CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Going Denser with Open-Vocabulary Part Segmenta

标题:通过开放式词汇部分分割变得更密集
作者:Peize Sun, Shoufa Chen, Chenchen Zhu, Fanyi Xiao, Ping Luo, Saining Xie, Zhicheng Yan
文章链接:https://rl-at-scale.github.io/assets/rl_at_scale.pdf
项目代码:https://rl-at-scale.github.io/




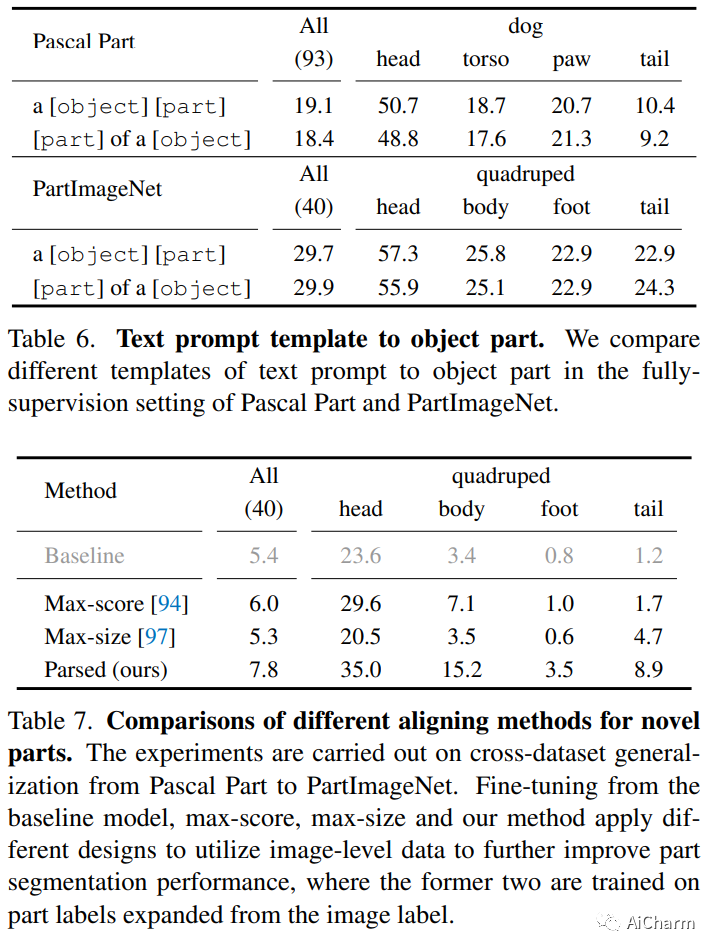
摘要:
对象检测已经从有限的类别扩展到开放的词汇。展望未来,一个完整的智能视觉系统需要理解更细粒度的对象描述、对象部分。在本文中,我们提出了一种能够预测开放词汇对象及其部分分割的检测器。这种能力来自两种设计。首先,我们在部分级、对象级和图像级数据的联合上训练检测器,以构建语言和图像之间的多粒度对齐。其次,我们通过与基础对象的密集语义对应将新对象解析成它的部分。这两种设计使检测器能够在很大程度上受益于各种数据源和基础模型。在开放词汇部分分割实验中,我们的方法在 PartImageNet 的跨数据集泛化中优于基线 3.3 ∼ 7.3 mAP,在跨类别泛化中将基线提高 7.3 novel AP 50 在帕斯卡部分。最后,我们训练了一个检测器,它可以泛化到范围广泛的部分分割数据集,同时实现比特定于数据集的训练更好的性能。
2.CLAPSpeech: Learning Prosody from Text Context with Contrastive Language-Audio Pre-training(ACL 2023)

标题:CLAPSpeech:通过对比语言-音频预训练从文本上下文中学习韵律
作者:Zhenhui Ye, Rongjie Huang, Yi Ren, Ziyue Jiang, Jinglin Liu, Jinzheng He, Xiang Yin, Zhou Zhao
文章链接:https://arxiv.org/abs/2305.10763
项目代码:https://clapspeech.github.io/




摘要:
改进文本表示已经引起了很多关注,以实现富有表现力的文本到语音(TTS)。然而,现有作品仅通过掩码标记重建任务隐式学习韵律,导致训练效率低下且韵律建模困难。我们提出了 CLAPSpeech,这是一种跨模态对比预训练框架,可显式学习不同上下文下相同文本标记的韵律差异。具体来说,1)我们鼓励模型通过编码器输入和对比损失的精心设计,在联合多模态空间中将文本上下文与其相应的韵律模式联系起来;2) 我们引入了多尺度预训练管道来捕获多个级别的韵律模式。我们展示了如何将 CLAPSpeech 整合到现有的 TTS 模型中以获得更好的韵律。在三个数据集上的实验不仅表明 CLAPSpeech 可以改进现有 TTS 方法的韵律预测,而且还展示了其适应多种语言和多说话人 TTS 的泛化能力。我们还深入分析了 CLAPSpeech 性能背后的原理。消融研究证明了我们方法中每个组件的必要性。此 https URL 提供源代码和音频样本。
3.OpenShape: Scaling Up 3D Shape Representation Towards Open-World Understanding

标题:OpenShape:将 3D 形状表示放大以实现对开放世界的理解
作者:Minghua Liu, Ruoxi Shi, Kaiming Kuang, Yinhao Zhu, Xuanlin Li, Shizhong Han, Hong Cai, Fatih Porikli, Hao Su
文章链接:https://arxiv.org/abs/2305.10764
项目代码:https://colin97.github.io/OpenShape/






摘要:
我们介绍了 OpenShape,一种用于学习文本、图像和点云的多模态联合表示的方法。我们采用常用的多模态对比学习框架来进行表示对齐,但特别关注放大 3D 表示以实现开放世界 3D 形状理解。为实现这一目标,我们通过集成多个 3D 数据集来扩大训练数据,并提出了几种策略来自动过滤和丰富嘈杂的文本描述。我们还探索和比较了扩展 3D 骨干网络的策略,并引入了一种新的 hard negative 挖掘模块,以实现更高效的训练。我们在零样本 3D 分类基准上评估 OpenShape,并展示其在开放世界识别方面的卓越能力。具体而言,OpenShape 在 1,156 类 Objaverse-LVIS 基准测试中实现了 46.8% 的零样本准确率,而现有方法的准确率不到 10%。OpenShape 在 ModelNet40 上的准确率也达到了 85.3%,比之前的零样本基线方法高出 20%,与一些全监督方法的表现相当。此外,我们展示了我们学习到的嵌入编码了广泛的视觉和语义概念(例如,子类别、颜色、形状、样式),并促进了细粒度的文本 3D 和图像 3D 交互。由于它们与 CLIP 嵌入对齐,我们学习的形状表示也可以与现成的基于 CLIP 的模型集成,用于各种应用,例如点云字幕和点云条件图像生成。
更多Ai资讯:公主号AiCharm