都采用单步更新
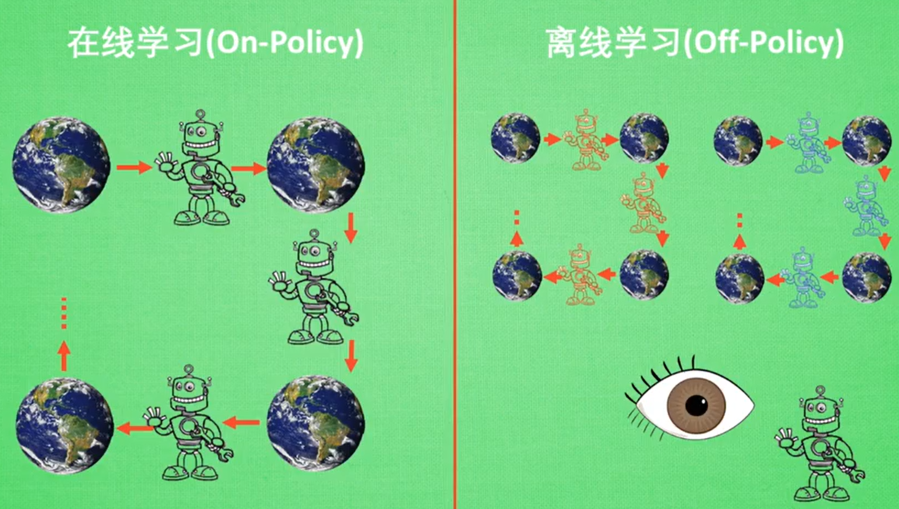
- 在线学习就是要自己一边学习一边和环境交互
- 离线学习就是可以让别人学,然后自己可以找别的时间看着它学,不用一直自己边学边和环境交互。
决策过程和学习优化决策的过程是分开的


- 假设Q-learning的机器人天生是机器人,
- γ = 1 \gamma=1 γ=1的时候,就是给了它一副贼好的眼睛,所以它可以非常清晰看到所有未来步骤的奖赏
- γ = 0 \gamma=0 γ=0的时候,就是眼睛度数不合适,所以看不见未来,只能看到刚刚走的那步的奖励
- γ = [ 0 ∼ 1 ] \gamma=[0\sim1] γ=[0∼1]时,就是上面的公式,越远的未来看的越不清楚,也就是未来的奖励衰减越来越大。
2. Q-learning

有一个实际值,有一个估计值(这点有点像监督学习),然后让估计/预测值不断靠近实际值,就可以得到一个很好的Q表。
然后再结合 ϵ \epsilon ϵ greed策略去选择动作(策略是指导选取动作的)
3. Sarsa

Q_learning和Sarsa都是model_free的方法
4. Sara-lambda
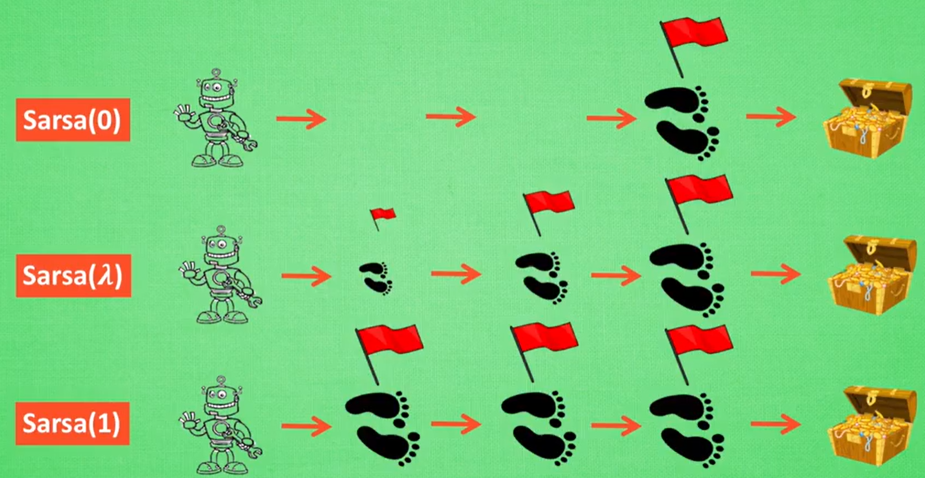
- Sarsa就是Sarsa(0),是一种单步更新的方式,
- Sarsa(1)属于回合更新,一次episode结束后,所有步都同等程度更新
- Sarsa( λ \lambda λ)中的这个 λ \lambda λ参数和之前的 γ \gamma γ有点像
- λ \lambda λ参数是更新程度的描述,越靠近终点(或者说要靠近奖励越大的地方),更新的幅度越大
- γ \gamma γ则是当前动作的价值的衰减因子,越远则价值越小。
5. DQN
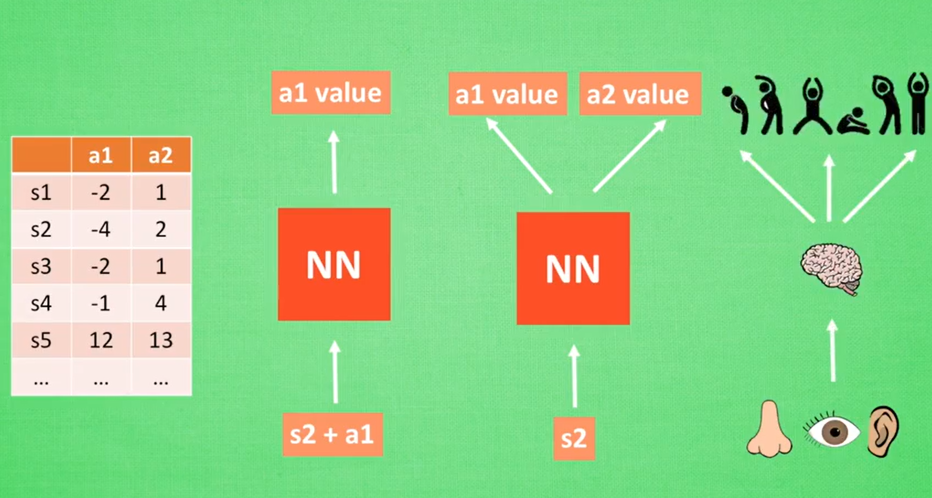
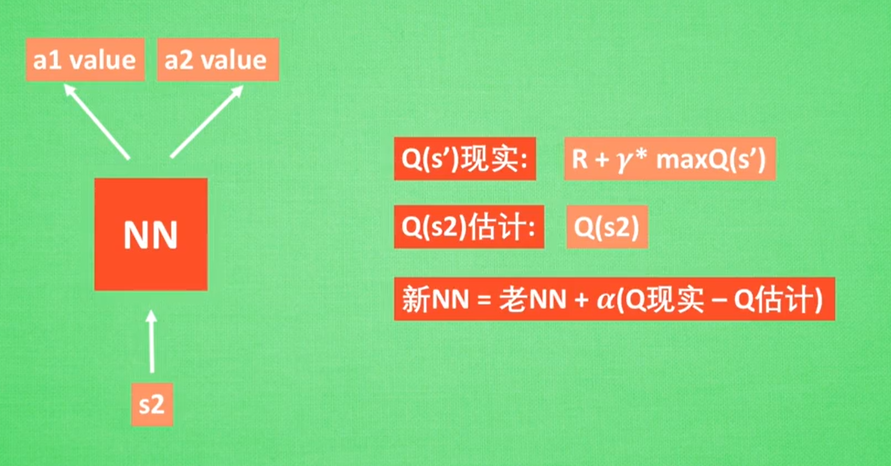
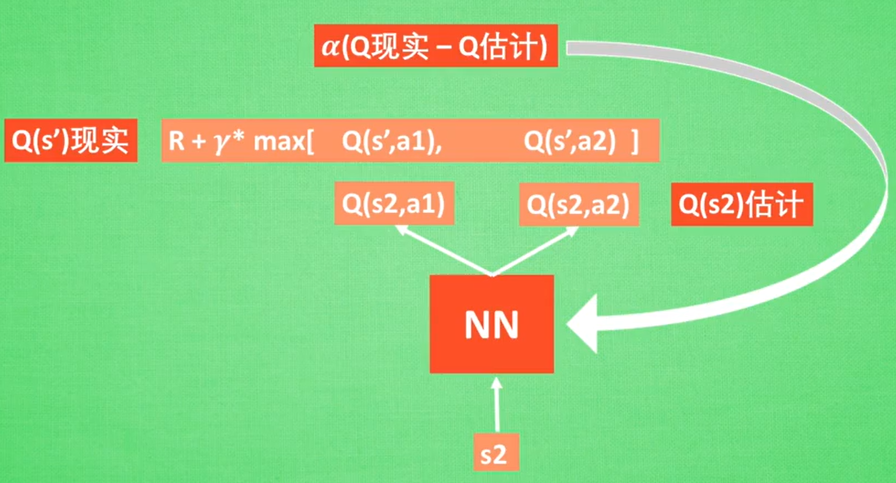

6.Actor-Critic