如今,在各种期刊顶会都能看到平面抓取检测的论文,他们声称能应对多物体堆叠场景,然而实际效果都不尽人意,我认为主要原因有如下几点:
- 缺乏多物体堆叠场景的抓取数据集。现在最常用的Cornell Grasp Dataset, Jacquard数据集都是单目标场景。(像Dex-Net数据集和Google机器人工厂这种东西普通研究者就只能看着了)
- 现在的研究者过于强调端到端检测。
- 没有一个合适的抓取表示法。
如何利用少量数据集学习一个端到端网络或者整个方法中的一个子网络,实现堆叠场景中的平面抓取检测亟待解决。这里所说的堆叠场景是下左图,而不是大多数论文所说的右图:


简单说一下Dex-Net系列算法。Dex-Net共包括1.0--4.0四个版本,1.0为传统的解析法。2.0基于深度学习对平行板抓取配置进行质量评估,3.0针对吸盘进行设计,4.0结合了2.0和3.0两个算法。
算法输入为深度图,输出为平面抓取表示,即坐标点和抓取角,然后张开平行板抓取器至最大并垂直抓取。
算法主要包括两部分:采样抓取候选,抓取质量评估。
- 采样抓取候选:从给定深度图中采样很多个候选的抓取配置——采用cross entropy method
- 抓取质量评估:评估上一步每个抓取配置的质量[0,1],然后输出质量最高的抓取配置作为Grasp candidates,如下图。
- 其中,第一步采用的传统方法,第二步采用的深度学习,为了训练这个网络,作者生成了一个包含670万个样本的数据集。为了完成两个阶段的衔接,神经网络的输入也不能是传统的深度图,而是经过精心设计裁剪后的深度图。整个算法最妙的地方在于突破了传统的抓取思路:端到端地抓取检测,直接预测最优的抓取配置。

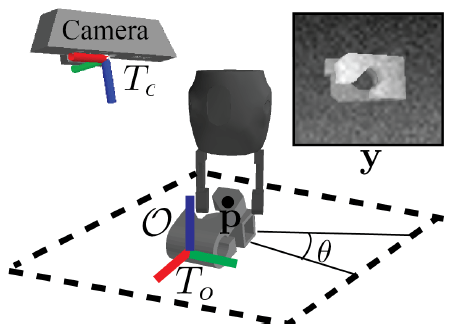
Dex-Net2.0采用的抓取表示为(x,y,theta),其中(x,y)为抓取点在深度图中的坐标,theta为抓取方向,在抓取时,抓取手张到最大然后垂直抓取,如下图:
抓取质量评估
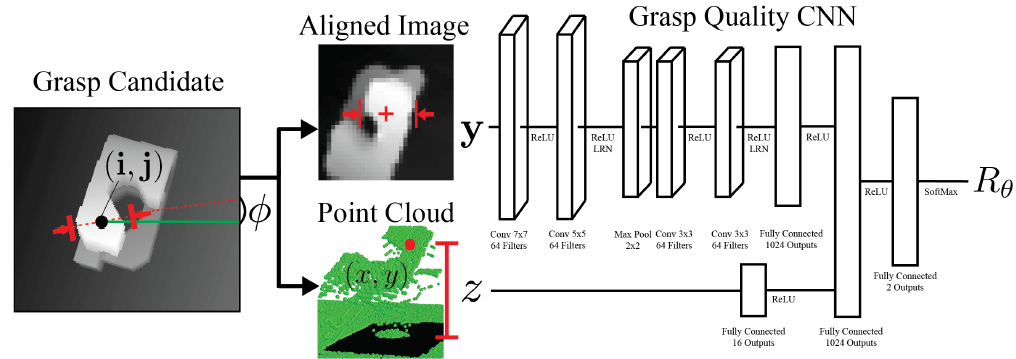
为了完成两个阶段的衔接,输入神经网络的数据就不能是传统的深度图,而是以抓取点为中心,抓取方向水平的一个深度图像块,下面详细介绍:
经过第一阶段,得到了很多个(x,y,theta)。既然是评估每个(x,y,theta)的质量,就必须把(x,y,theta)和深度图像都做为网络的输入,那么以何种方式输入呢?作者给的方案是:以抓取点(x,y)为中心,将深度图像旋转theta角,使抓取方向与图像的水平轴平行,然后以抓取点(x,y)为中心,切出一块32*32大小的深度图块,将这个深度图块输入网络,除此之外,还将抓取点(x,y)相对于桌面的高度z作为另一个输入。如下图。
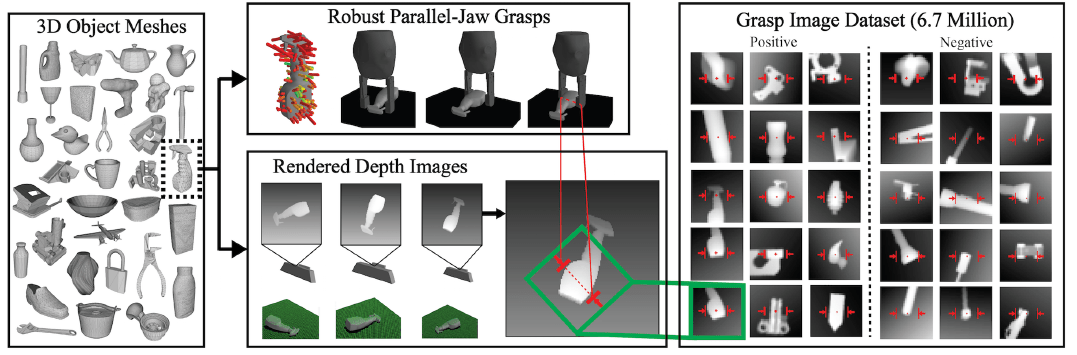
采集数据集
从Dex-Net1.0中筛选了1500个3D物体模型(Dex-Net1.0是一个3D物体模型及抓取数据集),对其中的每个物体,采取同样的操作:将物体随机放在虚拟桌子上,获取当前状态下的垂直抓取表示即(x,y,theta)(可从Dex-Net1.0的标注中直接生成),这些抓取有些是可以用于实际抓取的,有些无法用于抓取。然后使用虚拟深度相机拍摄深度图,然后对每个抓取表示执行和2.1网络输入同样的操作,就得到了670万个正负样本,如下图: