一、概述
AlexNet是由2012年ImageNet竞赛参赛者Hinton和他的学生Alex Krizhevsky设计的。AlexNet在当年赢得了ImageNet图像分类竞赛的冠军,使得CNN成为图像分类问题的核心算法模型,同时引发了神经网络的应用热潮。 1. AlexNet的创新 作为具有历史意义的网络结构,AlexNet包含以下方面的创新。 (1)非线性激活函数 ReLU 在AlexNet出现之前,sigmoid是最为常用的非线性激活函数。sigmoid函数能够把输入的连续实值压缩到0和1之间。但是,它的缺点也非常明显:当输入值非常大或者非常小的时候会出现饱和现象,即这些神经元的梯度接近0,因此存在梯度消失问题。为了解决这个问题,AlexNet使用ReLU作为激活函数。 ReLU函数的表达式为F(x)=max(0,z)。若输入小于0,那么输出为0;若输入大于0,那么输出等于输入。由于导数始终是1,会使得计算量有所减少,且AlexNet的作者在实验中证明了,ReLU 函数的收敛速度要比sigmoid 函数和 tanh函数快。 (2)局部响应归一化 局部响应归一化(local response normalization,LRN)的思想来源于生物学中的“侧抑制”,是指被激活的神经元抑制相邻的神经元。采用LRN的目的是,将数据分布调整到合理的范围内,便于计算处理,从而提高泛化能力。虽然ReLu函数对较大的值也有很好的处理效果,但AlexNet的作者仍然采用了LRN的方式。式3.7是Hinton在有关AlexNet的论文中给出的局部响应归一化公式。
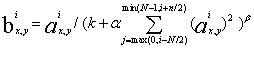
a表示第i个卷积核在(x,y)处经卷积、池化、ReLU函数计算后的输出,相当于该卷积核提取的局部特征。N表示这一层的卷积核总数;n表示在同一位置的临近卷积核的个数,是预先设定的;k、alpha、beta均为超参数。假设N=20,超参数和n按照论文中的设定,分别为k=2、alpha=10-4、beta=0.75、n=5。第5个卷积核在(x,y)处提取了特征,的作用就是以第5个卷积核为中心,选取前后各5/2=2个(取整,因此n所指个数包含中心卷积核)卷积核,因此有max=3和min=7,卷积核个数就是3、4、5、6、7。 通过分析公式,我们对局部响应归一化的理解会进一步加深。式3.7的存在,使得每个局部特征最后都会被缩小(只是缩小的比例不同),相当于进行了范围控制。一旦在某个卷积核周围提取的特征比它自己提取的特征的值大,那么该卷积核提取的特征就会被缩小。相反,如果在该卷积核周围提取的特征比它自己提取的特征的值小,那么该卷积核提取的特征被缩小的比例就会变小,最终的值与周围的卷积核提取的特征值相比就显得比较大了。 (3) dropout dropout通过设置好的概率随机将某个隐藏层神经元的输出设置为0,因此这个神经元将不参与前向传播和反向传播,在下一次迭代中会根据概率重新将某个神经元的输出置0。这样一来,在每次迭代中都能够尝试不同的网络结构,通过组合多个模型的方式有效地减少过拟合。 (4)多GPU训练 单个GPU的内存限制了网络的训练规模。采用多GPU协同训练,可以大大提高AlexNet的训练速度。
二、AlexNet的结构
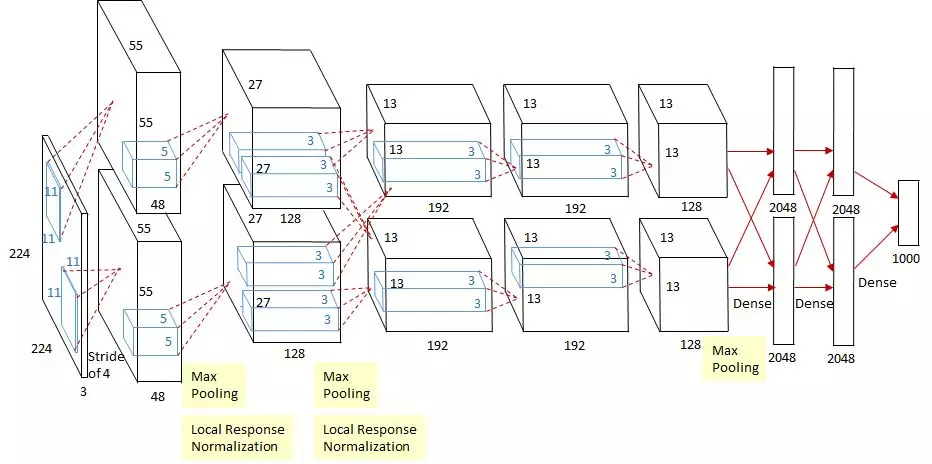
下面介绍AlexNet的结构。如图所示,由于采用双GPU协同训练,该网络结构图分为上下两部分,且两个GPU只在特定的层内通信。该模型一共分为8层,包括5个卷积层和3个全连接层,每个卷积层都包含激活函数ReLU、池化和LRN处理。
| 层 | 类型 | 特征图 | 大小 | 内核 | 步幅 | 填充 | 激活 |
|---|---|---|---|---|---|---|---|
| OUT | 全连接 | - | 1000 | - | - | - | ReLU |
| F10 | 全连接 | - | 4096 | - | - | - | ReLU |
| F9 | 全连接 | - | 4096 | - | - | - | ReLU |
| s8 | 最大池化 | 256 | 6*6 | 3*3 | 2 | valid | - |
| C7 | 卷积 | 256 | 13*13 | 5*5 | 1 | same | ReLU |
| C6 | 卷积 | 384 | 13*13 | 5*5 | 1 | same | ReLU |
| C5 | 卷积 | 384 | 13*13 | 5*5 | 1 | same | ReLU |
| S4 | 最大池化 | 256 | 13*13 | 3*3 | 2 | valid | - |
| C3 | 卷积 | 256 | 27*27 | 5*5 | 1 | same | ReLU |
| S2 | 最大池化 | 96 | 27*27 | 3*3 | 2 | valid | - |
| C1 | 卷积 | 96 | 55*55 | 11*11 | 4 | valid | ReLU |
| In | 输入 | 3(RGB) | 227*227 | - | - | - | - |
(1)Layer1卷积层
该层接收227×227×3(R、G、B三个通道)的输入图像,使用96个大小为11×11×3的卷积核进行特征提取,步长为1,扩充值为0,通过式3.1可以得到输出特征图的尺寸。由于使用了双GPU,图3.13中的每个GPU处理的卷积核的数量均为48个。卷积后,得到大小为55×55×96的特征图。
对得到的特征图,使用ReLU函数将它的值限定在合适的范围内,然后使用3×3的滤波器进行步长为2的池化操作,得到27×27×96的特征图。最后,进行归一化处理,规模不变。
(2)Layer 2卷积层
Layer 2与Layer 1相似,它接收Layer 1输出的27×27×96的特征图,采用256个5×5×96的卷积核,步长为1,扩充值为2,边缘用0填充,生成27×27×256的特征图。紧随其后的是与Layer 1相同的ReLU函数和池化操作,最后进行归一化处理。
(3) Layer3卷积层与Layer 4卷积层
Layer3和Layer4也采用了卷积层,但只进行卷积和ReLU。不进行池化和归一化操作。Layer3的每个GPU都有192个卷积核,每个卷积核的尺寸是3×3×256.步长为1,扩充值为1,边缘用0填充。最终,每个GPU都生成的个13×13的特征图。
Layer 4与Layer3的区别在于卷积核的尺寸。Layer4不像Layer3那样接收的一层所有GPU的输入,而只接收所在GPU的输出。因此,Layer 4的卷积核的尺寸为3×3×192,每个GPU都有192个卷积核。
与Layer 3相同的是,Layer 4仍然进行扩充值为1的0填充,且步长为1。最终,Layer 4的每个GPU都生成192个13×13的特征图。卷积后,这两个层都会由ReLU函数进行处理。
(4)Layer 5卷积层
Layer 5会依次进行卷积、ReLU和池化操作,但不进行归一化操作。该层中的每个GPU都接收本GPU中 Layer 4的输出,每个GPU使用128个3×3×192的卷积核,步长为1,使用扩充值为1的0填充,各自生成128个13×13的特征图后进行池化操作。池化尺寸为3×3,步长为2,最终生成6×6×128的特征图(两个GPU,共256个)。
(5)Layer 6全连接层
从该层开始,后面的网络层均为全连接层。Layer 6仍然按GPU进行卷积,每个GPU使用2048个6×6×256的卷积核,这意味着该层中的每个GPU都会接收前一层中两个GPU 的输出。卷积后,每个GPU都会生成2048个1×1的特征图。最后,进行ReLU和dropout操作,两个GPU共输出4096个值。
(6)Layer 7全连接层
Layer7与Layer6相似,与Layer6进行全连接,在进行ReLU和dropout操作后,共输出4096个值。
(7)Layer 8全连接层
Layer 8只进行全连接操作,且该层拥有1000个神经元,最终输出1000个float型的值(该值即为预测结果)。
三、构建AlexNet
构建LRN层
LRN层通常用lambda层进行包装,参数一般设置如下:
model.add(keras.layers.lambdas(lambda x: tf.nn.lrn(x, depth_radius=2, alpha=0.00002, beta=0.75, bias=1)))也可以用自定义层实现:
class LRN(keras.layers.Layer):
def __init__(self, depth_radius=2, bias=1, alpha=0.00002, beta=0.75, **kwargs):
super().__init__(**kwargs)
self.depth_radius = depth_radius
self.bias = bias
self.alpha = alpha
self.beta = beta
def call(self, input):
return tf.nn.lrn(input, self.depth_radius, self.bias, self.alpha, self.beta)
def get_config(self):
base_config = super().get_config()
return {**base_config, 'depth_radius': self.depth_radius,
'bias': self.bias, 'alpha': self.alpha, 'beta': self.beta}
构建模型:
model = keras.Sequential()
# 第一层
model.add(keras.layers.Conv2D(filters=96, kernel_size=(11,11), strides=(4,4), input_shape=(227,227,3), padding="VALID", activation="relu"))
model.add(LRN())
model.add(keras.layers.MaxPooling2D(pool_size=(3,3), strides=(2,2), padding="same"))
# 第二层
model.add(keras.layers.Conv2D(filters=256, kernel_size=(5,5), strides=(1,1), padding="SAME", activation="relu"))
model.add(LRN())
model.add(keras.layers.MaxPooling2D(pool_size=(3,3), strides=(2,2), padding="same"))
# 第三层
model.add(keras.layers.Conv2D(filters=384, kernel_size=(5,5), strides=(1,1), padding="SAME", activation="relu"))
# 第四层
model.add(keras.layers.Conv2D(filters=384, kernel_size=(5,5), strides=(1,1), padding="SAME", activation="relu"))
# 第五层
model.add(keras.layers.Conv2D(filters=256, kernel_size=(5,5), strides=(1,1), padding="SAME", activation="relu"))
model.add(keras.layers.MaxPooling2D(pool_size=(3,3), strides=(2,2), padding="same"))
# 第六层
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(4096, activation="relu"))
model.add(keras.layers.Dropout(0.5))
# 第七层
model.add(keras.layers.Dense(4096, activation="relu"))
model.add(keras.layers.Dropout(0.5))
# 第八层
model.add(keras.layers.Dense(10, activation="softmax"))注:LRN层也可用BatchNormalization替代,性能也还OK