感知器结构
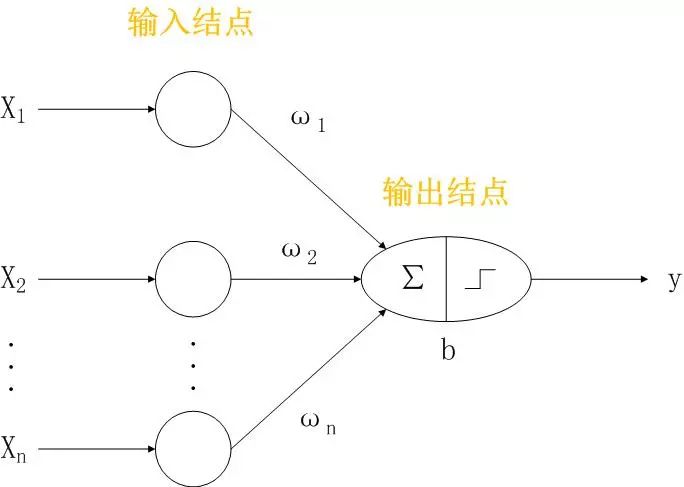
输入结点。表示输入属性。输入信号X是一个n维向量,n表示记录的特征数量,向量X各个维度上的分量即对应特征的值。
输出结点。是一个数学装置,提供模型输出。包括加权求和和激活函数两部分。
权重W={ω1, ω2, … , ωn}。每个输入结点通过一个加权的链连接到输出结点。权重用来模拟神经元间神经键的链接强度。
输出信号y。输出结点通过计算输入的加权和,加上偏置项b,根据激活函数产生输出。
感知器数学表达式
其中,为激活函数,常用的激活函数有:ReLU,tanh,sigmoid,sign等。训练一个感知器模型,相当于根据数据不断调整权重和偏置,使得总误差尽量小。
为了使公式表达更加简洁,b可以写成权重与x分量相乘的形式,即b=x0*ω0,其中ω0=b,x0=1。因此,感知器模型可以更简洁的表达为:
感知器模拟布尔函数
布尔函数指输入与输出的取值范围都在{0,1}内的函数。现有如下数据集,包含三个布尔输入变量和一个输出变量,当三个输入变量中至少有两个为0时,y取-1,当输入变量至少有两个大于0时,y取1。
X1 |
X2 |
X3 |
y |
1 |
0 |
0 |
-1 |
1 |
0 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
1 |
-1 |
0 |
1 |
0 |
-1 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
-1 |
当各输入结点到输出结点的权重全部取0.3,偏置取-0.4时,使用符号函数sign()作为激活函数,则可用如下感知器公式来模拟此布尔函数:
将数据集中每条样本带入上述公式,可以发现,均可满足相应结果。
训练感知器模型
训练阶段,就是调整参数使得输出和样例的实际输出一致。最重要的部分就是根据旧权重和每次计算的误差,调整得出新权重。
算法流程
step1
D={(xi,yi)|i=1,2,…,n}为原始数据集
ω(0)={随机初始化权重向量};
step2
repeat
for 对于每个样例(xi,yi) {
计算预测输出y*
for 每个权值ωj {
ωj(k+1) =ωj(k) +λ(yi-y*(k))xij (1)
}
}
满足终止条件结束repeat
λ为学习率,ω(k)是第k次循环后第i个输入的权值向量,xij是xi第j个属性值。从权值更新公式(1)中可以看出,新权值等于旧权值加上一个正比于误差的值,如果预测正确,权值不变;如果(y-y*)>0,则要提高正输入的权值,并降低负输入的权值来提高预测输出值;如果(y-y*)<0,则要降低正输入的权值,并提高负输入的权值来降低预测输出值。
为了控制权值每次的改变量,以免使得前面的调整失效,λ控制在0-1之间,越接近0新权重受旧权重影响越大,越接近1新权重受误差影响越大。在一些情况下可以使用自适应的λ,即前几次循环时λ相对较大,后面循环中λ逐渐减小。
使用限制
感知器的决策边界是一个超平面,对于线性可分问题,可以收敛到一个最优解,如果问题不是线性可分的,那么感知器算法不收敛。