提到人工智能(Artificial Intelligence,AI),大家都不会陌生,在现今行业领起风潮,各行各业无不趋之若鹜,作为技术使用者,到底什么是AI,我们要有自己的理解.
目前,在人工智能中,无可争议的是深度学习占据了统治地位,,其在图像识别,语音识别,自然语言处理,无人驾驶领域应用广泛.
如此,我们要如何使用这门技术呢?下面我们来一起了解"多层感知器",即MLP算法,泛称为神经网络.
神经网络顾名思义,就像我们人脑中的神经元一样,为了让机器来模拟人脑,我们在算法中设置一个个节点,在训练模型时,输入的特征与预测的结果用节点来表示,系数w(又称为"权重")用来连接节点,神经网络模型的学习就是一个调整权重的过程,训练模型一步步达到我们想要的效果.
理解了原理,下面来上代码直观看一下:
1.神经网络中的非线性矫正
每个输入数据与输出数据之间都有一个或多个隐藏层,每个隐藏层包含多个隐藏单元.
在输入数据和隐藏单元之间或隐藏单元和输出数据之间都有一个系数(权重).
计算一系列的加权求和和计算单一的加权求和和普通的线性模型差不多.
线性模型的一般公式:
y = w[0]▪x[0]+w[1]▪x[1] + ▪▪▪ + w[p]▪x[p] + b
为了使得模型比普通线性模型更强大,所以我们要进行一些处理,即非线性矫正(rectifying nonlinearity),简称为(rectified linear unit,relu).或是进行双曲正切处理(tangens hyperbolicus,tanh)
############################# 神经网络中的非线性矫正 #######################################
#导入numpy
import numpy as np
#导入画图工具
import matplotlib.pyplot as plt
#导入numpy
import numpy as py
#导入画图工具
import matplotlib.pyplot as plt
#生成一个等差数列
line = np.linspace(-5,5,200)
#画出非线性矫正的图形表示
plt.plot(line,np.tanh(line),label='tanh')
plt.plot(line,np.maximum(line,0),label='relu')
#设置图注位置
plt.legend(loc='best')
#设置横纵轴标题
plt.xlabel('x')
plt.ylabel('relu(x) and tanh(x)')
#显示图形
plt.show()
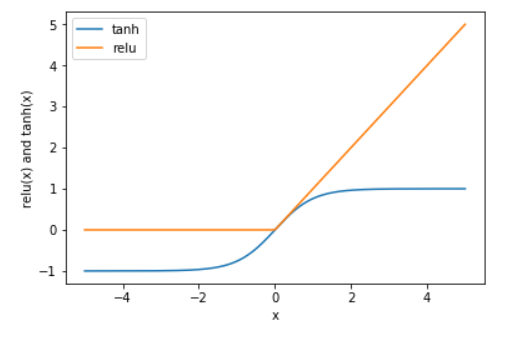
- tanh函数吧特征X的值压缩进-1到1的区间内,-1代表的是X中较小的数值,而1代表X中较大的数值.
- relu函数把小于0的X值全部去掉,用0来代替
2.神经网络的参数设置
#导入MLP神经网络 from sklearn.neural_network import MLPClassifier #导入红酒数据集 from sklearn.datasets import load_wine #导入数据集拆分工具 from sklearn.model_selection import train_test_split wine = load_wine() X = wine.data[:,:2] y = wine.target #下面我们拆分数据集 X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=0) #接下来定义分类器 mlp = MLPClassifier(solver='lbfgs') mlp.fit(X_train,y_train)
MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(100,), learning_rate='constant',
learning_rate_init=0.001, max_iter=200, momentum=0.9,
n_iter_no_change=10, nesterovs_momentum=True, power_t=0.5,
random_state=None, shuffle=True, solver='lbfgs', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False)
- identity对样本特征不做处理,返回值是f(x) = x
- logistic返回的结果会是f(x)=1/[1 + exp(-x)],其和tanh类似,但是经过处理后的特征值会在0和1之间
#导入画图工具
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
#定义图像中分区的颜色和散点的颜色
cmap_light = ListedColormap(['#FFAAAA','#AAFFAA','#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000','#00FF00','#0000FF'])
#分别用样本的两个特征值创建图像和横轴和纵轴
x_min,x_max = X_train[:, 0].min() - 1,X_train[:, 0].max() + 1
y_min,y_max = X_train[:, 1].min() - 1,X_train[:, 1].max() + 1
xx,yy = np.meshgrid(np.arange(x_min,x_max, .02),np.arange(y_min,y_max, .02))
Z = mlp.predict(np.c_[xx.ravel(),yy.ravel()])
#给每个分类中的样本分配不同的颜色
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
#用散点图把样本表示出来
plt.scatter(X[:, 0],X[:, 1],c=y,edgecolor='k',s=60)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("MLPClassifier:solver=lbfgs")
plt.show()

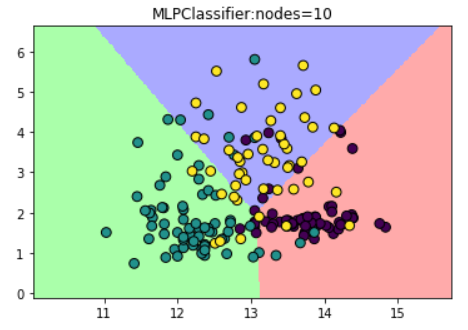
(1)设置隐藏层中节点数为10
#设置隐藏层中节点数为10
mlp_20 = MLPClassifier(solver='lbfgs',hidden_layer_sizes=[10])
mlp_20.fit(X_train,y_train)
Z1 = mlp_20.predict(np.c_[xx.ravel(),yy.ravel()])
#给每个分类中的样本分配不同的颜色
Z1 = Z1.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z1, cmap=cmap_light)
#用散点图把样本表示出来
plt.scatter(X[:, 0],X[:, 1],c=y,edgecolor='k',s=60)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("MLPClassifier:nodes=10")
plt.show()
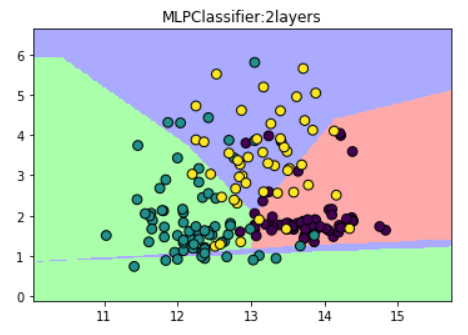
(2)设置神经网络有两个节点数为10的隐藏层
#设置神经网络2个节点数为10的隐藏层
mlp_2L = MLPClassifier(solver='lbfgs',hidden_layer_sizes=[10,10])
mlp_2L.fit(X_train,y_train)
ZL = mlp_2L.predict(np.c_[xx.ravel(),yy.ravel()])
#给每个分类中的样本分配不同的颜色
ZL = ZL.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, ZL, cmap=cmap_light)
#用散点图把样本表示出来
plt.scatter(X[:, 0],X[:, 1],c=y,edgecolor='k',s=60)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("MLPClassifier:2layers")
plt.show()
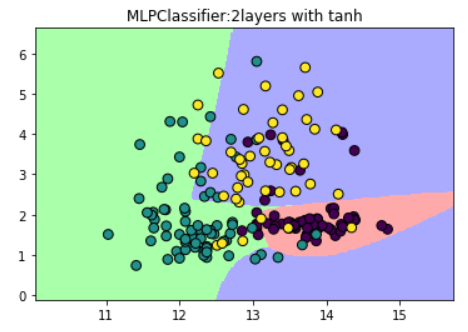
(3)设置激活函数为tanh
#设置激活函数为tanh
mlp_tanh = MLPClassifier(solver='lbfgs',hidden_layer_sizes=[10,10],activation='tanh')
mlp_tanh.fit(X_train,y_train)
Z2 = mlp_tanh.predict(np.c_[xx.ravel(),yy.ravel()])
#给每个分类中的样本分配不同的颜色
Z2 = Z2.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z2, cmap=cmap_light)
#用散点图把样本表示出来
plt.scatter(X[:, 0],X[:, 1],c=y,edgecolor='k',s=60)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("MLPClassifier:2layers with tanh")
plt.show()
(4)修改模型的alpha参数
#修改模型的alpha参数
mlp_alpha = MLPClassifier(solver='lbfgs',hidden_layer_sizes=[10,10],activation='tanh',alpha=1)
mlp_alpha.fit(X_train,y_train)
Z3 = mlp_alpha.predict(np.c_[xx.ravel(),yy.ravel()])
#给每个分类中的样本分配不同的颜色
Z3 = Z3.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z3, cmap=cmap_light)
#用散点图把样本表示出来
plt.scatter(X[:, 0],X[:, 1],c=y,edgecolor='k',s=60)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("MLPClassifier:alpha=1")
plt.show()
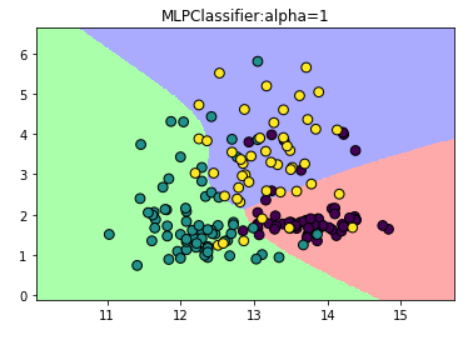
总结:
如此,我们有4种方法可以调节模型的复杂程度:
第一种,调整神经网络每一个隐藏层上的节点数
第二种,调节神经网络隐藏层的层数
第三种,调节activation的方式
第四种,通过调整alpha值来改变模型正则化的过程
对于特征类型比较单一的数据集来说,神经网络的表现还是不错的,但是如果数据集中的特征类型差异比较大的话,随机森林或梯度上升随机决策树等基于决策树的算法的表现会更好一点.
神经网络模型中的参数调节至关重要,尤其是隐藏层的数量和隐藏层中的节点数.
这里给出一个参考原则:神经网络中的隐藏层的节点数约等于训练数据集的特征数量,但一般不超过500.
如果想对庞大复杂高维的数据集做处理与分析,建议往深度学习发展,这里介绍两个流行的python深度学习库:keras,tensor-flow
文章引自 : 《深入浅出python机器学习》